MongoDB 分片管理
在MongoDB(版本 3.2.9)中,分片集群(sharded cluster)是一种水平扩展数据库系统性能的方法,能够将数据集分布式存储在不同的分片(shard)上,每个分片只保存数据集的一部分,MongoDB保证各个分片之间不会有重复的数据,所有分片保存的数据之和就是完整的数据集。分片集群将数据集分布式存储,能够将负载分摊到多个分片上,每个分片只负责读写一部分数据,充分利用了各个shard的系统资源,提高数据库系统的吞吐量。
数据集被拆分成数据块(chunk),每个数据块包含多个doc,数据块分布式存储在分片集群中。MongoDB负责追踪数据块在shard上的分布信息,每个分片存储哪些数据块,叫做分片的元数据,保存在config server上的数据库 config中,一般使用3台config server,所有config server中的config数据库必须完全相同。通过mongos能够直接访问数据库config,查看分片的元数据;mongo shell 提供 sh 辅助函数,能够安全地查看分片集群的元数据信息。
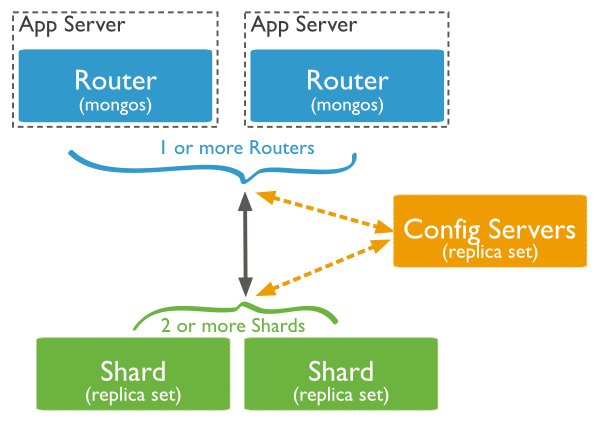
对任何一个shard进行查询,只会获取collection在当前分片上的数据子集,不是整个数据集。Application 只需要连接到mongos,对其进行的读写操作,mongos自动将读写请求路由到相应的shard。MongoDB通过mongos将分片的底层实现对Application透明,在Application看来,访问的是整个数据集。
一,主分片
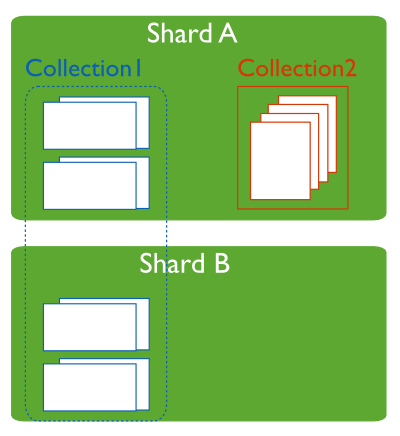
在分片集群中,不是每个集合都会分布式存储,只有使用sh.shardCollection()显式将collection分片后,该集合才会分布式存储在不同的shard中。对于非分片集合(un-sharded collection),其数据只会存储在主分片(Primary shard)中,默认情况下,主分片是指数据库最初创建的shard,用于存储该数据库中非分片集合的数据。每个数据库都有一个主分片。
Each database in a sharded cluster has a primary shard that holds all the un-sharded collections for that database. Each database has its own primary shard.
例如,一个分片集群有三个分片:shard1,shard2,shard3,在分片shard1创建一个数据库blog。如果将数据库bolg分片,那么MongoDB会自动在shard2,shard3上创建一个结构相同的数据库blog,数据库blog的Primary Shard是Shard1。
图示,Collection2的主分片是ShardA。
使用 movePrimary命令变更数据库默认的Primary shard,非分片集合将会从当前shard移动到新的主分片。
db.runCommand( { movePrimary : "test", to : "shard0001" } )
在使用movePrimary命令变更数据库的主分片之后,config server中的配置信息是最新的,mongos缓存的配置信息变得过时了。MongoDB提供命令:flushRouterConfig 强制mongos从config server获取最新的配置信息,刷新mongos的缓存。
db.adminCommand({"flushRouterConfig":1})
二,分片的元数据
不要直接到config server上查看分片集群的元数据信息,这些数据非常重要,安全的方式是通过mongos连接到config数据查看,或者使用sh辅助函数查看。
使用sh辅助函数查看
sh.status()
连接到mongos查看config数据库中的集合
mongos> use config
1,shards 集合保存分片信息
db.shards.find()
shard的数据存储在host指定的 replica set 或 standalone mongod中。
{
"_id" : "shard_name",
"host" : "replica_set_name/host:port",
"tag":[shard_tag1,shard_tag2]
}
2,databases集合保存分片集群中所有数据库的信息,不管数据库是否分片
db.databases.find()
如果在数据库上执行sh.enableSharding("db_name"),那么字段partitioned字段值就是true;primary 字段指定数据库的主分片(primary shard)。
{
"_id" : "test",
"primary" : "rs0",
"partitioned" : true
}
3,collections集合保存所有已分片集合的信息,不包括非分片集合(un-sharded collections)
key是:分片的片键
db.collections.find()
{
"_id" : "test.foo",
"lastmodEpoch" : ObjectId("57dcd4899bd7f7111ec15f16"),
"lastmod" : ISODate("1970-02-19T17:02:47.296Z"),
"dropped" : false,
"key" : {
"_id" : 1
},
"unique" : true
}
4,chunks 集合保存数据块信息,
ns:分片的集合,结构是:db_name.collection_name
min 和 max: 片键的最小值和最大值
shard:块所在的分片
db.chunks.find()
{
"_id" : "test.foo-_id_MinKey",
"lastmod" : Timestamp(1, 1),
"lastmodEpoch" : ObjectId("57dcd4899bd7f7111ec15f16"),
"ns" : "test.foo",
"min" : {
"_id" : 1
},
"max" : {
"_id" : 3087
},
"shard" : "rs0"
}
5,changelog集合记录分片集群的操作,包括chunk的拆分和迁移操作,Shard的增加或删除操作
what 字段:表示操作的类型,例如:multi-split表示chunk的拆分,
"what" : "addShard",
"what" : "shardCollection.start",
"what" : "shardCollection.end",
"what" : "multi-split",
6,tags 记录shard的tag和对应的片键范围
{
"_id" : { "ns" : "records.users", "min" : { "zipcode" : "10001" } },
"ns" : "records.users",
"min" : { "zipcode" : "10001" },
"max" : { "zipcode" : "10281" },
"tag" : "NYC"
}
7,settings 集合记录均衡器状态和chunk的大小,默认的chunk size是64MB。
{ "_id" : "chunksize", "value" : 64 }
{ "_id" : "balancer", "stopped" : false }
8,locks 集合记录分布锁(distributed lock),保证只有一个mongos 实例能够在分片集群中执行管理任务。
mongos在担任balancer时,会获取一个分布锁,并向config.locks中插入一条doc。
The locks collection stores a distributed lock. This ensures that only one mongos instance can perform administrative tasks on the cluster at once. The mongos acting as balancer takes a lock by inserting a document resembling the following into the locks collection.
{
"_id" : "balancer",
"process" : "example.net:40000:1350402818:16807",
"state" : 2,
"ts" : ObjectId("507daeedf40e1879df62e5f3"),
"when" : ISODate("2012-10-16T19:01:01.593Z"),
"who" : "example.net:40000:1350402818:16807:Balancer:282475249",
"why" : "doing balance round"
}
三,删除分片
删除分片时,必须确保该分片上的数据被移动到其他分片中,对于以分片的集合,使用均衡器来迁移数据块,对于非分片的集合,必须修改集合的主分片。
1,删除已分片的集合数据
step1,保证均衡器是开启的
sh.setBalancerState(true);
step2,将已分片的集合全部迁移到其他分片
use admin
db.adminCommand({"removeShard":"shard_name"})
removeShard命令会将数据块从当前分片上迁移到其他分片上去,如果分片上的数据块比较多,迁移过程可能耗时很长。
step3,检查数据块迁移的状态
use admin
db.runCommand( { removeShard: "shard_name" } )
使用removeShard命令能够查看数据块迁移的状态,remaining 字段表示剩余数据块的数量
{
"msg" : "draining ongoing",
"state" : "ongoing",
"remaining" : {
"chunks" : 42,
"dbs" : 1
},
"ok" : 1
}
step4,数据块完成迁移
use admin
db.runCommand( { removeShard: "shard_name" } ) {
"msg" : "removeshard completed successfully",
"state" : "completed",
"shard" : "shard_name",
"ok" : 1
}
2,删除未分片的数据库
step1,查看未分片的数据库
未分片的数据库,包括两部分:
- 数据库未被分片,该数据没有使用sh.enableSharding("db_name"),在数据库config中,该数据库的partitioned字段是false
- 数据库中存在collection未被分片,即当前的分片是该集合的主分片
use config
db.databases.find({$or:[{"partitioned":false},{"primary":"shard_name"}]})
对于partitioned=false的数据库,其数据全部保存在当前shard中;对于partitioned=true,primary=”shard_name“的数据库,表示存在未分片(un-sharded collection)存储在该数据库中,必须变更这些集合的主分片。
step2,修改数据库的主分片
db.runCommand( { movePrimary: "db_name", to: "new_shard" })
四,增加分片
由于分片存储的是数据集的一部分,为了保证数据的高可用性,推荐使用Replica Set作为shard,即使Replica Set中只包含一个成员。连接到mongos,使用sh辅助函数增加分片。
sh.addShard("replica_set_name/host:port")
不推荐将standalone mongod作为shard
sh.addShard("host:port")
五,特大块
在有些情况下,chunk会持续增长,超出chunk size的限制,成为特大块(jumbo chunk),出现特大块的原因是chunk中的所有doc使用同一个片键(shard key),导致MongoDB无法拆分该chunk,如果该chunk持续增长,将会导致chunk的分布不均匀,成为性能瓶颈。
在chunk迁移时,存在限制:每个chunk的大小不能超过2.5万条doc,或者1.3倍于配置值。chunk size默认的配置值是64MB,超过限制的chunk会被MongoDB标记为特大块(jumbo chunk),MongoDB不能将特大块迁移到其他shard上。
MongoDB cannot move a chunk if the number of documents in the chunk exceeds either 250000 documents or 1.3 times the result of dividing the configured chunk size by the average document size.
1,查看特大块
使用sh.status(),能够发现特大块,特大块的后面存在 jumbo 标志
{ "x" : 2 } -->> { "x" : 3 } on : shard-a Timestamp(2, 2) jumbo
2,分发特大块
特大块不能拆分,不能通过均衡器自动分发,必须手动分发。
step1,关闭均衡器
sh.setBalancerState(false)
step2,增大Chunk Size的配置值
由于MongoDB不允许移动大小超出限制的特大块,因此,必须临时增加chunk size的配置值,再将特大块均衡地分发到分片集群中。
use config
db.settings.save({"_id":"chunksize","value":"1024"})
step3,移动特大块
sh.moveChunk("db_name.collection_name",{sharded_filed:"value_in_chunk"},"new_shard_name")
step4,启用均衡器
sh.setBalancerState(true)
step5,刷新mongos的配置缓存
强制mongos从config server同步配置信息,并刷新缓存。
use admin
db.adminCommand({ flushRouterConfig: 1 } )
六,均衡器
均衡器是由mongos转变的,就是说,mongos不仅负责将查询路由到相应的shard上,还要负责数据块的均衡。一般情况下,MongoDB会自动处理数据均衡,通过config.settings能够查看balancer的状态,或通过sh辅助函数查看
sh.getBalancerState()
返回true,表示均衡器在正运行,系统自动处理数据均衡,使用sh辅助函数能够关闭balancer
sh.setBalancerState(false)
balancer不能立即终止正在运行的块迁移操作,在mongos转变为balancer时,会申请一个balancer lock,查看config.locks 集合,
use config
db.locks.find({"_id":"balancer"}) --or
sh.isBalancerRunning()
如果state=2,表示balancer正处于活跃状态,如果state=0,表示balancer已被关闭。
均衡过程实际上是将数据块从一个shard迁移到其他shard,或者先将一个大的chunk拆分小的chunk,再将小块迁移到其他shard上,块的迁移和拆分都会增加系统的IO负载,最好将均衡器的活跃时间限制在系统空闲时进行,可以设置balancer的活跃时间窗口,限制balancer在指定的时间区间内进行数据块的拆分和迁移操作。
use config db.settings.update(
{"_id":"balancer"},
"$set":{"activeWindow":{"start":"23:00","stop":"04:00"}}),
true
)
均衡器拆分和移动的对象是chunk,均衡器只保证chunk数量在各个shard上是均衡的,至于每个chunk包含的doc数量,并不一定是均衡的。可能存在一些chunk包含的doc数量很多,而有些chunk包含的doc数量很少,甚至不包含任何doc。因此,应该慎重选择分片的索引键,即片键,如果一个字段既能满足绝大多数查询的需求,又能使doc数量均匀分布,那么该字段是片键的最佳选择。
参考文档:
Sharded Cluster Administration
MongoDB 分片管理的更多相关文章
- MongoDB 分片管理(三)服务器管理
MongoDB 分片管理(三)服务器管理
- MongoDB 分片管理(不定时更新)
背景: 通过上一篇的 MongoDB 分片的原理.搭建.应用 大致了解了MongoDB分片的安装和一些基本的使用情况,现在来说明下如何管理和优化MongoDB分片的使用. 知识点: 1) 分片的配置和 ...
- MongoDB 分片管理(四)数据均衡 -- 特大快
1.1 特大快形成 如果用date字段作为片键,集合中date是一个日期字符串,如:year/month/day,也就是说,mongoDB一天创建一个块.因块内所有文档的片键一样,因此这些块是不可拆分 ...
- MongoDB 分片管理(四)数据均衡
通常来说,MongoDB会自动处理数据均衡. 1.1 集群分片的块的均衡 注意,均衡器只使用块的数量,而非数据大小,来作为衡量分片间是否均衡的指标. 1.2 均衡器 1.执行所有数据库管理操作前,都应 ...
- MongoDB 分片管理(一)检查集群状态
一.检查集群状态 1.1 使用sh.status()查看集群摘要信息 1.使用sh.status()可以查看分片信息.数据库信息.集合信息 sh.status() 如果数据块较多时,使用sh.stat ...
- MongoDB 分片管理(二)查看网络连接
1.1 查看连接统计 connPoolStats,查看mongos与mongod之间的连接信息,并可得知服务器 上打开的所有连接 1.2 限制连接数量
- Mongodb 笔记07 分片、配置分片、选择片键、分片管理
分片 1. 分片(sharding)是指将数据拆分,将其分散存放在不同的机器上的过程.有时也用分区(partitioning)来表示这个概念.将数据分散到不同的机器上,不需要功能强大的大型计算机就可以 ...
- MongoDB分片 在部署和维护管理 中常见事项的总结
分片(sharding)是MongoDB将大型集合分割到不同服务器(或者说集群)上所采用的方法,主要为应对高吞吐量与大数据量的应用场景提供了方法. 和既有的分库分表.分区方案相比,MongoDB的最大 ...
- (转)MongoDB分片实战 集群搭建
环境准备 Linux环境 主机 OS 备注 192.168.32.13 CentOS6.3 64位 普通PC 192.168.71.43 CentOS6.2 64位 服务器,NUMA CPU架构 Mo ...
随机推荐
- VIew-CoordinatorLayout 笔记
CoordinatorLayout 协调者:一般会是两个控件,一个Dependency一个child ,CoordinatorLayout的主要功能就是协调这两个控件,使child跟随Dependen ...
- 搜索技巧<转>
平时工作,搜索引擎是少不了的,作为程序员,当然首推 Google.这里简单介绍下几个 Google 搜索的小技巧,方便别人也方便自己查阅. ps:以下所有操作,均可以在 「谷歌搜索首页 -> 设 ...
- T-SQL Recipes之Common Function
在我们写SQL的时候,经常会用到许多内置方法,简化了我们许多代码,也提高了效率,这篇主要总结一些常用的方法. ISNULL VS COALESCE VS NULLIF 在SQL中,NULL值是比较特殊 ...
- 【BZOJ】4001: [TJOI2015]概率论
题意 求节点数为\(n\)的有根树期望的叶子结点数.(\(n \le 10^9\)) 分析 神题就打表找规律.. 题解 方案数就是卡特兰数,$h_0=1, h_n = \sum_{i=0}^{n-1} ...
- JavaScript笔试必备语句【转】
1. document.write( " "); 输出语句 2.JS中的注释为// 3.传统的HTML文档顺序是:document- >html- >(head,bod ...
- 关于Linux系统下错误“浮点数异常(核心已转储)”的分析
1.问题发现 有这样一段代码: #include <stdio.h> int main() { int a, b, num1, num2, temp; printf("pleas ...
- 【转贴】Python处理海量数据的实战研究
最近看了July的一些关于Java处理海量数据的问题研究,深有感触,链接:http://blog.csdn.net/v_july_v/article/details/6685962 感谢July ^_ ...
- Windows下ADT环境搭建
1.JDK安装 下载JDK(点我下载),安装成功后在我的电脑->属性->高级->环境变量->系统变量中添加以下环境变量: JAVA_HOME值为C:\Program Files ...
- webform 组合查询
界面: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.aspx ...
- Xamarin的不归路-生成安卓错误3
错误提示: 解决方案:升级jdk到8即可. 2016年9月1日14:50