Hadoop- MR的shuffle过程
step1 input
InputFormat读取数据,将数据转换成<key ,value>对,设置FileInputFormat,默认是文本格式(TextInputFormat)
step2 map
map<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 默认情况下KEYIN:LongWritable,偏移量。VALUEIN:Text,KEYOUT与VALUEOUT要根据我们的具体的业务来定。
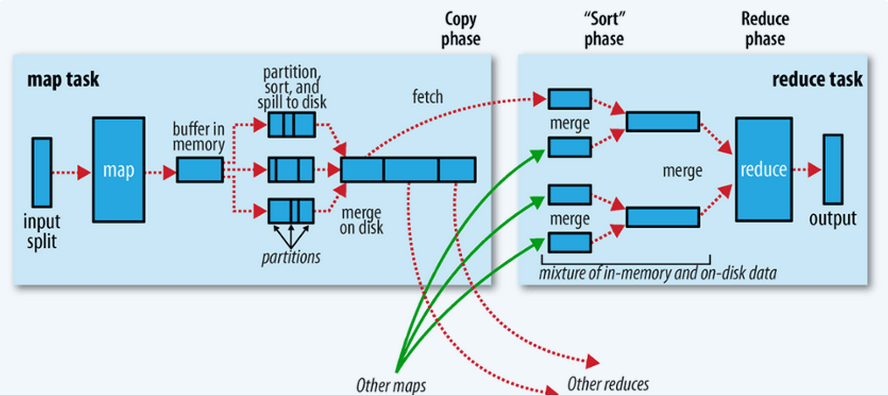
step3 shuffle
map输出到reduce之前这个阶段是mr的shuffle阶段。
map输出的<key , value>对首先放在内存中,当达到一定的内存大小,就会溢写(spill)到本地磁盘中,可能有很多文件。spill过程有两个操作,分区(partition)和排序(sort)。当map task结束后可能有很多的小文件,spill。那么我们需要对这些文件合并(merge),排序成一个大文件。此时map阶段才结束。
Reduce task 会到Map Task运行的机器上,拷贝要处理的数据。然后合并(merge),排序,分组(group)将相同key 的value 放在一起,完成了reduce 数据输入的过程。
step4 reduce
reduce<KEYIN, VALUEIN, KEYOUT, VALUEOUT>,map输出的<key , value>数据类型与reduce输入<key , value>的数据类型一致。
接下来就是执行Reducer 定义的方法了
step5 output
TextOutputFormat
最后将结果输出到文件系统上,每个< key , value >对, key与value中间分隔符为\t,默认调用 key 和 value 的 toString() 方法。
我们可以在map端输出文件压缩,可设置,combiner(map端的reduce)。
Hadoop- MR的shuffle过程的更多相关文章
- Hadoop学习之shuffle过程
转自:http://langyu.iteye.com/blog/992916,多谢分享,学习Hadopp性能调优的可以多关注一下 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方, ...
- Hadoop MapReduce的Shuffle过程
一.概述 理解Hadoop的Shuffle过程是一个大数据工程师必须的,笔者自己将学习笔记记录下来,以便以后方便复习查看. 二. MapReduce确保每个reducer的输入都是按键排序的.系统执行 ...
- Hadoop Mapreduce的shuffle过程详解
1.map task读取数据时默认调用TextInputFormat的成员RecoreReader,RecoreReader调用自己的read()方法,进行逐行读取,返回一个key.value; 2. ...
- Hadoop学习笔记—10.Shuffle过程那点事儿
一.回顾Reduce阶段三大步骤 在第四篇博文<初识MapReduce>中,我们认识了MapReduce的八大步骤,其中在Reduce阶段总共三个步骤,如下图所示: 其中,Step2.1就 ...
- Shuffle过程
Shuffle过程 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整 ...
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
- 剖析Hadoop和Spark的Shuffle过程差异
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- 剖析Hadoop和Spark的Shuffle过程差异(一)
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- Hadoop计算中的Shuffle过程(转)
Hadoop计算中的Shuffle过程 作者:左坚 来源:清华万博 时间:2013-07-02 15:04:44.0 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解Ma ...
- hadoop的shuffle过程
1. shuffle: 洗牌.发牌——(核心机制:数据分区,排序,缓存): shuffle具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key ...
随机推荐
- spring+springMVC+hibernate整合
首先我们要知道hibernate五大对象:,本实例通过深入的使用这五大对象和spring+springMVC相互结合,体会到框架的好处,提高我们的开发效率 Hibernate有五大核心接口,分别是:S ...
- NGINX不允许向静态文件提交POST方式的请求,否则报405错误(apache中没有出现)
telnet *.*.*.* 80POST /map/navigation/2011winter/jsn/jsn_20120723_pack/pvf.jsnHTTP/1.1Host:*.*.*.* ( ...
- 产生n个数全排列的算法
给定n个数{1...n},如何给出这n个数的全排列呢? 给定一个整数k,我们给它一个向左或向右的方向,k(->)或者k(<-),我们说k是可以移动的,如果它的方向指向一个相邻的比它小的数, ...
- 【Mac系统】之破解Navicat Premium for Mac(中文版)
前期准备工作: 下载Mac中文版本: 下载地址:链接:https://pan.baidu.com/s/1wShOFK9odsSWBSphgqTdEQ 密码:ipsa 下载完成后进行安装,安装步骤省略 ...
- PMD:Java源代码扫描器
PMD是一个开源代码分析器.可以查找常见编程缺陷,比如未使用的变量.空catch代码块.不必要的对象创建等.支持Java.JavaScript.PLSQL.Apache Velocity.XML.XS ...
- WPF 获取控件模板中的控件
DG是控件名称public T GetVisualChild<T>(DependencyObject parent, Func<T, bool> predicate) wher ...
- 转载 iOS js oc相互调用(JavaScriptCore) --iOS调用js
iOS js oc相互调用(JavaScriptCore) 从iOS7开始 苹果公布了JavaScriptCore.framework 它使得JS与OC的交互更加方便了. 下面我们就简单了解一下这 ...
- ajax 和jsonp 不是一码事 细读详解
由于Sencha Touch 2这种开发模式的特性,基本决定了它原生的数据交互行为几乎只能通过AJAX来实现. 当然了,通过调用强大的PhoneGap插件然后打包,你可以实现100%的Socket通讯 ...
- Manager模块 队列 管道 进程池
Manager模块 作用: 多进程共享变量. Manager的字典类型: 如果value是简单类型,比如int,可以直接赋值给共享变量,并可以后续直接修改 如果value是复杂类型 ,比如list, ...
- WPF 支持集合绑定的控件
WPF 支持集合绑定的控件 ListBox ComboBox ListView DataGrid