Hadoop MapReduce的Shuffle过程
一、概述
理解Hadoop的Shuffle过程是一个大数据工程师必须的,笔者自己将学习笔记记录下来,以便以后方便复习查看。
二、
MapReduce确保每个reducer的输入都是按键排序的。系统执行排序、将map输出作为输入传给reducer的过程称为Shuffle。
2.1 map端
map函数开始产生输出时,利用缓冲的方式写到内存并排序具体分一下几个步骤。
1.map数据分片:把输入数据源进行分片,根据分片来决定有多少个map,每个map任务都有一个环形内存缓冲区用于存储任务输出,默认情况下缓冲区大小为100MB,可通过mapreduce.task.io.sort.mb来调整。
2.map排序:当map缓冲区大小达到阈值时(mapreduce.map.sort.spill.percent),就会将内存的数据溢写到磁盘,根据reducer的来划分成相应的partition,在内存中按键值进行排序,如果有combiner函数,在排序后就会应用,排序后写入分区磁盘文件中。溢写的过程中,map会阻塞直到写磁盘过程完成。每次内存缓冲区到达溢出阈值,就会新建一个溢出文件件,在map写完最后一个输出记录之后,会有几个溢出文件,在任务完成之前溢出文件会被合并成一个已分区且已经排序的输出文件。mapreduce.task.io.sort.factor控制着一次最多能合并多少溜,默认10。mapreduce.map.output.compress进行压缩,提高写磁盘速度。
2.2reduce端
1.reduce复制:reducer通过http得到输出文件的分区,用于文件分区的工作线程数量由任务的mapreduce.shuffle.max.threads属性控制。每个map任务的完成时间不同,在每个任务完成时,reduce任务就开始复制其输出,这就是reduce任务的复制阶段,reduce的复制线程数量mapreduce.reduce.shuffle.parallelcopies决定。
复制详解:如果map输出很小,会被复制到reduce任务JVM的内存,否则输出被复制到磁盘。如果内存缓冲区达到阈值大小(mapreduce.reduce.shuffle.merge.percent)或达到map输出阈值(mapreduce.reduce.merge.inmem.threshold),则合并溢出写到磁盘中,如果指定combiner,则在合并期间运行它。随着磁盘上副本增多,后台线程会将他们合并为更大的,排序的文件。
2.reduce合并排序:这个阶段合并map输出,维持其顺序排序,这是循环进行的,如果有50个map输出,合并因子是10(mapreduce.task.io.sort.factor),合并将进行5次,最后有5个中间文件。
3.reduce:直接把数据输入reduce函数,从而省略了一次磁盘的往返行程。
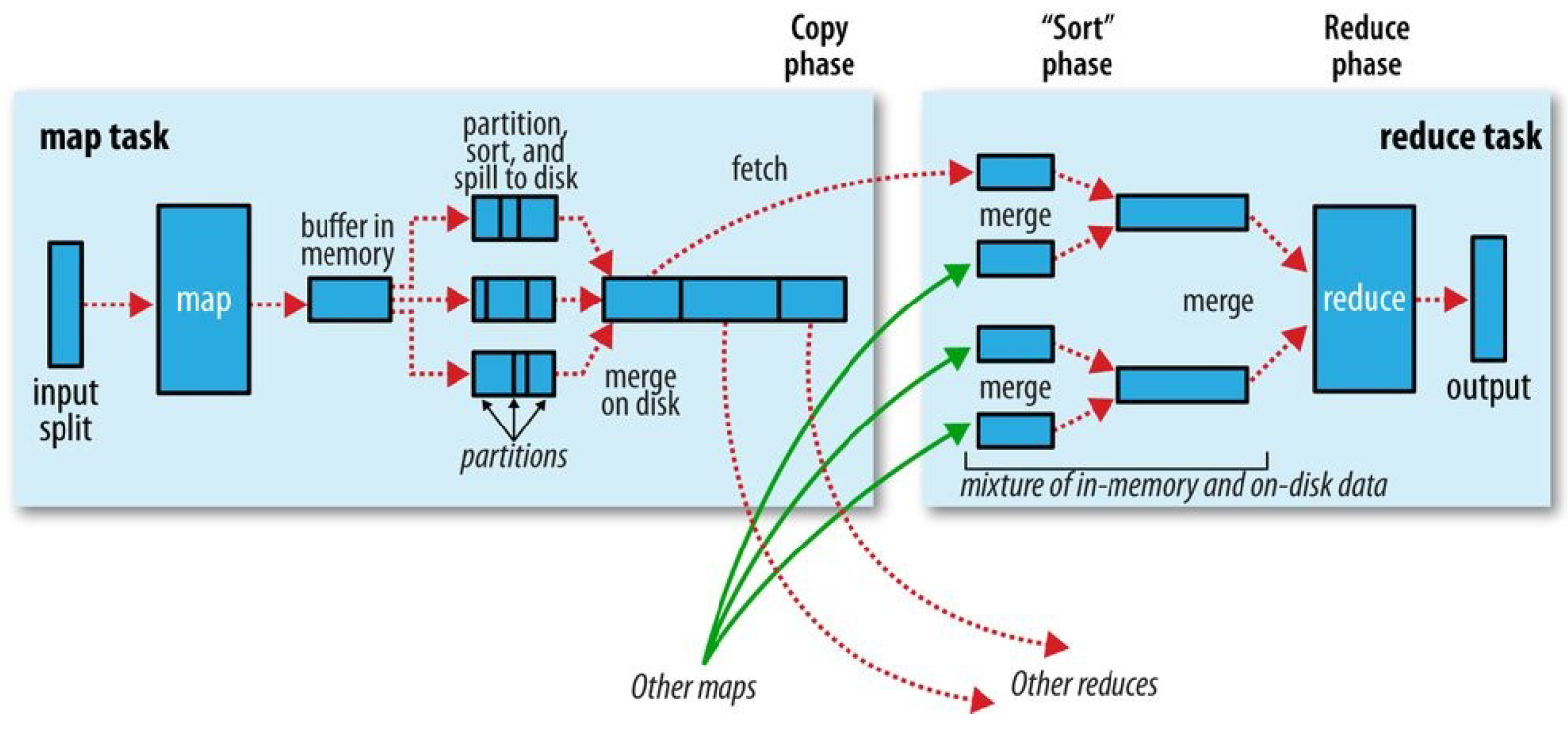
至此mapreduce过程完毕,具体参考Hadoop权威指南第四版。
Hadoop MapReduce的Shuffle过程的更多相关文章
- Hadoop Mapreduce的shuffle过程详解
1.map task读取数据时默认调用TextInputFormat的成员RecoreReader,RecoreReader调用自己的read()方法,进行逐行读取,返回一个key.value; 2. ...
- MapReduce的Shuffle过程介绍
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- Hadoop学习之shuffle过程
转自:http://langyu.iteye.com/blog/992916,多谢分享,学习Hadopp性能调优的可以多关注一下 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方, ...
- MapReduce:Shuffle过程详解
1.Map任务处理 1.1 读取HDFS中的文件.每一行解析成一个<k,v>.每一个键值对调用一次map函数. <0,hello you> & ...
- Hadoop Mapreduce中shuffle 详解
MapReduce 里面的shuffle:描述者数据从map task 输出到reduce task 输入的这段过程 Shuffle 过程: 首先,map 输出的<key,value > ...
- mapReduce的shuffle过程
http://www.jianshu.com/p/c97ff0ab5f49 总结shuffle 过程: map端的shuffle: (1)map端产生数据,放入内存buffer中: (2)buffer ...
- MapReduce 的 shuffle 过程中经历了几次 sort ?
shuffle 是从map产生输出到reduce的消化输入的整个过程. 排序贯穿于Map任务和Reduce任务,是MapReduce非常重要的一环,排序操作属于MapReduce计算框架的默认行为,不 ...
- Hadoop Mapreduce中wordcount 过程解析
将文件split 文件1: 分割结果: hello world ...
- MapReduce的shuffle过程详解
[学习笔记] 结果分析:shuffle的英文是洗牌,混洗的意思,洗牌就是越乱越好的意思.当在集群的情况下是这样的,假如有三个map节点和三个reduce节点,一号reduce节点的数据会来自于三个ma ...
随机推荐
- webpack打包(一)
1.安装webpack打包工具 webpack是使用npm安装 npm install webpack -g //全局安装 在命令行中就可以使用webpack这个命令了. 提示:由于npm安装会去找国 ...
- Hadoop起步之图解SSH、免密登录原理和实现
1. 前言 emmm….最近学习大数据,需要搭建Hadoop框架,当弄好linux系统之后,第一件事就是SSH免密登录的设置.对于SSH,我觉得使用过linux系统的程序员应该并不陌生.可是吧,用起来 ...
- 安装Ruby、多版本Ruby共存、Ruby安装慢问题
rbenv rbenv可以管理多个版本的ruby.可以分为3种范围(或者说不同生效作用域)的版本: local版:本地,针对各项目范围 global版:全局,没有shell和local版时使用glob ...
- [apue] popen/pclose 疑点解惑
问题请看这里: [apue] 使用 popen/pclose 的一点疑问 当时怀疑是pclose关闭了使用完成的管道,因此在pclose之前加一个足够长的sleep,再次观察进程文件列表: 哈哈,这下 ...
- leadcode的Hot100系列--17. 电话号码的字母组合--回溯的另一种想法的应用
提交leetcode的时候遇到了问题,一直说访问越界,但仔仔细细检查n多遍,就是检查不出来. 因为我用到了count全局变量,自加一来表明当前数组访问的位置, 后来突然想到,是不是在leetcode在 ...
- 利用MAT分析JVM内存问题,从入门到精通(二)
上一篇文章MAT入门到精通(一)介绍了MAT的使用场景和基本概念,这篇文章开始介绍MAT的基本功能,后面还有两篇,一篇是MAT的高级功能,另一篇是MAT实战案例分析. 三.欢迎页 使用MAT打开一个h ...
- Class(类)和 继承
ES6的class可以看作只是一个语法糖,它的绝大部分功能,ES5都可以做到,新的class写法只是让对象原型的写法更加清晰.更像面向对象编程的语法而已. //定义类 class Point { co ...
- 不调用free会内存泄露吗?
内存泄露的概念大家可以自行百度下,本文不做阐述.本文要讲的是在程序中分配了内存,但是最后没有使用free()函数来释放这块内存,会导致内存泄露吗?比如有如下代码: #include <stdio ...
- 乘法口诀表(C语言实现)
输出乘法口诀表,关键在于利用好循环语句,而且是二层循环.
- React躬行记(9)——组件通信
根据组件之间的嵌套关系(即层级关系)可分为4种通信方式:父子.兄弟.跨级和无级. 一.父子通信 在React中,数据是自顶向下单向流动的,而父组件通过props向子组件传递需要的信息是组件之间最常见的 ...