Python爬虫之request +re
什么是爬虫?
它是指向网站发起请求,获取资源后分析并提取有用数据的程序;
爬虫的步骤:

1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)文件
废话不多说,直接上代码截图(本文以抓取猫眼网站电影数据为示例):
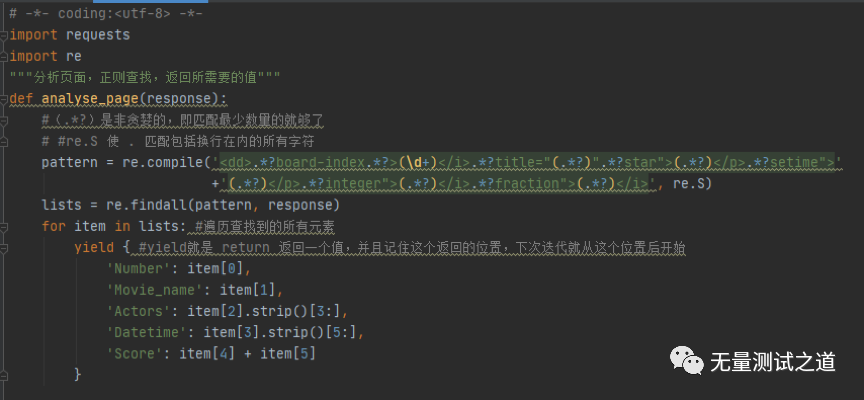
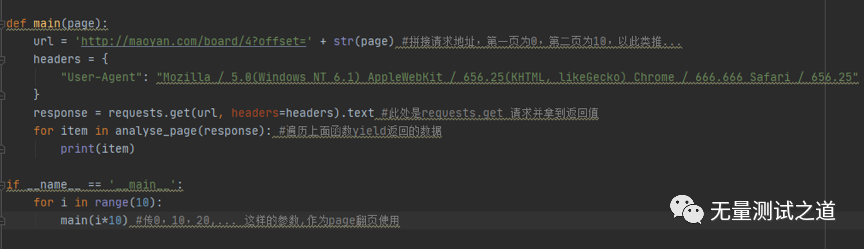
以下是执行后输出的结果:
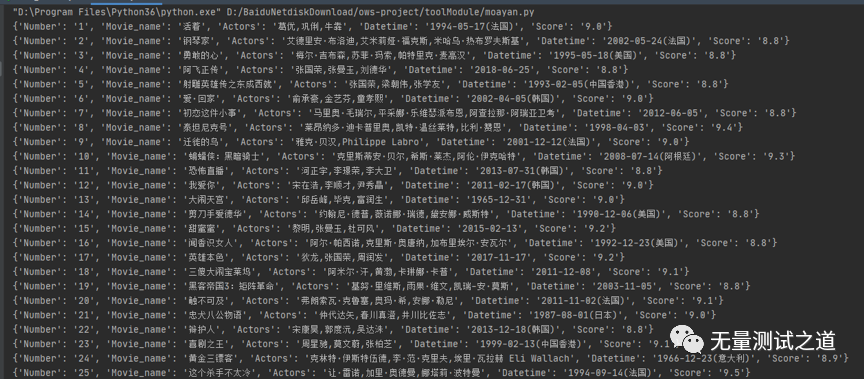
说明:代码截图中有详细的注释信息,所以不在文中再来说明代码中的用法。
备注:我的个人公众号已正式开通,致力于测试技术的分享,包含:大数据测试、功能测试,测试开发,API接口自动化、测试运维、UI自动化测试等,微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,一起共同成长吧。
Python爬虫之request +re的更多相关文章
- python爬虫之request and BeautifulSoup
1.爬虫的本质是什么? 模仿浏览器的行为,爬取网页信息. 2.requests 1.get请求 无参数实例 import requests ret = requests.get('https://gi ...
- Python 爬虫之request+beautifulsoup+mysql
一.什么是爬虫?它是指向网站发起请求,获取资源后分析并提取有用数据的程序:爬虫的步骤: 1.发起请求使用http库向目标站点发起请求,即发送一个RequestRequest包含:请求头.请求体等 2. ...
- Python爬虫实战—— Request对象之header伪装策略
在header当中,我们经常会添加两个参数--cookie 和 User-Agent,来模拟浏览器登录,以此提高绕过后台服务器反爬策略的可能性. User-Agent获取 User-Agent可通过随 ...
- Python爬虫实战——反爬策略之模拟登录【CSDN】
在<Python爬虫实战-- Request对象之header伪装策略>中,我们就已经讲到:=="在header当中,我们经常会添加两个参数--cookie 和 User-Age ...
- python爬虫如何POST request payload形式的请求
python爬虫如何POST request payload形式的请求1. 背景最近在爬取某个站点时,发现在POST数据时,使用的数据格式是request payload,有别于之前常见的 POST数 ...
- (转)python爬虫----(scrapy框架提高(1),自定义Request爬取)
摘要 之前一直使用默认的parse入口,以及SgmlLinkExtractor自动抓取url.但是一般使用的时候都是需要自己写具体的url抓取函数的. python 爬虫 scrapy scrapy提 ...
- Python爬虫连载1-urllib.request和chardet包使用方式
一.参考资料 1.<Python网络数据采集>图灵工业出版社 2.<精通Python爬虫框架Scrapy>人民邮电出版社 3.[Scrapy官方教程](http://scrap ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
随机推荐
- c#word文档输出
在工作中有时需要把内容用word文档展示出来 在写代码前要引用word的dll Microsoft.Office.Interop.Word“ sing System; using System.Col ...
- python Lambda, filter, reduce and map
1. lambda The lambda operator or lambda function is a way to create small anonymous functions , i.e. ...
- 百度智能云平台调用食物识别api Java实现
纪录一下我小学期2天花了20小时写的菜品识别java程序. 1.2. 百度智能云简介 1.2.1 百度图像识别服务 百度图像识别服务,基于深度学习及大规模图像训练,准确识别图片中的物体类别.位置.置信 ...
- Java Web项目部署到阿里云服务器(ECS)
本篇随笔只是记录博主第一次将自己的Java项目部署到阿里云服务器的大致过程,具体细节还请参考别的博文. 一.项目介绍 我做的项目是利用maven项目构建工具进行搭建基于SSM框架的代码共享管理系统,主 ...
- myeclipse快捷键代码
复制来源百度文库http://wenku.baidu.com/link?url=2DLLTMdq4q_ZrK1Zqg34ElzDePSLC3qfKxi7P2et7NO-g7JErrYS4Dl8dbtR ...
- Redis学习笔记(十三) 复制(下)
上一篇写了Redis复制功能的简单应用,下面我们看下Redis复制功能的实现过程.下面基本上是理论部分,枯燥乏味,但希望大家能看看,毕竟知识不都是感兴趣的.耐得住寂寞,经得起诱惑,方能守得住繁华 ~. ...
- 201771010120 苏浪浪 《面向对象程序设计(java)》第11周学习总结
实验十一 集合 1.实验目的与要求 (1) 掌握Vetor.Stack.Hashtable三个类的用途及常用API: (2) 了解java集合框架体系组成: (3) 掌握ArrayList.Lin ...
- bzoj1497最大闭权图基础题
1497: [NOI2006]最大获利 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 5485 Solved: 2661[Submit][Status] ...
- CF948B Primal Sport
题目链接:http://codeforces.com/contest/948/problem/B 知识点: 素数 解题思路: \(f(x)\) 表示 \(x\) 的最大素因子.不难想到:\(X_1 \ ...
- POJ1984
题目链接:https://vjudge.net/problem/POJ-1984 解题思路:并查集+离线操作. 用dx[ ]和dy[ ]两个数组存储某点相对于该点所在集合的源头的方位,因此不难推知dx ...