SQL实战(三)
一、
查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_noy以及其对应的薪水涨幅growth,并按照growth进行升序
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
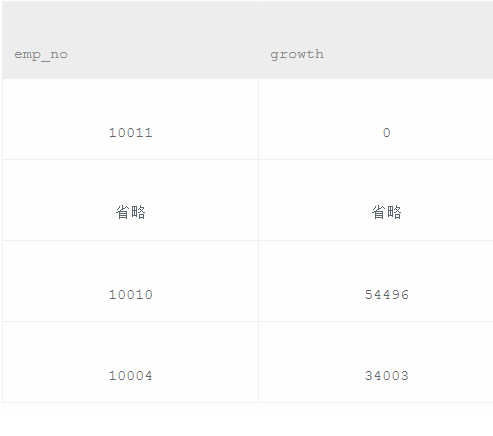

employees 中tem_no和salaries中tem_no插入,然后找最大最小,求值
1、
select sCurrent.emp_no,(sCurrent.salary-sStart.salary) as growth
from (select e.emp_no,s.salary from employees as e,salaries as s where e.emp_no=s.emp_no and s.to_date="9999-01-01") as sCurrent --找到当前薪水
join (select e.emp_no,s.salary from employees as e,salaries as s where e.emp_no=s.emp_no and s.from_date=e.hire_date) as sStart --找到初始入职薪水
on sCurrent.emp_no=sStart.emp_no --合并表,相减
order by growth
生成新表,两个新表连接后再减,而不能在一个表里多次跨行减。
2、
更好理解
select a.emp_no,(b.salary-c.salary) as growth
from employees as a --往该表添加
join salaries as b on a.emp_no=b.emp_no and b.to_date="9999-01-01" --加入当前薪水
join salaries as c on a.emp_no=c.emp_no and c.from_date=a.hire_date --加入最初薪水
order by growth
二、
题目描述
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));

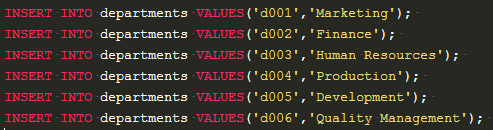
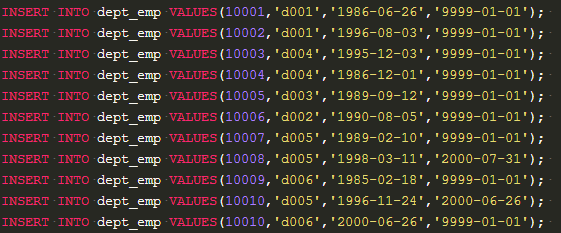

1、departments 连接dept_emp ,然后再连接 salaries ,group by 分组,统计个数
select a.dept_no,a.dept_name,count(a.dept_no)
from departments as a
join dept_emp as b on a.dept_no=b.dept_no
join salaries as c on b.emp_no=c.emp_no
group by a.dept_no
2、思路一样,换用from where 表示
select d.dept_no,d.dept_name,count(d.dept_no) as sum
from (select * from departments as a,dept_emp as b where a.dept_no=b.dept_no)as d,salaries as c
where d.emp_no=c.emp_no
group by d.dept_no
三、
对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
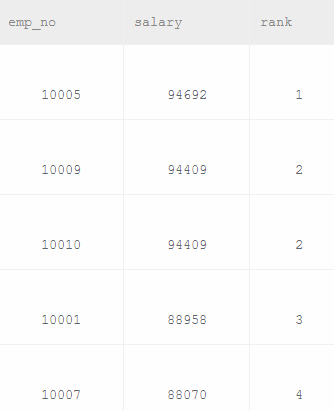
1、题有点难度
SELECT s1.emp_no, s1.salary, COUNT(DISTINCT s2.salary) AS rank FROM salaries AS s1, salaries AS s2 WHERE s1.to_date = '9999-01-01' AND s2.to_date = '9999-01-01' AND s1.salary <= s2.salary GROUP BY s1.emp_no ORDER BY s1.salary DESC, s1.emp_no ASC
思路如下

学会where语句中判断语句 的应用
两个条件下排序的应用。
三、
题目描述
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
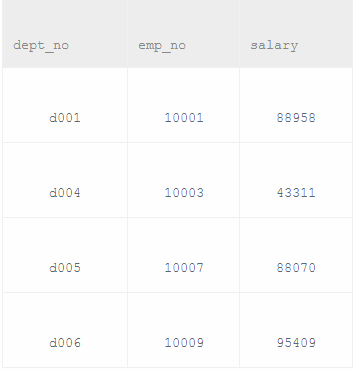
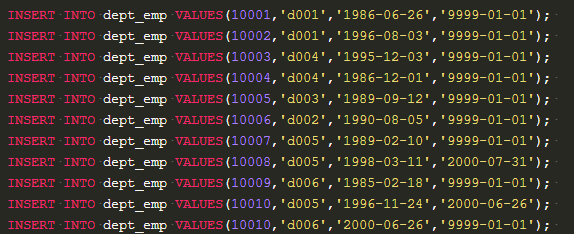
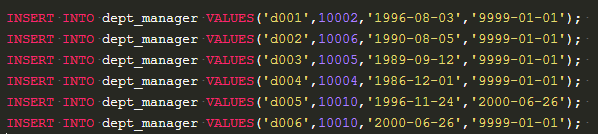
11个人6个部门,10008和10011离职。
从dept_manager中找出部门对应的经理,从dept_emp中找出部门对应的员工,从salaries找出薪资,关键是如何从员工中剔除经理。
1、
SELECT de.dept_no, s.emp_no, s.salary
FROM (employees AS e INNER JOIN salaries AS s ON s.emp_no = e.emp_no AND s.to_date = '9999-01-01')--每个人的当前薪资
INNER JOIN dept_emp AS de ON e.emp_no = de.emp_no --所有员工待的部门
WHERE de.emp_no NOT IN (SELECT emp_no FROM dept_manager WHERE to_date = '9999-01-01') --构建经理的集合,not in 集合的输出
from...join...as A 。这里A是连接后表的名称。
not in 后一定跟着一个表而非一个数。
2、不用employees表
select a.dept_no,b.emp_no,b.salary
from dept_emp as a join salaries as b
on a.emp_no=b.emp_no and b.to_date="9999-01-01" --员工当前薪水
where a.emp_no not in (select emp_no from dept_manager where dept_manager.to_date="9999-01-01")
3、
select de.dept_no,de.emp_no,(select salary from salaries where emp_no=de.emp_no and to_date='9999-01-01') as salary
from dept_emp de left join dept_manager dm
on de.emp_no=dm.emp_no
where de.to_date='9999-01-01' and dm.emp_no is null;
利用左连接求差集,没有经理的会出现null 。由此判断
还有一点,是 (select salary from salaries where emp_no=de.emp_no and to_date='9999-01-01'),输出位置这样也可以。
四、
获取员工其当前的薪水比其manager当前薪水还高的相关信息,当前表示to_date='9999-01-01',
结果第一列给出员工的emp_no,
第二列给出其manager的manager_no,
第三列给出该员工当前的薪水emp_salary,
第四列给该员工对应的manager当前的薪水manager_salary
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));

具体数据见上题
1、

select a.emp_no as emp_no,b.emp_no as manager_no,a.salary as emp_salary,b.salary as manager_salary
from (dept_emp as de join salaries as s on de.emp_no=s.emp_no and s.to_date="9999-01-01") as a --所有员工薪资表a,
join (dept_manager as dp join salaries as s on dp.emp_no=s.emp_no and s.to_date="9999-01-01") as b --经理薪资表 b,
on de.dept_no=dp.dept_no and dp.to_date="9999-01-01" and a.salary>b.salary --a和b 按条件连接
五、
题目描述
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE IF NOT EXISTS "titles" (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);
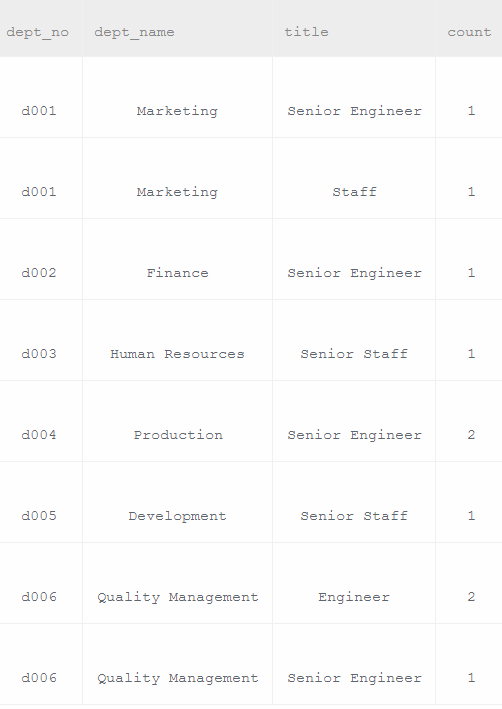


1、首先department 和dept_emp 用join连接,可以得到部门里的员工,
再和title join连接,得到每个员工的职称
按照部门分类,再按职称分类,统计各个职称的个数
核心是group by可以按照顺序对两个条件分类的使用。
select a.dept_no,a.dept_name,t.title,count(t.title) from (departments as dp join dept_emp as de on de.dept_no=dp.dept_no and de.to_date="9999-01-01") as a join titles as t on a.emp_no=t.emp_no and t.to_date="9999-01-01" group by a.dept_no,t.title
六、
给出每个员工每年薪水涨幅超过5000的员工编号emp_no、薪水变更开始日期from_date以及薪水涨幅值salary_growth,并按照salary_growth逆序排列。
提示:在sqlite中获取datetime时间对应的年份函数为strftime('%Y', to_date)
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
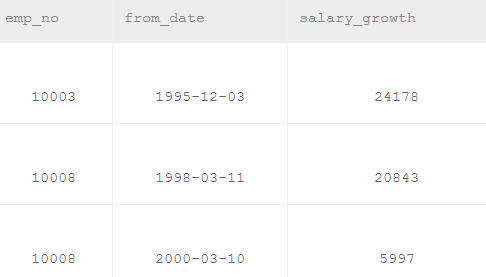
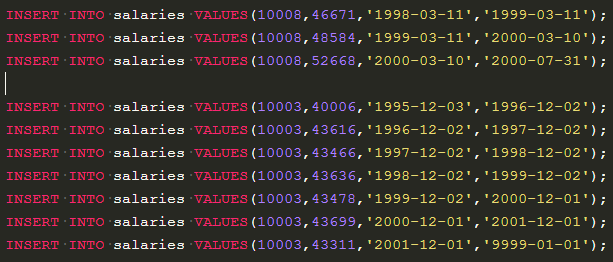

select s1.emp_no,s1.from_date,(s1.salary-s2.salary) as salary_growth
from salaries as s1,salaries as s2
where s1.emp_no=s2.emp_no and salary_growth>5000
and((strftime('%Y',s1.from_date)-strftime('%Y',s2.from_date)=1) or (strftime('%Y',s1.to_date)-strftime('%Y',s2.to_date)=1))--and中嵌套or的条件判断
order by salary_growth desc
七、
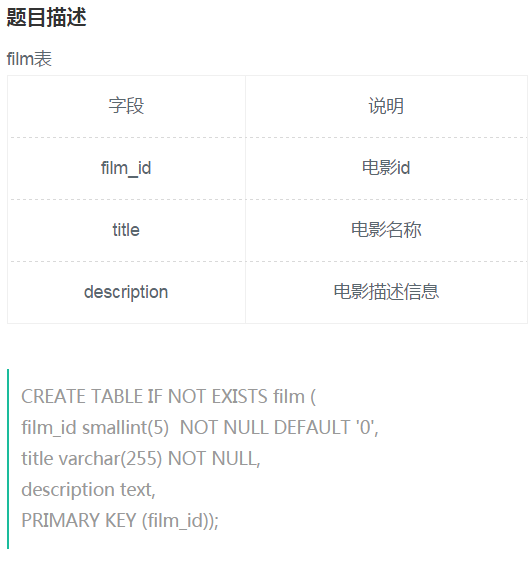


1、
注意该分类电影数量》=5,是所有的电影,而不是仅仅只包含robot的电影
思路:找到robot的电影,找到电影的分类,找到该分类的名称,比较该分类是否在大于5的范围内。
正则表达式来判断robot的存在。
select name,count(name)
from film,film_category,category
where film.description like '%robot%' --找到含有robot 电影
and film.film_id= film_category.film_id and --找到电影的分类
film_category.category_id= category.category_id --找到分类名
and category.category_id in
(select category_id from film_category group by category_id having count(film_id)>=5)--分类大于5,不考虑是否有robot
join 方式
select ca.name,count(ca.name)
from film as fi join film_category as fc
on fi.description like "%robot%" and fi.film_id=fc.film_id
join category as ca
on ca.category_id=fc.category_id
where fc.category_id in (select category_id from film_category group by category_id having count(category_id)>=5)
八、


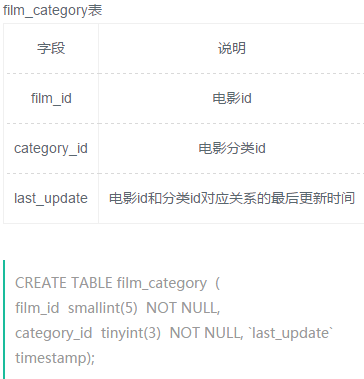
使用join查询方式找出没有分类的电影id以及名称
1、左连接 取差
select f.film_id,f.title from film as f
left join film_category as fc
on f.film_id=fc.film_id
where fc.category_id is null
2、
不用连接的方式
找出film_category中film_id的集合,film中的film_id没有在集合中的就输出
select f.film_id,f.title from film as f
where f.film_id not in (select film_id from film_category)
九、


使用子查询的方式找出属于Action分类的所有电影对应的title,description
1、
非子查询的方法,join
按着电影名、电影类型将三个表连接起来,然后限制Action条件就可以了。
select fi.title,fi.description from film_category as fc join film as fi on fc.film_id=fi.film_id join category as ca on fc.category_id=ca.category_id and ca.name="Action"
2、子查询
层层嵌套利用where查询
select fi.title,fi.description from film as fi
where fi.film_id in
(select fc.film_id from film_category as fc
where fc.category_id in
(select ca.category_id from category as ca where ca.name="Action"))
十、
题目描述

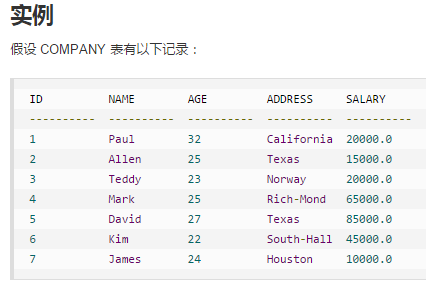
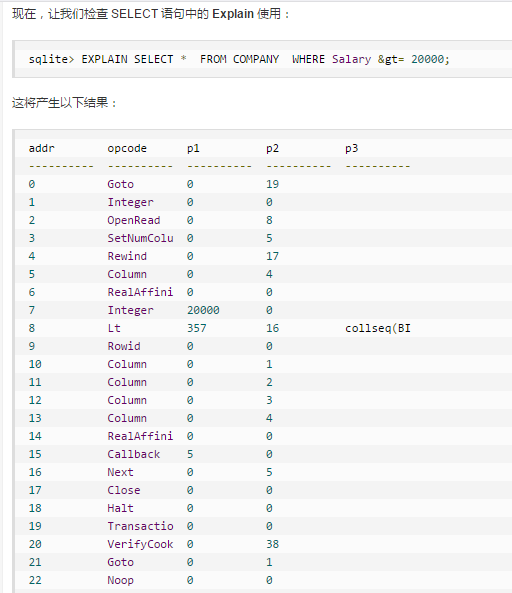
explain select * from employees
SQL实战(三)的更多相关文章
- 第8章 Spark SQL实战
第8章 Spark SQL实战 8.1 数据说明 数据集是货品交易数据集. 每个订单可能包含多个货品,每个订单可以产生多次交易,不同的货品有不同的单价. 8.2 加载数据 tbStock: scala ...
- 牛客网数据库SQL实战解析(51-61题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(21-30题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(1-10题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- MySQL:怒刷牛客网“sql实战”
MySQL:怒刷牛客网"sql实战" 在对MySQL有一定了解后,抽空刷了一下 牛客网上的 数据库SQL 实战,在此做一点小小的记录 SQL1 查找最晚入职员工的所有信息 sele ...
- coreseek实战(三):全文搜索在php中应用(使用api接口)
coreseek实战(三):全文搜索在php中应用(使用api接口) 这一篇文章开始学习在php页面中通过api接口,使用coreseek全文搜索. 第一步:综合一下前两篇文章,coreseek实战( ...
- Python爬虫实战三之实现山东大学无线网络掉线自动重连
综述 最近山大软件园校区QLSC_STU无线网掉线掉的厉害,连上之后平均十分钟左右掉线一次,很是让人心烦,还能不能愉快地上自习了?能忍吗?反正我是不能忍了,嗯,自己动手,丰衣足食!写个程序解决掉它! ...
- Thrift RPC实战(三) thrift序列化揭秘
本文主要讲解Thrift的序列化机制, 看看thrift作为数据交换格式是如何工作的? 1.构造应用场景: 1). 首先我们先来定义下thrift的简单结构. 1 2 3 4 5 namespace ...
- 牛客网数据库SQL实战解析(41-50题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(31-40题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
随机推荐
- MVC04
1. 从页面到action 讲述controller与View之间的具体运作关系 在上次添加的名为Movie的Model内添加 下面我们尝试为该model内的属性添加attribute 具体修改如下: ...
- 7,MapReduce基础
目录 MapReduce基础 一.关于MapReduce 二.MapReduce的优缺点 三.MapReduce的执行流程 四.编写MapReduce程序 五.MapReduce的主要执行流程 Map ...
- 复制图片链接和标题生成Markdown文本
写Markdown的时候常常会需要复制图片链接和标题以插入图片,不借助其他工具的话,一般需要先在Markdown文件中输入插入图片的格式,然后在浏览器中复制图片链接和标题将其依次粘贴到Markdown ...
- 如何找回微信小程序源码?2020年微信小程序反编译最新教程 小宇子李
前言:在网上看了找回微信小程序源码很多教程,都没法正常使用.微信版本升级后,会遇到各种报错, 以及无法获取到wxss的问题.查阅各种资料,最终解决,于是贴上完整的微信小程序反编译方案与教程. 本文章仅 ...
- element中的树形组件,如何获取父级菜单的id
一般多选的树形组件,使用getCheckedNodes()方法只能获取到本级的菜单id,只有在子菜单全部选中的情况下才会选中上级.但我们想要不全选中子级的情况下也要获取它的上级,甚至上上级等,怎么办呢 ...
- Spark实战--搭建我们的Spark分布式架构
Spark的分布式架构 如我们所知,spark之所以强大,除了强大的数据处理功能,另一个优势就在于良好的分布式架构.举一个例子在Spark实战--寻找5亿次访问中,访问次数最多的人中,我用四个spar ...
- Windows通过VNC连接并显示Linux桌面(Ubuntu16.04)
目录 Linux中安装VNC服务 Linux中安装桌面环境 Windows中安装VNC Viewer Linux中安装VNC服务 sudo apt-get update sudo apt-get in ...
- turtle学习笔记
1.turtle的绘图窗体 turtle.setup(width, height, startx,starty) - setup()设置窗体大小及位置- 4个参数中后两个可选(后两个省略时默认窗口在屏 ...
- STM32时钟配置方法
一.在STM32中,有五个时钟源,为HSI.HSE.LSI.LSE.PLL. ①HSI是高速内部时钟,RC振荡器,频率为8MHz. ②HSE是高速外部时钟,可接石英/陶瓷谐振器,或者接外部时钟源,频率 ...
- 在d盘创建文件夹,里面有aaa.txt/bbb.txt/ccc.txt,然后遍历出aaa文件夹下的文件(新手)
//导入的包.import java.io.File;import java.io.IOException;//创建的一个类.public class zy { //公共静态的主方法. public ...