sparkRdd driver和excuter
//1 从内存中创建makeRdd,底层实现就是parallelize
val rdd=sc.makeRDD(Array(1,2,"df",55)) //2 从中创建parallelize
val paraRdd=sc.parallelize(Array(1,2,3,54,5)) //3 从外部存储中创建
// 默认情况下,可以读取项目路劲,也可以读取其他路劲如hdfs
// 默认从文件中读取数据都是字符串类型
// 读取文件时,传递的分区参数为最小分区数,但不一定是这个分区数,取决与hadoop读取文件时的分片规则
val fileRdd=sc.textFile("path",2)
mapParitions的优缺点:
mapParitions可以对一个RDD中所有的分区进行遍历
mappartitions.效率优于map算子,减少了发送到执行器执行交互次数
mappartitions内存溢出是当一个分区数据过大,发送时执行的exctuer可能放不下,出现OOM
mapPartitionsWithIndex:
val listRdd = sc.makeRDD(1 to 10,2)
val indexRdd = listRdd.mapPartitionsWithIndex({
case (num, datas) => {
datas.map((_, "分区号:" + num))
}
}) indexRdd.foreach(println(_))
/**
*
* (6,分区号:1)
(1,分区号:0)
(7,分区号:1)
(2,分区号:0)
(8,分区号:1)
(3,分区号:0)
(9,分区号:1)
(10,分区号:1)
(4,分区号:0)
(5,分区号:0)
*/
driver和excuter:
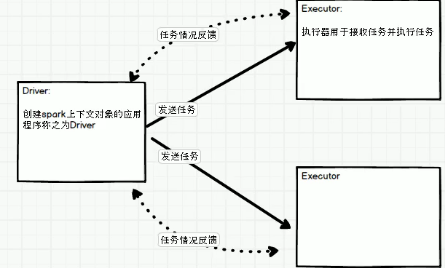
代码分布:
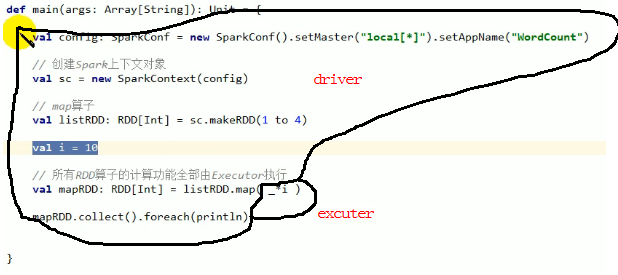
上述代码执行没有问题,i可序列化。执行时会将i传输到excuter上,传输就牵扯io,就需要序列化。所以需要传输的内容必须能够序列化,否则就会报错。
val rdd3 = sc.makeRDD(List(1, 32, 3, 4, 5))
rdd3.foreach({
case i => {
println(i * 2) //Executor
}
}) rdd3.collect().foreach({
case i => {
println(i * 2) //Driver,collect后是一个数组,相当与把数据拿到driver中进行计算
}
})
glom将同一个分区的数据放到一个数组中
val rdd1 = sc.makeRDD(1 to 10,3)
val glomRddArr:RDD[Array[Int]] = rdd1.glom()
glomRddArr.foreach(arr=>{
val str = arr.mkString(",")
println(str)
})
/**
* 4,5,6
1,2,3
7,8,9,10
*/
shuffle操作
//将rdd中一个分区的数据打乱重组到其他不同分区的操作称为shuffle,如distinct
//rdd的操作牵扯到shuffle的算子效率就会降低。
val rdd2 = sc.makeRDD(1 to 10, 5)
//可以设置是否shuffle,默认是不shuffle。
// repairtition实际上默认是shuffle,底层是coalesce coalesce(num,shuffle=ture)
val coaRdd = rdd2.coalesce(2)
sparkRdd driver和excuter的更多相关文章
- hadoop学习之yarn资源管理
一.yarn简介 yarn是在hadoop2.x中才引入的一个新的机制,在hadoop1.x中MapReduce任务需要同时做任务管理和资源分配,那么引入yarn之后,hadoop的资源管理的任务就全 ...
- spark 大杂烩
累加器 val dataRdd = sc.makeRDD(List(1, 2, 3, 4), 2) var sum = 0 //累加器可以收集driver和各个excuter中累加的结果 //如果此处 ...
- 深入linux kernel内核配置选项
============================================================================== 深入linux kernel内核配置选项 ...
- sparkRDD:第3节 RDD常用的算子操作
4. RDD编程API 4.1 RDD的算子分类 Transformation(转换):根据数据集创建一个新的数据集,计算后返回一个新RDD:例如:一个rdd进行map操作后生了一个新的rd ...
- MongoDB Java Driver操作指南
MongoDB为Java提供了非常丰富的API操作,相比关系型数据库,这种NoSQL本身的数据也有点面向对象的意思,所以对于Java来说,Mongo的数据结构更加友好. MongoDB在今年做了一次重 ...
- c#操作MangoDB 之MangoDB CSharp Driver驱动详解
序言 MangoDB CSharp Driver是c#操作mongodb的官方驱动. 官方Api文档:http://api.mongodb.org/csharp/2.2/html/R_Project_ ...
- Java JDBC Thin Driver 连接 Oracle 三种方法说明(转载)
一.JDBC 连接Oracle 说明 JDBC 的应用连接Oracle 遇到问题,错误如下: ORA-12505,TNS:listener does not currently know of SID ...
- 设备模型(device-model)之平台总线(bus),驱动(driver),设备(device)
关于关于驱动设备模型相关概念请参考<Linux Device Drivers>等相关书籍,和内核源码目录...\Documentation\driver-model 简单来说总线(bus) ...
- AM335x tscadc platform driver 相关代码跟踪
TI AM335x ti am335x_tsc.c 代码跟踪 在kernel 首层目录: 先运行make ARCH=arm tags 这个作用是建立tags文件,只含有arm架构的,利用ctag即可进 ...
随机推荐
- JVM的组成
JVM一共有五大区域,程序计数器.虚拟机栈.本地方法栈.Java堆.方法区. 程序计数器 程序技术器是一块很小的内存空间,由于Java是支持多线程的.当线程数大于CPU数量时,CPU会按照时间片轮寻执 ...
- 懂一点Python系列——快速入门
本文面相有 一定编程基础 的朋友学习,所以略过了 环境安装.IDE 搭建 等一系列简单繁琐的事情. 一.Python 简介 Python 英文原意为 "蟒蛇",直到 1989 年荷 ...
- Swift 4.0 字典(Dictionary)学习
定义字典常量(常量只有读操作) let dictionary1 = ["key1": 888, "key2": 999] let dictionary2: [S ...
- 面试刷题11:java系统中io的分类有哪些?
随着分布式技术的普及和海量数据的增长,io的能力越来越重要,java提供的io模块提供了足够的扩展性来适应. 我是李福春,我在准备面试,今天的问题是: java中的io有哪几种? java中的io分3 ...
- hdu1224SPFA求最长路加上打印路径
题目链接:http://icpc.njust.edu.cn/Problem/Hdu/1224/ 无负环. 代码如下: #include<bits/stdc++.h> using names ...
- 动态规划-Maximum Subarray-Maximum Sum Circular Subarray
2020-02-18 20:57:58 一.Maximum Subarray 经典的动态规划问题. 问题描述: 问题求解: public int maxSubArray(int[] nums) { i ...
- 浅谈VUE,使用watch方法监听父组件传到子组件的数据。
props:['updateData'], data(){ return{ form: { _name:'', }, } }, 第一步接收数据: props:['updateData'] 第二步动 ...
- Python批量修改Excel中的文件内容
import osimport xlrdfrom xlutils.copy import copydef base_dir(filename=None): return os.path.join ...
- Python第六章-函数06-高阶函数
函数的高级应用 二.高阶函数 高级函数, 英文叫 Higher-order Function. 那么什么是高阶函数呢? 在说明什么是=高阶函数之前, 我们需要对函数再做进一步的理解! 2.1 函数的本 ...
- java——构造器理解
构造器理解 什么是构造器 构造器也叫构造方法:用于对象的初始化: 写构造器注意事项 构造器名与类名一致:有返回值但是不能定义返回类型(返回值类型是本类,可以加一个空的return): 构造器的调用 通 ...