spark 大杂烩
累加器
val dataRdd = sc.makeRDD(List(1, 2, 3, 4), 2)
var sum = 0
//累加器可以收集driver和各个excuter中累加的结果
//如果此处删除累加器,用java的算法sum=sum+i那么结果是0,driver端的sum就是0,缺有无法得知各个excuter中加到了几
val accumulator = sc.longAccumulator
dataRdd.foreach({
case i=>{
sum=sum+i
accumulator.add(i)
}
})
println("sum = "+accumulator.value)
//也可以自定义累加器加单词等,不只有long
序列化
//class Params(query:String) extends java.io.Serializable{
class Params(query: String) {
//main中用到params对象的此方法会提示需要对象序列化
def isMatch(s: String): Boolean = {
s.contains(query)
}
//main中用到params对象的此方法会提示需要对象序列化
def getMatch1(rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
//main中用到params对象即使没有序列化也ok
def getMatch2(rdd: RDD[String]): RDD[String] = {
val q = query
rdd.filter(x => x.contains(q))
}
}
宽窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我形象的比喻为独生子女
宽依指的是多个子RDD的Partition会依赖同一个父RDD的 Partition,会引起shuffle.总结:宽依我们形象的比喻为超生
DAG
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就就成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的 Stage,对于窄依糗partition的转换处理在 Stage中完成算,对于宽依赖,由于有Shuffle的存在,只能在 parentRDD处理完成后,才能开始接下来的计算,因此宽依是划分Stage的依据。
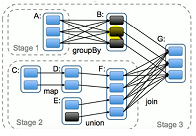
RDD任务划分
RDD任务切分中间分为: Application、job、 Stage和Task
1) Application:初始化一个 Spark Context I即生成一个 Application
2)Job:一个 Action算子就会生成一个Job
3) Stage:根据RDD之间的依赖关系的不同将Job划分成不同的 Stage,通到一个宽依赖则划分一个 Stage,

stage=1+发生shuffle的个数
task=每个stage的数据分区数之和= 5+3
RDD缓存
RDD通过 persist方法或 cache方法可以将前面的计算结果缓存,认情况下 persist()会把数据以序列化的形式缓存在jvm的堆究间中。
但是并不是这两个方法被调用时立即缓存,面是触发后面的 action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。并且血统中会指向这个缓存。当缓存丢失时就会重新计算。
RDD数据分区器
Spark目前支持Hash分区和 Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spak中分区直接决定了RDD中分区的个数、RDD中每条数据经过 Shuttle过程属于哪个分区和 Reduce 的个数
注意:(1)只有 Key-value类型的RDD才有分区器的,非Key- Value类型的RDD分区的值是Nono
(2)每个RDD的分区ID范国:0- numPartition-1,决定这个值是所于那个分区的。
Hash分区器
Hashpartitioner分的原理:对于给定的key,计算其 hashcode,并除以分区的个数取余,如果余数小于0,则用余数+分区的个数(否则加0),最后返回的值就是这个key所属的分区ID
Range分区器
Hashpartitioner分区弊端:可能导致每个分区中数据量的不匀,校端情况下会导致某些分区拥有RDD的全部数据。
Rangepartitioner作用:将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素背定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。简单的说就是将一定范国内的数映射到某一个分区内。
foeachPatirtion内
foeachPatirtion内datas.foreach是在excuter中执行,datas已是集合不是rdd,不涉及网路交互
Spark三大数据结构
RDD:分布式数据集
广播变量:分布式只读共享变量,广播变量的作用是将公用只读的集合广播出去,广播到excuter中,每个task读取自己excuter中的副本。注意广播内容的大小和excuter内存
累加器:分布式只写共亨变量,累加器可以将driver和excuter中的数据相加
reduceBykey和 groupByKey的区别
1. reducebykey:按照key进行聚合,在 shuttle之前有 combine(顶聚合)操作,返回结果是 RDD[k,v]
2. geroupbykey:按照key进行分组,直接进行 shuffle
3.开发指导: reducebykey比 groupbykey,建议使用。但是需要注意是否会影响业务逻辑
kafka流数据建议先看看下Streaming的分区运算情况,假如默认2个分区执行,那么根据数据量和资源情况可进行重分区,以便重分利用资源提交处理效率。
spark 大杂烩的更多相关文章
- XMPP大杂烩
XMPP大杂烩 对XMPP的理解 XMPP是基于XML的即时通讯协议.对即时通讯场景进行了高度抽象,比如用订阅对方的上下线状态表示好友.提供了文本通讯.用户上下线通知.联系人管理.群组聊天等功能,还可 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
随机推荐
- 面向对象第三单元博客(JML)
// demo/Graph.java package demo; import java.util.ArrayList; public class Demo { /*@ public norm ...
- Windows主机与centOS虚拟机之间"ping不通"
为什么要遇到这个问题 这是我重新安装centOS7.5虚拟机之后遇到的问题——我需要安装一个SecureCRT工具,结果主机与虚拟机没有ping通. 在安装这个工具之前需要进行主机与虚拟机的相互pin ...
- 推荐一款优秀的web自动化测工具
在业务使用的自动化测试工具很多.有开源的,有商业化的,各有各得特色,各有各得优点!下面我就介绍几个我用过的一款非常优秀的国产自动化测试工具.在现有的自动化软件当中,都是以元素的name.id.xpat ...
- thinkphp 前后端分离
thinkphp 前后端分离 简单记录一下之前学习tp的历程吧. 前端HTML页面渲染 <?php namespace app\index\controller; use think\Contr ...
- C# 基础知识系列- 3 集合数组
简单的介绍一下集合,通俗来讲就是用来保管多个数据的方案.比如说我们是一个公司的仓库管理,公司有一堆货物需要管理,有同类的,有不同类的,总而言之就是很多.很乱.我们对照集合的概念对仓库进行管理的话,那么 ...
- 微信开发+百度AI学习:环境搭建
注册成为百度开发者,百度接入指南http://ai.baidu.com/docs#/Begin/top 选择分类进去创建应用,接口权限全部选择好了,这样就可以只创建一个应用就有全部接口权限. C#开发 ...
- hdu1078 dfs+dp(记忆化搜索)搜索一条递增路径,路径和最大,起点是(0,0)
#include<bits/stdc++.h> using namespace std; typedef unsigned int ui; typedef long long ll; ty ...
- 题解 CF1304E 【1-Trees and Queries】
前言 这场比赛,在最后 \(5\) 分钟,我想到了这道题的 \(Idea\),但是,没有打完,比赛就结束了. 正文 题目意思 这道题目的意思就是说,一棵树上每次给 \(x\) 和 \(y\) 节点连 ...
- OpenCV-Python 图像平滑 | 十六
目标 学会: 使用各种低通滤镜模糊图像 将定制的滤镜应用于图像(2D卷积) 2D卷积(图像过滤) 与一维信号一样,还可以使用各种低通滤波器(LPF),高通滤波器(HPF)等对图像进行滤波.LPF有助于 ...
- TensorFlow系列专题(三):深度学习简介
一.深度学习的发展历程 深度学习的起源阶段 深度学习的发展阶段 深度学习的爆发阶段 二.深度学习的应用 自然语言处理 语音识别与合成 图像领域 三.参考文献 一.深度学习的发展历程 作为机器学习最 ...