从源码和doc揭秘——Java中的Char究竟几个字节,Java与Unicode的关系
#编码与字符编码 (懂编码的建议直接跳过)
在计算机世界中,任何事物都是用二进制图片数字表示的,图片可以编码为JPG,PNG格式的字节流,音频,视频有MP3,MP4格式的字节流。这些JPG,MP3等都是一些众所周知的编码格式罢了,只要你
定义一个映射关系,可以正确地对文件进行编码解码,那么这就是一种编码格式。可能会有人认为一些文本文件是文本格式的,它们能用记事本直接打开,因此不是二进制格式的。这种说法并不正确,能打
开是大部分记事本默认的编码如GB2312,UTF-8,ISO等 都兼容了ASCII码,当你用记事本打开视频时,会出现很多奇怪的字符,这是因为你尝试用一种字符编码(ASCII)解码 (MP3).就像编码时你用
y=2(x)+1,解码不用x=(1-y)/2反而用 x=1+y一样。
更详细的编码字符编码背景知识和一些常见字符编码规则的实现方式,推荐这篇文章,里面描述从ASCII码,ISO-8859-1到GBK,GB2312,Unicode, UTF-8,UTF-16,UTF-32等编码的具体实现方式。
#Unicode编码
Unicode,又称万国码,它尝试将世界上所有出现的字符都用同一格式去表示。Unicode定义了字符和码点(字符表示值)的映射关系。如用61表示A,附上一个Unicode码点查询
再次强调Unicode只是定义字符和码点的映射关系,这个映射关系是一对一的,但并没有落地到这个码点如何用对应的二进制表示。

这里我们可能会想,我直接码点是什么内存里就用这个数字表示不就好了吗?是的,朋友,在Java中,char类型存储的就是这个码点。但是考虑表示多个char的情况,如"ab",当直接使用码点表示时,
表示为0x0000006100000062,需要使用8个字节64位。这时你会觉得这样表示太蠢,想尝试压缩一下。因此对字符串进行编码实际上也是一种压缩。接下来看看java中单个char和多个char是如何存储的。
#Java的char存储的是什么,占几个字节
先亮个论据,javadoc中Character类的一段话。

从中得出以下几条信息:
1.Unicode码点可以简单分为两类,
1.BMP码 Basic Multilingual Plane ,码点值为0-0xffff,即最大值65535,
2.补充码 ,(BMP) 和 supplementary characters. 码点值>65535
2.Java中用两个字节表示char,在char中存储的是字符的Unicode码点,char只能表示 BMP子符。
这里我也疑惑很久Java是如何表示单个的补充码字符,后来明白Java给出的方式就是 “表示不了” ,这样也很合理,65536个字符几乎已经涵盖世界主流语言用到的所有字符了,没必要为了极少出现的字
符而构建一个复杂的char类型。
3.对于char数组和String及相关类,java使用utf-16编码存储这些字符的码点。
其实String底层也是存了个char数组,本质上就是char数组。
4.对于补充码,java采用pair的方式存储,即用两个char来表示。
前面已经提到了,java单个char只能表示BMP码,如果要处理补充码时,则使用字符串或字符数字表示。用代码演示如下
char c=65535;
char[] c1=Character.toChars(65536);
仔细观察Character代码,发现并没有将int型的码点转为char型的方法,这正是因为这个码点可能需要用两个char表示。

#使用Character相关的API验证以上结论
/**定义两个码点,一个是BMP,一个是补充码
*/
int codepoint1=97;
int codepoint2=65536;
System.out.println(Character.isBmpCodePoint(codepoint1));
System.out.println(Character.isSupplementaryCodePoint(codepoint2));
/**
* 将字符用char表示,验证java单个字符,2个字节(具体的表示值是utf-16)表示unicode字符只能表示unicode中bmp
* 从api就可以看出,java并没有codepoint toChar的相关方法,是因为无法保证所有码点都能用单个char表示
*/
System.out.println(Character.toChars(codepoint1).length); //一个
System.out.println(Character.toChars(codepoint2).length); //两个 /**
* 验证无论是补充码还是BMP都是一个字符,只是对补充码存储是用4个字节-一个pair表示罢了
*/
String s1=new String(Character.toChars(codepoint1));
String s2=new String(Character.toChars(codepoint2));
System.out.println(s1);//屏幕上出现一个字符
System.out.println(s2);//屏幕上出现一个字符
#String与编码的关系
这里再重复一遍本篇反复提到的一个结论,java存储单个char时直接码点值,存储char数组或是String相关对象时,编码格式是UTF-16。(String底层就是存的char数组),因此,String存储字符串时,
存储它的UTF-16编码值。获得一个String对象,无外乎三种方式:
1.直接使用字面量构建。
String s="abc" 或是String s=new String("abc"),在编译后的字节码中,使用UTF-8编码存储这个字面量,在内存中存储时会转换为uft16格式。
在内存中存储时会转换为uft16格式,这是我个人的理解和猜测,由于来自字面量的字节流一定是UTF-8的,还可能只是简单标记一下这是来自字面量,然后直接存储它的utf-8字节流。
2.从字符数组构建
其实String类有一个属性char[],也就是String底层就是char数组。
3.从字节流构建
字节流就是对字符串以一种格式进行编码得到二进制数,字节流是需要区分编码格式的。字节流与String转换的API如下:
byte[] bytes1=s1.getBytes();//s1用utf-8编码的字节流
byte[] bytes2=s2.getBytes(StandardCharsets.UTF_16BE);//s2用uft-16编码的字节流,UTF-16,16BE,LE的区别不是本文重点,UTF-16多出额外字节表示大小端顺序
byte[] bytes3=s2.getBytes("UTF-32");//s2用uft-32编码的字节流
System.out.println(bytes1.length);// 1
System.out.println(bytes2.length);// 4
System.out.println(bytes3.length);// 4 /**
* 在对String对象和字节流进行转换时,需要指定编码,默认使用utf-8
*/
String ds1=new String(bytes1);
String ds2=new String(bytes2,StandardCharsets.UTF_16BE);
String ds3=new String(bytes3,"UTF-32");
String ds4=new String(bytes3); //错误解码 /**
* 解码得到字符串都是只包含一个unicode字符,码点是
* 再次回顾一下,字符用码点值对应,码点不能直接用char存储,因为补充码需要两个char,即一个pair表示,只能用char[] 或String
*/
System.out.println(ds1.codePointCount(0,ds1.length())+":"+ds1.codePointAt(0));
System.out.println(ds2.codePointCount(0,ds2.length())+":"+ds2.codePointAt(0));
System.out.println(ds3.codePointCount(0,ds3.length())+":"+ds3.codePointAt(0)); /**
* 由于解码使用错误的编码格式获得到了错误的4个unicode字符
*/
System.out.println(ds4.codePointCount(0,ds4.length()));
以上API说明字节流和String转换过程中需要指定编码,如果不指定,则默认使用系统默认编码,一般是UTF-8编码,具体和操作系统的local有关。
结论:String底层存储的就是一个UTF-16编码的字节流,只要是字节流,就是“被编码”的,因此进行字节流和String转换时需要指明编码。
#总结
通过这波分析,得出的重要结论有:
Java 使用两个字节表示 char,char能表示的字符有限,存储时char存储码点信息,与编码无关。
Java 使用UTF-16 编码格式存储字符数组,字符串。(选择UTF-16是出于多种因素的考量)
字节流一定是被某种字符集编码的,打开字节流应当使用正确的编码格式打开,这里的字节流是广义的。
#附加 ——验证字节码的字面量的编码是UTF-8
让我们实际操作一波并研究下从文本编辑器写下System.out.println("你好,世界");这行代码并运行时到屏幕正确打印"你好,世界”这个过程中,经历了多少次编码和解码。
环境介绍:文本编辑器Sublime,Linux 系统,默认locale编码如下

这里我就再次吐槽一波Windows,上次git下来公司一个其他团队的项目,居然打开是乱码,我第一反应是用Windows开发也就算了,至少改个IDE编码呀。估计这哥们编码应该是GBK.
1.首先创建一个文件,代码如下,保存为UTF-8格式,此处进行了编码。
public class Test{
public static void main(String[] args) {
System.out.println("你好,世界");
}
}
2.使用file Test.java命令确认编码

3.执行javac编译,这里先看一下这个参数

可以理解,使用javac编译源代码时是需要指定文件编码的,否则就是系统默认编码。这是因为文件也是字节流。
执行javac Test.java编译。
4.用sublime以UTF-8方式打开Test.class文件,看到如下内容。
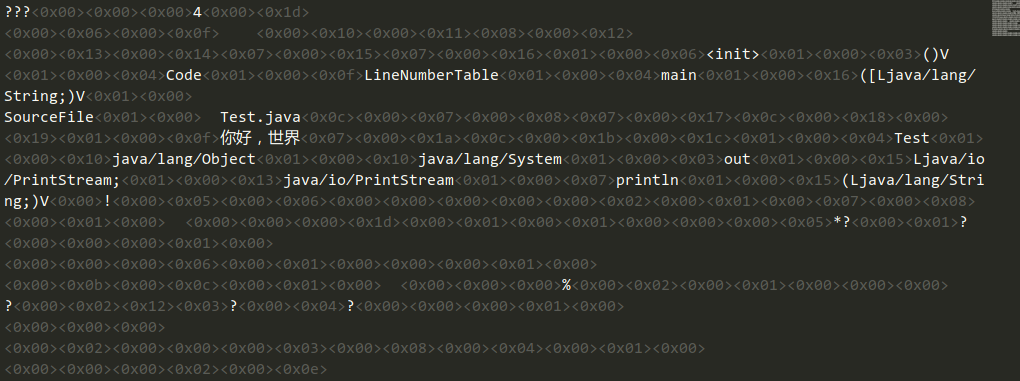
此处使用sublime对class文件以utf-8编码解码,发现中文显示正常,这说明字节码文件的确是以UTF-8编码存储字符串字面量。而这和我们源代码文件无关。
5.验证字节码的字面量编码与源代码无关,将源代码存为utf-16BE格式,进行编译。

再次以UTF-8编码打开Test.class,

6.执行java Test

java程序执行时,首先会从UTF-8编码的字节流(来自字节码)构建一个String,这个String s在内存中是使用UTF-16存储的,进行System.out.println()操作实际上是执行
OutputStream.write(s.getBytes()),这个字节流使用的是默认编码utf8。
在底层,jvm会将这个输出写出到操作系统的标准输出,本例中是由终端terminal将这个字节流显示为屏幕上一个个字符,因此终端在这个过程中又进行了一次解码。在本例中,
终端使用的编码是系统默认的UTF-8编码,如果我们执行以下命令更改系统默认编码。
7.编码和解码如此频繁,可见统一编码的重要性,只要一个环节不对,之后的环节就都是乱码的了。
从源码和doc揭秘——Java中的Char究竟几个字节,Java与Unicode的关系的更多相关文章
- Java中的char占用几个字节
目录 1.概述 2.答疑 3.总结 1.概述 网上或书上都说是Java中的char占用2个字节,一直没有深入,直到接触了编码,才对此产生了疑问,今天来深入一下这个问题. 2.答疑 char在设计之初的 ...
- Java中的char究竟能存中文吗?
今天面试被问到"Java中的char能存中文吗?",我回答有的字能有的字不能,结果被嘲笑了,不过我也忘了字符编码的相关知识所以也没能解释.晚上查了下资料,记录一下. 网上搜索这个问 ...
- java中的char占几个字节
1:“字节”是byte,“位”是bit : 2: 1 byte = 8 bit : char 在Java中是2个字节.java采用unicode,2个字节(16位)来表示一个字符. 例子代码如下: p ...
- java 中一个char包含几个字节
背景 char包含几个字节可能记得在上学的时候书上写的是2个字节,一直没有深究,今天我们来探究一下到底一个char多少个字节? Char char在设计之初的时候被用来存储字符,可是世界上有那 ...
- 在MyEclipse显示struts2源码和doc文档及自动完成功能
分类: struts2 2010-01-07 16:34 1498人阅读 评论(1) 收藏 举报 myeclipsestruts文档xmlfileurl 在MyEclipse显示struts2源码和d ...
- Hbase源码分析:Hbase UI中Requests Per Second的具体含义
Hbase源码分析:Hbase UI中Requests Per Second的具体含义 让运维加监控,被问到Requests Per Second(见下图)的具体含义是什么?我一时竟回答不上来,虽然大 ...
- OpenJDK源码研究笔记(十二):JDBC中的元数据,数据库元数据(DatabaseMetaData),参数元数据(ParameterMetaData),结果集元数据(ResultSetMetaDa
元数据最本质.最抽象的定义为:data about data (关于数据的数据).它是一种广泛存在的现象,在许多领域有其具体的定义和应用. JDBC中的元数据,有数据库元数据(DatabaseMeta ...
- Android多线程之(一)View.post()源码分析——在子线程中更新UI
提起View.post(),相信不少童鞋一点都不陌生,它用得最多的有两个功能,使用简便而且实用: 1)在子线程中更新UI.从子线程中切换到主线程更新UI,不需要额外new一个Handler实例来实现. ...
- 3D语音天气球(源码分享)——在Unity中使用Android语音服务
转载请注明本文出自大苞米的博客(http://blog.csdn.net/a396901990),谢谢支持! 开篇废话: 这个项目准备分四部分介绍: 一:创建可旋转的"3D球":3 ...
随机推荐
- 修改android项目sdk版本
1.右键单击项目--->properties---->Resource----->Android在Project Bulid Target对话框中选择你需要的Android版本.2. ...
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
- R语言入门级实例——用igragh包分析社群
R语言入门级实例——用igragh包分析社群 引入—— 本文的主要目的是初步实现R的igraph包的基础功能,包括绘制关系网络图(social relationship).利用算法进行社群发现(com ...
- 46-Python深浅拷贝
目录 一.引言 1.1 可变或不可变 二.拷贝 三.浅拷贝 深拷贝 一.引言 在python中,对象赋值实际上是对象的引用.当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象 ...
- java网络编程——socket实现简单的CS会话
还记得当年学计网课时用python实现一个简单的CS会话功能,这也是学习socket网络编程的第一步,现改用java重新实现,以此记录. 客户端 import java.io.*; import ja ...
- 前端javascript知识(三)
函数记忆,判断是不是质数. 方法一: function isPrime1(n){ if(n<=3){return true} else{ for(var i=2;i<Math.sqrt(n ...
- 负载均衡框架 ribbon 一
Ribbon开源地址:https://github.com/Netflix/ribbon/wiki/Getting-Started 1.Ribbon简介 负载均衡框架,支持可插拔式的负载均衡规则 支持 ...
- W3C的盒子模型和IE的盒子模型
盒子模型分为两种:W3C盒子模型(标准盒子模型)和IE盒子模型 盒子模型组成:content+padding+border+margin 标准盒子模型的width就是content 而IE盒子模型的w ...
- 记录:更新VS2019后单元测试运行卡住无法运行测试的问题。
先说一下是如何遇到这个问题的 今天更新了Visual Studio到最新的版本,然后在运行之前建立的单元测试项目的时候一直卡住,过了一会儿以后提示 未能协商协议,等待响应在 90 秒后超时.出现此问题 ...
- 误删除所有redo日志的一组成员的处理过程
系统中共有3个日志文件组,每个组中各有一个日志文件成员.往系统中添加一个日志文件组,组中日志文件成员数量是2.SQL> alter database add logfile group 4 (' ...