GBDT梯度提升树算法及官方案例
梯度提升树是一种决策树的集成算法。它通过反复迭代训练决策树来最小化损失函数。决策树类似,梯度提升树具有可处理类别特征、易扩展到多分类问题、不需特征缩放等性质。Spark.ml通过使用现有decision tree工具来实现。
梯度提升树依次迭代训练一系列的决策树。在一次迭代中,算法使用现有的集成来对每个训练实例的类别进行预测,然后将预测结果与真实的标签值进行比较。通过重新标记,来赋予预测结果不好的实例更高的权重。所以,在下次迭代中,决策树会对先前的错误进行修正。
对实例标签进行重新标记的机制由损失函数来指定。每次迭代过程中,梯度迭代树在训练数据上进一步减少损失函数的值。spark.ml为分类问题提供一种损失函数(Log Loss),为回归问题提供两种损失函数(平方误差与绝对误差)。
Spark.ml支持二分类以及回归的随机森林算法,适用于连续特征以及类别特征。不支持多分类问题。
# -*- coding: utf-8 -*-
"""
Created on Wed May 9 09:53:30 2018 @author: admin
""" import numpy as np
import matplotlib.pyplot as plt from sklearn import ensemble
from sklearn import datasets
from sklearn.utils import shuffle
from sklearn.metrics import mean_squared_error # #############################################################################
# Load data
boston = datasets.load_boston()
X, y = shuffle(boston.data, boston.target, random_state=13)
X = X.astype(np.float32)
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:] # #############################################################################
# Fit regression model
params = {'n_estimators': 500, 'max_depth': 4, 'min_samples_split': 2,
'learning_rate': 0.01, 'loss': 'ls'} #随便指定参数长度,也不用在传参的时候去特意定义一个数组传参
clf = ensemble.GradientBoostingRegressor(**params) clf.fit(X_train, y_train)
mse = mean_squared_error(y_test, clf.predict(X_test))
print("MSE: %.4f" % mse) # #############################################################################
# Plot training deviance # compute test set deviance
test_score = np.zeros((params['n_estimators'],), dtype=np.float64) for i, y_pred in enumerate(clf.staged_predict(X_test)):
test_score[i] = clf.loss_(y_test, y_pred) plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title('Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, clf.train_score_, 'b-',
label='Training Set Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, test_score, 'r-',
label='Test Set Deviance')
plt.legend(loc='upper right')
plt.xlabel('Boosting Iterations')
plt.ylabel('Deviance') # #############################################################################
# Plot feature importance
feature_importance = clf.feature_importances_
# make importances relative to max importance
feature_importance = 100.0 * (feature_importance / feature_importance.max())
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + .5
plt.subplot(1, 2, 2)
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, boston.feature_names[sorted_idx])
plt.xlabel('Relative Importance')
plt.title('Variable Importance')
plt.show()
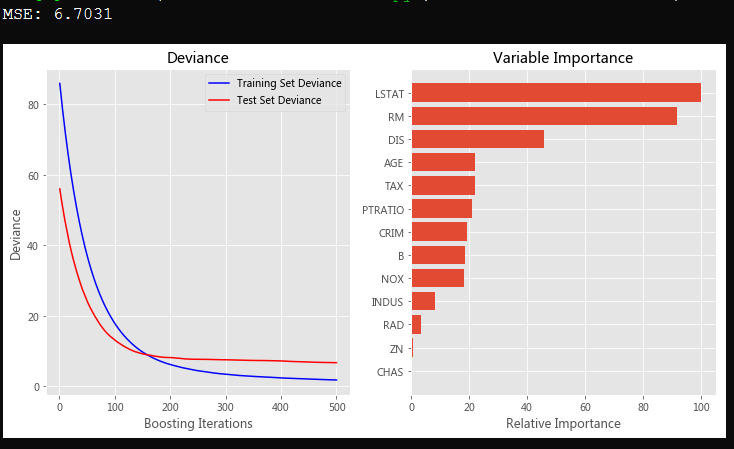
房产数据介绍:
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000'
参考:http://scikit-learn.org/stable/auto_examples/ensemble/plot_gradient_boosting_regression.html#sphx-glr-auto-examples-ensemble-plot-gradient-boosting-regression-py
GBDT梯度提升树算法及官方案例的更多相关文章
- 【小白学AI】GBDT梯度提升详解
文章来自微信公众号:[机器学习炼丹术] 文章目录: 目录 0 前言 1 基本概念 2 梯度 or 残差 ? 3 残差过于敏感 4 两个基模型的问题 0 前言 先缕一缕几个关系: GBDT是gradie ...
- GBDT(梯度提升树)scikit-klearn中的参数说明及简汇
1.GBDT(梯度提升树)概述: GBDT是集成学习Boosting家族的成员,区别于Adaboosting.adaboosting是利用前一次迭代弱学习器的误差率来更新训练集的权重,在对更新权重后的 ...
- 一文读懂:GBDT梯度提升
先缕一缕几个关系: GBDT是gradient-boost decision tree GBDT的核心就是gradient boost,我们搞清楚什么是gradient boost就可以了 GBDT是 ...
- 机器学习 | 详解GBDT梯度提升树原理,看完再也不怕面试了
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第30篇文章,我们今天来聊一个机器学习时代可以说是最厉害的模型--GBDT. 虽然文无第一武无第二,在机器学习领域并没有 ...
- GBDT 梯度提升决策树简述
首先明确一点,gbdt 无论用于分类还是回归一直都是使用的CART 回归树.不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练 ...
- 梯度提升决策树(GBDT)与XGBoost、LightGBM
今天是周末,之前给自己定了一个小目标:每周都要写一篇博客,不管是关于什么内容的都行,关键在于总结和思考,今天我选的主题是梯度提升树的一些方法,主要从这些方法的原理以及实现过程入手讲解这个问题. 本文按 ...
- 机器学习 之梯度提升树GBDT
目录 1.基本知识点简介 2.梯度提升树GBDT算法 2.1 思路和原理 2.2 梯度代替残差建立CART回归树 1.基本知识点简介 在集成学习的Boosting提升算法中,有两大家族:第一是AdaB ...
- 梯度提升树 Gradient Boosting Decision Tree
Adaboost + CART 用 CART 决策树来作为 Adaboost 的基础学习器 但是问题在于,需要把决策树改成能接收带权样本输入的版本.(need: weighted DTree(D, u ...
- R︱Yandex的梯度提升CatBoost 算法(官方述:超越XGBoost/lightGBM/h2o)
俄罗斯搜索巨头 Yandex 昨日宣布开源 CatBoost ,这是一种支持类别特征,基于梯度提升决策树的机器学习方法. CatBoost 是由 Yandex 的研究人员和工程师开发的,是 Matri ...
随机推荐
- 没有admin权限如何免安装使用Node和NPM
此教程只针对于在windows系统上没有admin权限和软件安装权限,但是又希望能像安装版一样使用Node和NPM的用户. 步骤一: 下载压缩版node 访问https://nodejs.org/en ...
- 在 React Native 中使用 moment.js 無法載入語系檔案
moment.js 是很常見的日期時間 library,友善的 API 與極佳的執行效率是它的兩大賣點.例如 (new Date()).getFullYear(),如果使用 moment.js 我可以 ...
- 量化投资学习笔记30——《Python机器学习应用》课程笔记04
有监督学习 常用分类算法 KNN:K近邻分类器.通过计算待分类数据点,与已知数据中所有点的距离,取距离最小的前K个点,根据"少数服从多数"的原则,将这个数据点划分为出现次数最多的那 ...
- VirtualBox上使用kubeadm安装Kubernetes集群
之前一直使用minikube练习,为了更贴近生产环境,使用VirtualBox搭建Kubernetes集群. 为了不是文章凌乱,把在搭建过程中遇到的问题及解决方法记在了另一篇文章:安装Kubernet ...
- ASP.NET CORE 启动过程及源码解读
在这个特殊的春节,大家想必都在家出不了们,远看已经到了回城里上班的日子,但是因为一只蝙蝠的原因导致我们无法回到工作岗位,大家可能有的在家远程办公,有些在家躺着看书,有的是在家打游戏:在这个特殊无聊的日 ...
- VMware Workstation 虚拟机的安装及kali Linux 的安装
要用到虚拟机了,Windows平台的虚拟机现在主要用的是VMWare 和VirtuualBox了.VirtualBox作为一款免费的软件,用着还行.笔者这里主要介绍VMware的安装和使用 . 下载: ...
- jquery-购物车js
购物车示例js,为了方便参考,页面写的比较简单.示例如下图所示: html代码如下: <!doctype html> <html lang="en"> &l ...
- 蚂蚁金服开源 | 可视化图形语法G2 3.3 琢磨
G2 是蚂蚁金服数据可视化解决方案 AntV 的一个子产品,是一套数据驱动的.高交互的可视化图形语法. 经过两个多月密锣紧鼓的开发,400+次提交,G2 3.3版本今天终于和大家见面了.自上次3.2版 ...
- NetAnalyzer笔记 之 十一 打造自己的协议分析语言(1)初衷与语法构想
回头看看NetAnalyzer开发系文档上次一篇竟然是2016年,老脸一红.不过这几年墨云成功过的讨到一个温柔贤淑的老婆,有了一个幸福的家庭,去年9月又有了一个大胖儿子,想想也就释然了^_^ 其实这几 ...
- Java——JDBC
今天给大家更新一篇我自己学习Java——JDBC的经验 Java中JDBC是(Java DataBase Connectivity)的简称,由java语言编写的类和接口组成,可为多种关系型数据库提供了 ...