Lucene 源代码剖析-2 Lucene是什么
转载自 http://download.csdn.net/source/858994
源地址下是 Word 文档,这里转换成HTML 格式
1 Lucene是什么
Apache Lucene是一个高性能(high-performance)的全能的全文检索(full-featured
text search engine)的搜索引擎框架库,完全(entirely)使用Java开发。它是一种技术(technology),适合于(suitable
for)几乎(nearly)任何一种需要全文检索(full-text search)的应用,特别是跨平台(cross-platform)的应用。
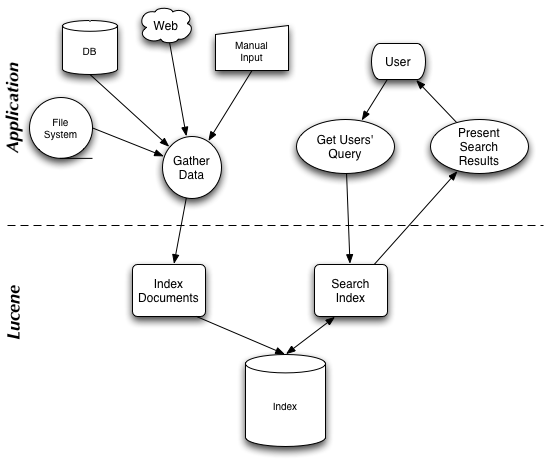
Lucene 通过一些简单的接口(simple
API)提供了强大的特征(powerful features):
可扩展的高性能的索引能力(Scalable, High-Performance Indexing)
- 超过20M/分钟的处理能力(Pentium
M 1.5GHz) - 很少的RAM内存需求,只需要1MB
heap - 增量索引(incremental indexing)的速度与批量索引(batch
indexing)的速度一样快 - 索引的大小粗略(roughly)为被索引的文本大小的20-30%
强大的精确的高效率的检索算法(< /strong>Powerful, Accurate and Efficient Search Algorithms)
queries, wildcard queries, proximity queries, range queries等
results)
跨平台解决方案(Cross-Platform Solution)
License,允许你可以在即包括商业应用也包括Open Source程序中使用Lucene
Lucene API被分成(divide
into)如下几种包(package)
定义了一个抽象的Analyser API,用于将text文本从一个java.io.Reader转换成一个TokenStream,即包括一些Tokens的枚举容器(enumeration)。一个TokenStream的组成(compose)是通过在一个Tokenizer的输出的结果上再应用TokenFilters生成的。一些少量的Analysers实现已经提供,包括StopAnalyzer和基于语法(gramar-based)分析的StandardAnalyzer。
提供一个简单的Document类,一个document只不过包括一系列的命名了(named)的Fields(域),它们的内容可以是文本(strings)也可以是一个java.io.Reader的实例。
提供两个主要类,一个是IndexWriter用于创建索引并添加文档(document),另一个是IndexReader用于访问索引中的数据。
提供数据结构(data structures)来呈现(represent)查询(queries):TermQuery用于单个的词(individual
words),PhraseQuery用于短语,BooleanQuery用于通过boolean关系组合(combinations)在一起的queries。而抽象的Searcher用于转变queries为命中的结果(hits)。IndexSearcher实现了在一个单独(single)的IndexReader上检索。
使用JavaCC实现一个QueryParser。
定义了一个抽象的类用于存储呈现的数据(storing persistent data),即Directory(目录),一个收集器(collection)包含了一些命名了的文件(named
files),它们通过一个IndexOutput来写入,以及一个IndexInput来读取。提供了两个实现,FSDirectory使用一个文件系统目录来存储文件,而另一个RAMDirectory则实现了将文件当作驻留内存的数据结构(memory-resident
data structures)。
包含了一小部分有用(handy)的数据结构,如BitVector和PriorityQueue等。
2 Hello
World!
下面是一段简单的代码展示如何使用Lucene来进行索引和检索(使用JUnit来检查结果是否是我们预期的):

 // Store the index in memory: Directory directory = new RAMDirectory(); // To store an index on disk, use this instead: //Directory directory = FSDirectory.getDirectory(”/tmp/testindex”); IndexWriter iwriter = new IndexWriter(directory, analyzer, true); iwriter.setMaxFieldLength(25000); Document doc = new Document(); String text = “This is the text to be indexed.“; doc.add(new Field(“fieldname“, text, Field.Store.YES, Field.Index.TOKENIZED)); iwriter.addDocument(doc); iwriter.optimize(); iwriter.close(); // Now search the index: IndexSearcher isearcher = new IndexSearcher(directory); // Parse a simple query that searches for ”text”: QueryParser parser = new QueryParser(“fieldname“, analyzer); Query query = parser.parse(“text“); Hits hits = isearcher.search(query); assertEquals(1, hits.length()); // Iterate through the results:
// Store the index in memory: Directory directory = new RAMDirectory(); // To store an index on disk, use this instead: //Directory directory = FSDirectory.getDirectory(”/tmp/testindex”); IndexWriter iwriter = new IndexWriter(directory, analyzer, true); iwriter.setMaxFieldLength(25000); Document doc = new Document(); String text = “This is the text to be indexed.“; doc.add(new Field(“fieldname“, text, Field.Store.YES, Field.Index.TOKENIZED)); iwriter.addDocument(doc); iwriter.optimize(); iwriter.close(); // Now search the index: IndexSearcher isearcher = new IndexSearcher(directory); // Parse a simple query that searches for ”text”: QueryParser parser = new QueryParser(“fieldname“, analyzer); Query query = parser.parse(“text“); Hits hits = isearcher.search(query); assertEquals(1, hits.length()); // Iterate through the results: for (int i = 0; i < hits.length(); i++) {
for (int i = 0; i < hits.length(); i++) { Document hitDoc = hits.doc(i); assertEquals(“This is the text to be indexed.“, hitDoc.get(“fieldname“));
Document hitDoc = hits.doc(i); assertEquals(“This is the text to be indexed.“, hitDoc.get(“fieldname“)); } isearcher.close(); directory.close();
} isearcher.close(); directory.close();
为了使用Lucene,一个应用程序需要做如下几件事:
1. 通过添加一系列Fields来创建一批Documents对象。
2. 创建一个IndexWriter对象,并且调用它的AddDocument()方法来添加进Documents。
3. 调用QueryParser.parse()处理一段文本(string)来建造一个查询(query)对象。
4. 创建一个IndexReader对象并将查询对象传入到它的search()方法中。
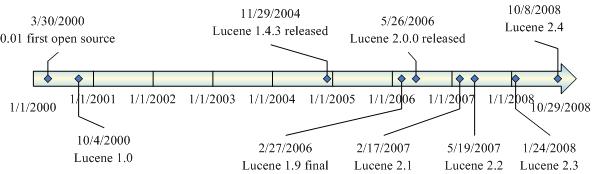
3 Lucene Roadmap

Lucene 源代码剖析-2 Lucene是什么的更多相关文章
- Lucene学习之四:Lucene的索引文件格式(1)
本文转载自:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623597.html Lucene的索引里面存了些什么,如何存放的,也即 ...
- 转】从源代码剖析Mahout推荐引擎
原博文出自于: http://blog.fens.me/mahout-recommend-engine/ 感谢! 从源代码剖析Mahout推荐引擎 Hadoop家族系列文章,主要介绍Hadoop家族产 ...
- NGINX源代码剖析 之 CPU绑定(CPU亲和性)
作者:邹祁峰 邮箱:Qifeng.zou.job@gmail.com 博客:http://blog.csdn.net/qifengzou 日期:2014.06.12 18:44 转载请注明来自&quo ...
- Qt中事件分发源代码剖析(一共8个步骤,顺序非常清楚:全局的事件过滤器,再传递给目标对象的事件过滤器,最终传递给目标对象)
Qt中事件分发源代码剖析 Qt中事件传递顺序: 在一个应该程序中,会进入一个事件循环,接受系统产生的事件,并且进行分发,这些都是在exec中进行的.下面举例说明: 1)首先看看下面一段示例代码: in ...
- STL源代码剖析 读书总结
<<STL源代码剖析>> 侯捷著 非常早就买了这本书, 一直没看, 如今在实验室师兄代码的时候发现里面使用了大量泛型编程的内容, 让我有了先看看这本书的想法. 看之前我对于泛型 ...
- 菜鸟nginx源代码剖析数据结构篇(一)动态数组ngx_array_t
菜鸟nginx源代码剖析数据结构篇(一)动态数组ngx_array_t Author:Echo Chen(陈斌) Email:chenb19870707@gmail.com Blog:Blog.csd ...
- STL源代码剖析(一) - 内存分配
Allocaor allocator 指的是空间配置器,用于分配内存.STL中默认使用SGI STL alloc作为STL的内存分配器,尽管未能符合标准规格,但效率上更好.SGI STL也定义有一个符 ...
- 【Java集合源代码剖析】LinkedHashmap源代码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/37867985 前言:有网友建议分析下LinkedHashMap的源代码.于是花了一晚上时间 ...
- 豌豆夹Redis解决方式Codis源代码剖析:Proxy代理
豌豆夹Redis解决方式Codis源代码剖析:Proxy代理 1.预备知识 1.1 Codis Codis就不详细说了,摘抄一下GitHub上的一些项目描写叙述: Codis is a proxy b ...
- Python源代码剖析笔记3-Python运行原理初探
Python源代码剖析笔记3-Python执行原理初探 本文简书地址:http://www.jianshu.com/p/03af86845c95 之前写了几篇源代码剖析笔记,然而慢慢觉得没有从一个宏观 ...
随机推荐
- 设计模式 | 中介者模式/调停者模式(Mediator)
定义: 用一个中介对象来封装以系列的对象交互.中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地变化他们之间的交互. 结构:(书中图,侵删) 一个抽象中介者 若干具体中介者 一个抽象 ...
- .net 环境使用 RabbitMQ ,由浅入深 【一】
最近因为先开发的项目需要用到消息队列,因此捣鼓了一下市面上开源的消息队列. 原本听闻Rocketmq ,一开始用的是 RocketMQ,各种集群搭建完毕,消息发送什么的测试后,,但是结果因为 Rock ...
- 如何调用openai的TTS模型
这是24年1月份写的了,调用代码大概率有变动,仅供参考. 1 什么是OpenAI的TTS模型 OpenAI的TTS模型是一种文本到语音(Text-to-Speech)模型,它可以将给定的文本转换为自然 ...
- 像 Mysql 和 MongoDB 这种大型软件在设计上都是精益求精的,它们为什么选择B树,B+树这些数据结构?
为什么 MongoDB (索引)使用B-树而 Mysql 使用 B+树? B 树与 B+ 树,其比较大的特点是:B 树对于特定记录的查询,其时间复杂度更低.而 B+ 树对于范围查询则更加方便,另外 B ...
- 事务发件箱模式在 .NET 云原生开发中的应用(基于Aspire)
原文:Transactional Outbox in .NET Cloud Native Development via Aspire 作者:Oleksii Nikiforov 总览 这篇文章提供了使 ...
- libtool版本错配(libtool version mismatch)
当使用configure和makefile编译项目时,出现如下报错: libtool: Version mismatch error. This is libtool 2.4.6, but the`` ...
- 算法学习-CDQ分治
对于二维偏序,为普通的求逆序对,只需要先排序一遍,然后树状数组或双指针即可 而三位偏序甚至更高,则需要用 CDQ 分治,简单来说,就是将树状数组和双指针结合 操作步骤如下: 1.开始将数组按第一维排序 ...
- iframe嵌套登录页-页面无法加载
背景 活动页面和登录页跨域,过去都是跳转到登录页登录之后再跳转回来,体验不好. 现在需要将登录模块嵌入到活动页,因为懒,不想开发重复的模块,首先我想到的是iframe 刚开始还能正常使用,一段时间后安 ...
- OpenAI 发布适用于 .NET 库的稳定版本
OpenAI 在 6 月发布测试版后发布了其官方 .NET 库的稳定版本.它以 NuGet 包的形式提供,支持 GPT-4o 和 GPT-4o mini 等最新模型,以及完整的 OpenAI REST ...
- SMMU中stage1 和stage2 的意思
ARM SMMU(System Memory Management Unit)是一种用于ARM架构的内存管理单元,它支持两阶段的地址转换机制,即Stage 1和Stage 2.这种机制允许操作系统和虚 ...