SAM4MLLM:结合多模态大型语言模型和SAM实现高精度引用表达分割 | ECCV'24
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: SAM4MLLM: Enhance Multi-Modal Large Language Model for Referring Expression Segmentation

- 论文地址:https://arxiv.org/abs/2409.10542
- 论文代码:https://github.com/AI-Application-and-Integration-Lab/SAM4MLLM
创新点
- 提出了一种允许
MLLM理解像素级细节的方法SAM4MLLM,无需改变MLLM模型架构、引入新标记或使用额外损失,该方法简单但对引用表达分割(RES)非常有效。 - 为了连接
MLLM和SAM,引入了一种新颖的方法,通过主动询问语言系统来获取提示点线索。 - 在各种
RES基准上进行实验,包括RES数据集、GRES和ReasonSeg,验证了SAM4MLLM的有效性,并展示了其在处理复杂像素感知任务中的优良性能。
内容概述
SAM4MLLM是一种创新的方法,集成Segment Anything Model(SAM)与多模态大型语言模型(MLLMs)以实现像素感知任务。
- 首先,在
MLLM训练数据集中引入像素级信息,而不改变原有的MLLM架构,这使得MLLM能够使用与主流LLM相同的文本交叉熵损失来理解像素级信息。 - 其次,考虑到输入分辨率限制和模型架构未明确设计用于视觉任务,
MLLM在像素表达方面可能存在的潜在限制。进一步利用SAM增强输出,通过后处理MLLM的输出以相对简单的方式获得更高精度的分割掩码。 - 最后,为了在
SAM和MLLM之间建立联系,一种简单的方法是使MLLM生成SAM的提示点。利用LLM的对话能力,主动要求MLLM获取SAM的有效提示点。
SAM4MLLM解决了RES问题,使得MLLMs能够学习像素级的位置信息。将详细的视觉信息与大型语言模型强大的表达能力以统一的基于语言的方式结合起来,而在学习中没有额外的计算开销。
SAM4MLLM
编码分割掩码为SAM提示
现有的用于分割的MLLMs依赖于模型架构的专门设计、分割特定的token和异构损失函数来预测对象掩码。而SAM4MLLM利用了SAM的特点,将少量文本提示token(边界框加上几个指示它们是否位于对象区域的点)转换为高质量的连续分割掩码。
SAM4MLLM使用在边界框内采样的点作为离散提示。具体而言,使用一个边界框 \(Prompt_B \in \mathbb{N}^4\) 和 \(\mathcal{K}\) 个点来编码任意形状的掩码。 \(\mathcal{K}\) 个点的提示,每个点包含三个值: \(x\) 坐标、 \(y\) 坐标以及它是否在掩码上,编码为 \(Prompt_P \in \mathbb{N}^{\mathcal{K} \times 3}\) 。
通过将连续分割掩码编码为离散的SAM提示,避免了添加任何token或改变模型结构,同时仅使用文本自回归交叉熵损失进行训练。这种方法与语言模型的原始训练模式一致,使得MLLMs能够理解像素级信息,并促进未来的模型扩展变得更加容易。
使用MLLM提示SAM
为了将SAM以统一的方式纳入MLLM,一个主要问题在于获取SAM的提示点,包括在物体掩码区域内的正点(inside)和在外部的负点(outside)。为此,提出了两种解决方案:提示点生成(Prompt-Point Generation, PPG)和主动查询提示点(Proactive Query of Prompt-Points, PQPP)。
PPG直接采用MLLM来生成提示点和边界框,但同时生成多个点的学习将面临挑战,因此仅使用了少量提示点。PQPP则利用了MLLM的对话能力,首先询问一个粗略的边界框,然后通过问答的方式在边界框内探测多个感兴趣的点以提示SAM。
SAM4MLLM-PPG
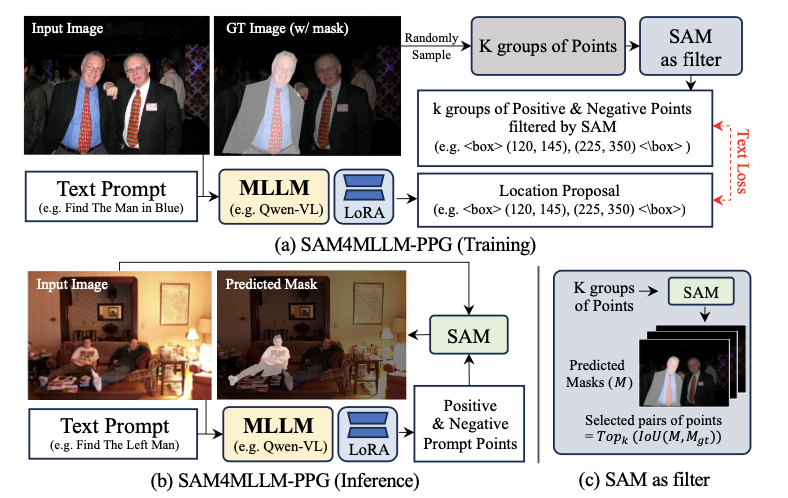
PPG采用了一种能够同时接受文本提示和图像输入的MLLM。为了使MLLM与分割任务对齐,使用了参数高效的微调技术LoRA,从而基于包含图像-文本对和真实掩码的RES数据集进行模型训练。LoRA输出位置提示,包括边界框 \(Prompt_B \in \mathbb{N}^4\) 和 \(k\) 组正点和负点 \(Prompt_P \in \mathbb{N}^{(n_1+n_2)k \times 3}\) ,如图 (a) 所示,其中一组包含 \(n_1\) 个正点和 \(n_2\) 个负点( \(n_1=2, n_2=1\) )。
为了向LoRA提供位置监督,在训练阶段根据物体掩码随机采样 \(K\) 组点( \(K>k\) ),然后将这些提示发送给SAM。对于每一组,SAM输出分割结果。过滤掉与真实掩码相比IoU较低的提示,仅保留前 \(k\) 组(如图 (c) 所示)。在该实现中,仅需要文本损失(自回归交叉熵损失)。\(K\) 通常为64, \(k=1\) 。
在推理阶段,LoRA直接输出发送给SAM进行分割的点,如图 (b) 所示。
SAM4MLLM-PQPP
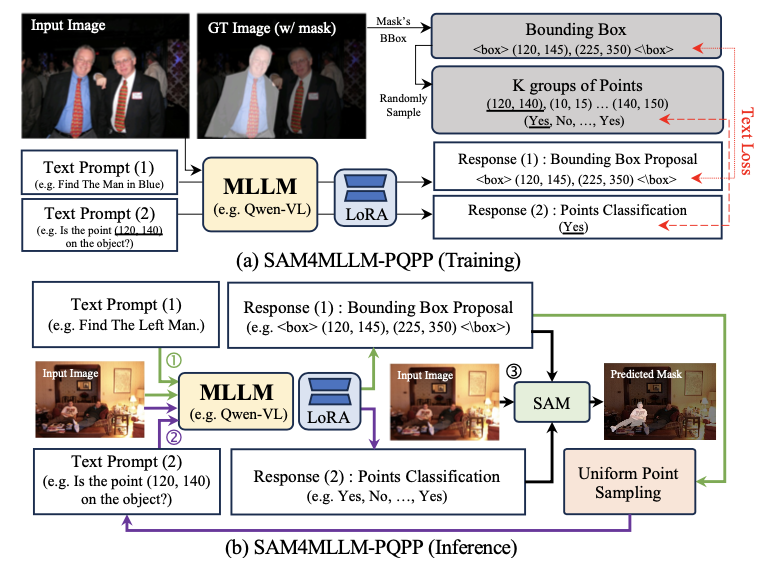
PQPP利用MLLM的查询-响应能力,而不是直接生成提示。对提示点进行采样,并主动询问MLLM这些点是否在掩码内(或外)。在训练阶段,根据真实掩码随机采样一个边界框和 \(K\) 组点,并进行两轮对话。在对话的第一轮中,LoRA响应一个边界框。在第二轮中,对于每个 \((n_1+n_2)K\) 个点,LoRA在训练期间响应该点是否在掩码内(是或否)。
在推理阶段,LoRA在第一轮中为输入的文本查询和图像输出一个边界框。然后,在边界框内均匀采样点并在第二轮再次发送给MLLM-LoRA,并询问它们是否为正点(或负点),用于SAM进行分割。通常将网格大小设置为 \(5\times 5\) 。为了在发送到SAM之前提供高质量的提示点,低置信度的点将被移除。
RES训练
为了使基础MLLM与RES任务对齐,使用包含与RES相关示例的三个数据集来指导模型朝目标前进。其中两个(RES数据集和gRefCOCO数据集)包含具有真实掩码的RES数据,第三个(VQA)是一个没有掩码的视觉对话数据集,用于进一步增强联合视觉-语言理解的总体能力。
在训练期间,为了保持MLLM在图像上的泛化能力,冻结了大部分网络参数,只调整了MLLM的视觉重采样器和LoRA适配器。
对于上述提到的所有数据集,我们在训练过程中不使用数据增强,因为翻转和/或裁剪可能会改变图像中物体的相对位置或关系。
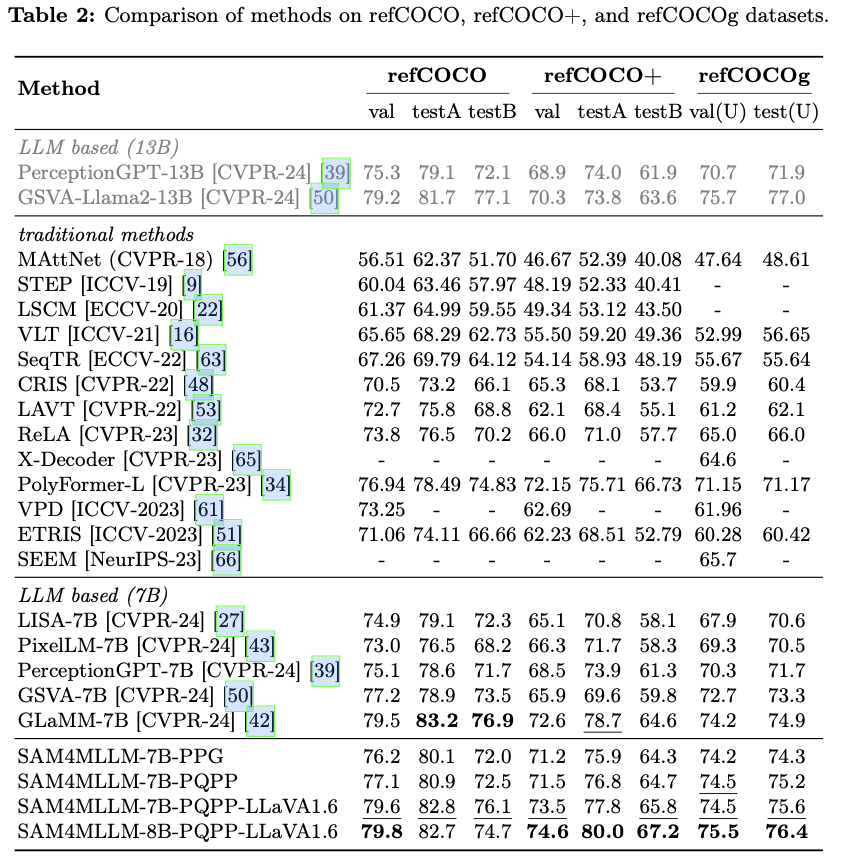
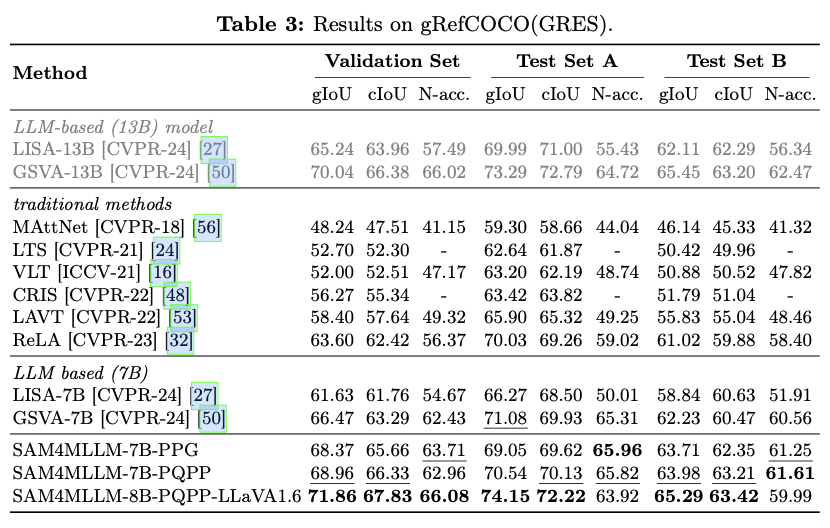
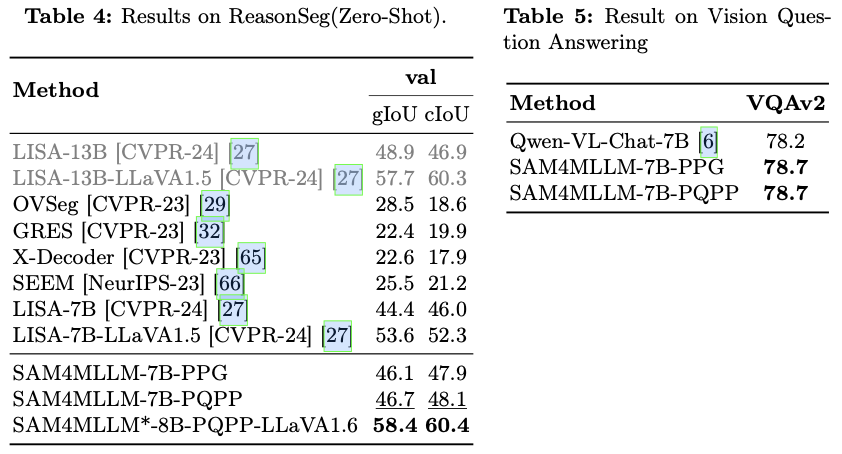
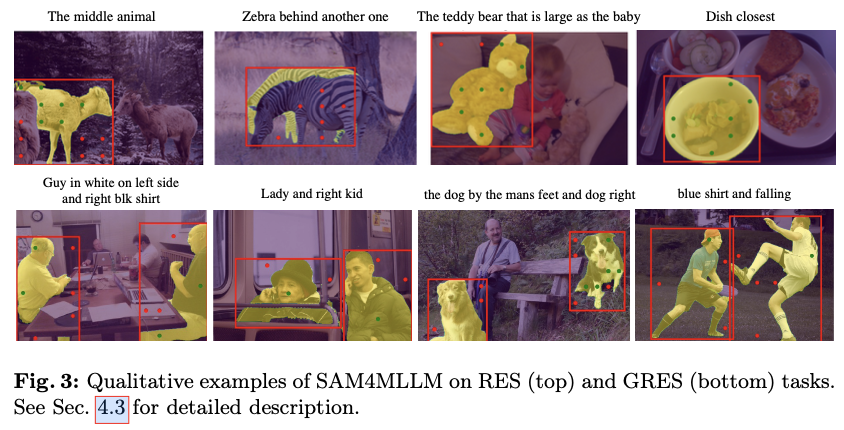
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

SAM4MLLM:结合多模态大型语言模型和SAM实现高精度引用表达分割 | ECCV'24的更多相关文章
- 贫血模型和DDD模型
贫血模型和DDD模型 1.贫血模型 1.1 概念 常见的mvc三层架构 简单.没有行为 2.领域驱动设计 2.1 概念(2004年提出的) Domain Driven Design 简称 DDD DD ...
- NOSQL数据模型和CAP原理
NOSQL数据模型和CAP原理 http://blog.sina.com.cn/s/blog_7800d9210100t33v.html 我本来一直觉得NoSQL其实很容易理解的,我本身也已经对NoS ...
- 系统间通信(5)——IO通信模型和JAVA实践 下篇
7.异步IO 上面两篇文章中,我们分别讲解了阻塞式同步IO.非阻塞式同步IO.多路复用IO 这三种IO模型,以及JAVA对于这三种IO模型的支持.重点说明了IO模型是由操作系统提供支持,且这三种IO模 ...
- Actor模型和CSP模型的区别
引用至:http://www.jdon.com/concurrent/actor-csp.html Akka/Erlang的actor模型与Go语言的协程Goroutine与通道Channel代表的C ...
- 基于JVM原理、JMM模型和CPU缓存模型深入理解Java并发编程
许多以Java多线程开发为主题的技术书籍,都会把对Java虚拟机和Java内存模型的讲解,作为讲授Java并发编程开发的主要内容,有的还深入到计算机系统的内存.CPU.缓存等予以说明.实际上,在实际的 ...
- 【Java】JMM内存模型和JVM内存结构
JMM内存模型和JVM内存结构 JAVA内存模型(Java Memory Model) Java内存模型,一般指的是JDK 5 开始使用的新的内存模型,主要由JSR-133: JavaTM Memor ...
- Java 内存模型和 JVM 内存结构真不是一回事
这两个概念估计有不少人会混淆,它们都可以说是 JVM 规范的一部分,但真不是一回事!它们描述和解决的是不同问题,简单来说, Java 内存模型,描述的是多线程允许的行为 JVM 内存结构,描述的是线程 ...
- JVM内存结构、Java内存模型和Java对象模型
Java作为一种面向对象的,跨平台语言,其对象.内存等一直是比较难的知识点.而且很多概念的名称看起来又那么相似,很多人会傻傻分不清楚.比如本文要讨论的JVM内存结构.Java内存模型和Java对象模型 ...
- 从零3D基础入门XNA 4.0(2)——模型和BasicEffect
[题外话] 上一篇文章介绍了3D开发基础与XNA开发程序的整体结构,以及使用Model类的Draw方法将模型绘制到屏幕上.本文接着上一篇文章继续,介绍XNA中模型的结构.BasicEffect的使用以 ...
- 网络知识学习1---(基础知识:ISO/OSI七层模型和TCP/IP四层模型)
以下的内容和之后的几篇博客只是比较初级的介绍,想要深入学习的话建议自己钻研<TCP/IP详解 卷1:协议> 1.ISO/OSI七层模型 下四层是为数据传输服务的,物理层是真正的传输数 ...
随机推荐
- 英文短句“xxx for the rest of us”的意思
"xxx for the rest of us" 这个短语通常被理解为"为我们所有人"或"为我们剩下的人".为了更好地理解这个短语的意义,我 ...
- 人形动画常见IK的处理
Unity中常见人形动画IK的处理方式 本文将尝试仅使用Untiy内置的Animator来解决常见的几种运动所需的IK.也会给出核心功能的代码实现. 效果一览:b站视频 Unity中人形角色的IK I ...
- c程序设计语言 by K&R(五)UNIX系统接口
一.文件描述符 在unix操作系统中,所有的外围设备(包括键盘和显示器)都被看作是文件系统的文件,因此,所有的输入.输出都要通过读/写文件来完成.也就是说,通过一个单一的接口就可以处理外围设备和程序之 ...
- ServiceMesh 1:大火的云原生微服务网格,究竟好在哪里?
1 关于云原生 云原生计算基金会(Cloud Native Computing Foundation, CNCF)的官方描述是: 云原生是一类技术的统称,通过云原生技术,我们可以构建出更易于弹性扩展. ...
- Angular 18+ 高级教程 – Animation 动画
前言 Angular 有一套 built-in 的 Animation 方案.这套方案的底层实现是基于游览器原生的 Web Animation API. CSS Transition -> CS ...
- CSS & JS Effect – FAQ Accordion & Slide Down
效果 参考: Youtube – Responsive FAQ accordion dropdown | HTML and CSS Tutorial 几个难点 1. 如何 align left for ...
- Identity – Custom Entity
扩展属性 Custom Entity 指的是我们想对 Identity 的几个 Entity 做修改. 比如 User 要多一些 property, 或者 Id 用 int 而不是默认的 GUID. ...
- SpringMVC —— 入门案例执行流程
启动服务器初始化过程 1.服务器启动,执行ServletContainersInitConfig类,初始化web容器 2.执行createServletApplicationContext方法, ...
- Servlet——Response对象
Response对象 Response 设置响应数据 1.响应行 void setStatus(int sc):设置响应状态码 2.响应头 ...
- k8s StorageClass 存储类
目录 一.概述 1.StorageClass 对象定义 2.StorageClass YAML 示例 二.StorageClass 字段 1.provisioner(存储制备器) 1.1.内置制备器 ...