Hadoop生态系统介绍
Hadoop1.x 的各项目介绍
1. HDFS
2. MapReduce
3. Hive
4. Pig
5. Mahout
6. ZooKeeper
7. HBase
8. Sqoop
9. Flume
10. Ambari
Hadoop生态系统
当今的Hadoop已经成长为一个庞大的体系,只要有和海量数据相关的领域。都有Hadoop的身影。
Hadoop生态系统图谱
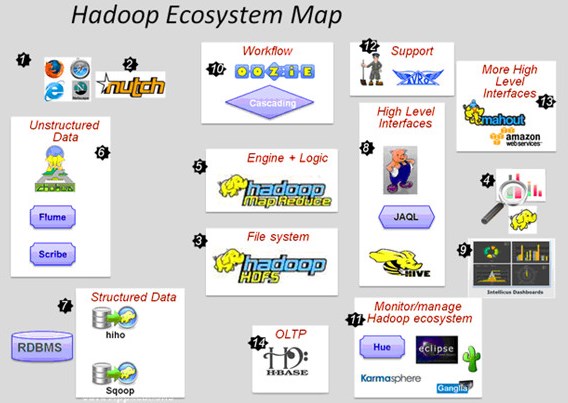
大家知道,Hadoop的两大核心就是HDFS和MapReduce,而整个Hadoop的体系结构主要是通过HDFS的分布式存储作为底层数据支持的。并且会通过MapReduce来进行计算分析。
Hadoop1.x的核心:
- Hadoop Common
- Hadoop Distributed File System(HDFS)
- Hadoop MapReduce
Hadoop2.x的核心:
- Hadoop Common
- Hadoop Distributed File System(HDFS)
- Hadoop MapReduce
- Hadoop YARN
Hadoop1.x 生态系统图
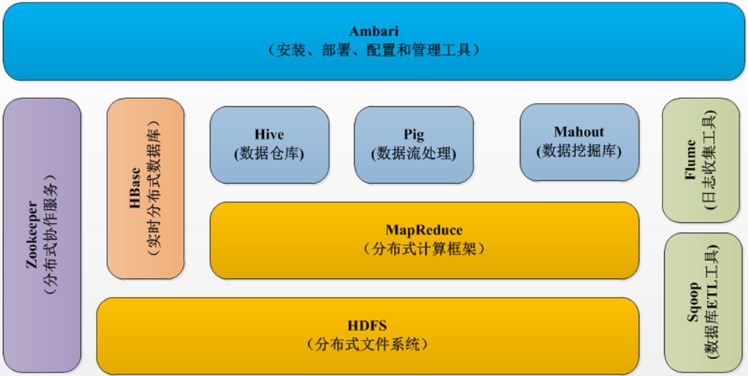
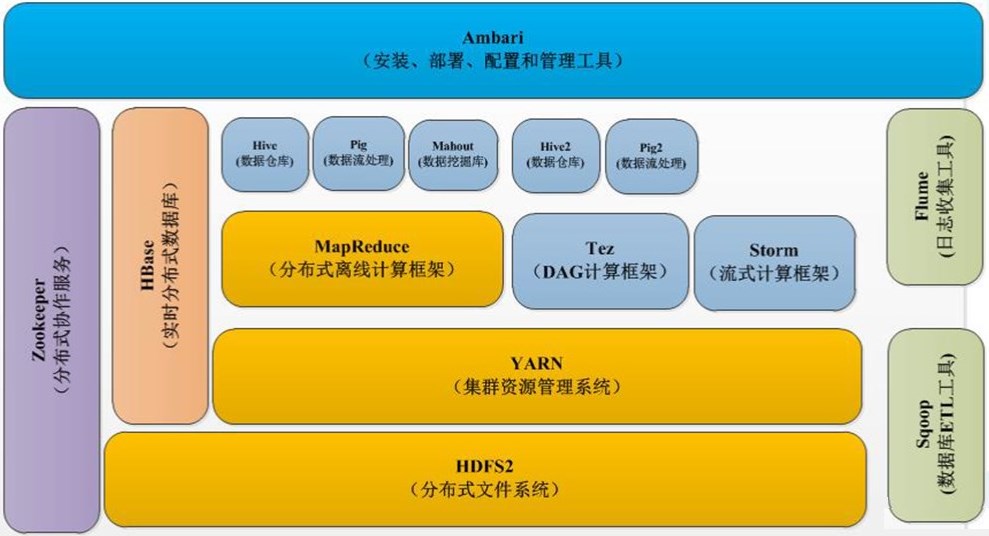
Hadoop2.x 生态系统图
Hadoop1.x 的各项目介绍
1. HDFS
分布式文件系统,将一个文件分成多个块,分别存储(拷贝)到不同的节点上.它是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
2. MapReduce
分布式计算框架,它是一种分布式计算处理模型和执行环境,用于进行大数据量的计算。共包括Map和Reduce部分。其中Map接受一个键值对(key-value),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。Reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
3. Hive
基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类似SQL一样的查询语言HiveQL来管理这些数据。Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
4. Pig
Pig是一个基于Hadoop的大数据分析平台,它提供了一个叫PigLatin的高级语言来表达大数据分析程序,将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
5. Mahout
数据挖掘算法库,Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
6. ZooKeeper
分布式协作服务,是一个针对大型分布式系统的可靠协调系统,提供包括配置维护,名字服务,分布式同步和组服务等功能。Hadoop的管理就是用的ZooKeeper
7. HBase
HBase是一个分布式列存数据库,它基于Hadoop之上提供了类似BigTable的功能。HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
8. Sqoop
数据同步工具,SQL-to-Hadoop的缩写。Sqoop是一个Hadoop和关系型数据库之间的数据转移工具。可将关系型数据库中的数据导入到Hadoop的HDFS中,也可将HDFS中的数据导进到关系型数据库中主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
9. Flume
日志收集工具,Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
10. Ambari
是一个对Hadoop集群进行监控和管理的基于Web的系统。目前已经支持HDFS,MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop等组件。
Hadoop生态系统介绍的更多相关文章
- 安装高可用Hadoop生态 (一 ) 准备环境
为了学习Hadoop生态的部署和调优技术,在笔记本上的3台虚拟机部署Hadoop集群环境,要求保证HA,即主要服务没有单点故障,能够执行最基本功能,完成小内存模式的参数调整. 1. 准备环境 1 ...
- 基于Hadoop生态SparkStreaming的大数据实时流处理平台的搭建
随着公司业务发展,对大数据的获取和实时处理的要求就会越来越高,日志处理.用户行为分析.场景业务分析等等,传统的写日志方式根本满足不了业务的实时处理需求,所以本人准备开始着手改造原系统中的数据处理方式, ...
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别 Pig
Hadoop生态上几个技术的关系与区别:hive.pig.hbase 关系与区别 Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎自己慢慢退出pig的 ...
- Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现. (1)0.20.0~0.20.2: Hadoop的0.20分支非常稳定,虽然看起来有些落后,但是经过生产环境考验,是 Hadoop历史上 ...
- Hadoop生态常用数据模型
Hadoop生态常用数据模型 一.TextFile 二.SequenceFile 1.特性 2.存储结构 3.压缩结构与读取过程 4.读写操作 三.Avro 1.特性 2.数据类型 3.avro-to ...
- Hadoop生态优秀文章集锦
如何用形象的比喻描述大数据的技术生态?Hadoop.Hive.Spark 之间是什么关系? https://www.zhihu.com/question/27974418 HBase 和 Hive 的 ...
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
初接触Hadoop技术的朋友肯定会对它体系下寄生的个个开源项目糊涂了,我敢保证Hive,Pig,HBase这些开源技术会把你搞的有些糊涂,不要紧糊涂的不止你一个,如某个菜鸟的帖子的疑问,when to ...
- hadoop生态之mapReduce-Yarn
一.inputSplit 1.什么是block 块是以 block size 进行划分数据. 因此,如果群集中的 block size 为 128 MB,则数据集的每个块将为 128 MB,除非最后一 ...
- Hadoop生态组件Hive,Sqoop安装及Sqoop从HDFS/hive抽取数据到关系型数据库Mysql
一般Hive依赖关系型数据库Mysql,故先安装Mysql $: yum install mysql-server mysql-client [yum安装] $: /etc/init.d/mysqld ...
随机推荐
- Web开发:URL编码与解码(转)
原文:http://www.cnblogs.com/greatverve/archive/2011/12/12/URL-Encoding-Decoding.html 通常如果一样东西需要编码,说明这样 ...
- Oracle监控的关键指标
1.监控事例的等待 select event, , , )) "Prev", , , )) "Curr", count(*) "Tot" f ...
- Spring Boot+CXF搭建WebService
Spring Boot WebService开发 需要依赖Maven的Pom清单 <?xml version="1.0" encoding="UTF-8" ...
- 站点默认访问https
需求简介 现在网站都是https访问了,再用http会显得很low,所以我要把网站设置为默认的https访问. 1nginx的rewrite方法 这应该是大家最容易想到的方法,将所有的http请求通过 ...
- The adidas NMD Camo Singapore consists of four colorways
Next within the popular selection of the adidas NMD Singapore is really a clean all-black form of th ...
- cocos代码研究(13)Widget子类EditBox学习笔记
理论基础 一个用来输入文本的类,继承自 Widget , 以及 IMEDelegate. 代码部分 Public枚举类型 enum KeyboardReturnType键盘的返回键类型. enum I ...
- wkhtmtopdf--高分辨率HTML转PDF(三)
代码篇 浏览了很多实例,总找不到既能把HTML保存为PDF,同时实现流抛出的,所以自己琢磨了许久,终于实现了这样两个需求的结合体,下面来贡献一下吧~~ 下面我们来选择一个网页打印下,保存为PDF,而且 ...
- pycharm添加git ignore
pycharm现在提供了git ignore,很方便 从这里下载扩展 https://plugins.jetbrains.com/plugin/7495--ignore 放到pycharm根目录\pl ...
- 如何把本地git仓库托管到码云上
提交代码到本地git仓库 git init git status git add . git status git commit -m "init my project" ...
- ubuntu16.04安装tensorflow官方教程与机器学习资料【学习笔记】
tensorflow官网有官方的安装教程:https://www.tensorflow.org/install/install_linux google的机器学习官方快速入门教程:https://de ...