Keras函数式 API
用Keras定义网络模型有两种方式,
之前我们介绍了Sequential顺序模型,今天我们来接触一下 Keras 的函数式API模型。
函数式API:全连接网络
from keras.layers import Input, Dense
from keras.models import Model # 这部分返回一个张量
inputs = Input(shape=(784,)) # 层的实例是可调用的,它以张量为参数,并且返回一个张量
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x) # 这部分创建了一个包含输入层和三个全连接层的模型
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels,batch_size=32, epochs=5) # 开始训练
多输入多输出模型
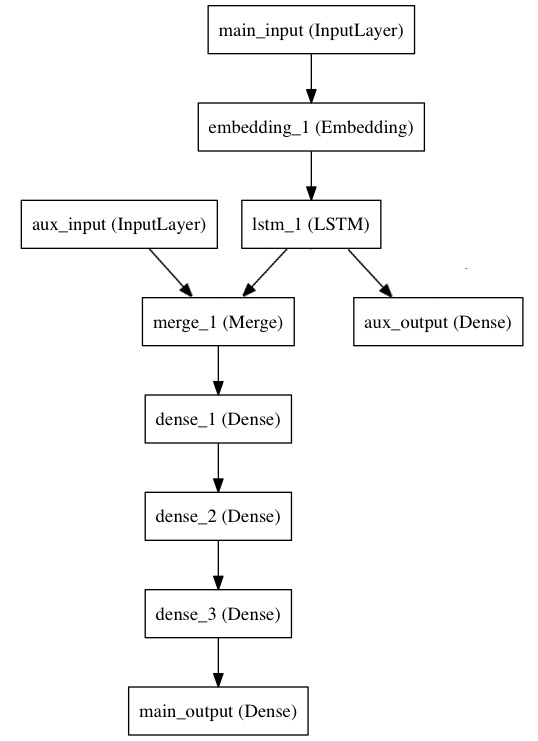
主要负责用函数式API来实现它
主要输入接收新闻标题本身,即一个整数序列(每个证书编码一个词),这些整数在1到10000之间(10000个词的词汇表),且序列长度为100个词
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model # 标题输入:接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间。
# 注意我们可以通过传递一个 "name" 参数来命名任何层。
main_input = Input(shape=(100,), dtype='int32', name='main_input') # Embedding 层将输入序列编码为一个稠密向量的序列,
# 每个向量维度为 512。
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input) # LSTM 层把向量序列转换成单个向量,
# 它包含整个序列的上下文信息
lstm_out = LSTM(32)(x)
在这里,我们插入辅助损失,即使在模型主损失很高的情况下,LSTM层和Embedding层都能被平稳地训练。
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
此时,我们将辅助输入数据与 LSTM 层的输出连接起来,输入到模型中:
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input]) # 堆叠多个全连接网络层
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x) # 最后添加主要的逻辑回归层
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
然后定义一个具有两个输入和两个输出的模型:
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
现在编译模型,并给辅助损失分配一个 0.2 的权重。如果要为不同的输出指定不同的 loss_weights 或 loss,可以使用列表或字典。 在这里,我们给 loss 参数传递单个损失函数,这个损失将用于所有的输出。
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
我们可以通过输入数组和目标数组的列表来训练模型:
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
由于输入和输出均被命名了(在定义时传递了一个 name 参数),我们也可以通过以下方式编译模型:
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2}) # 然后使用以下方式训练:
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)
共享网络层
函数API的另一个用途是使用共享网络层的模型。
比如我们想建立一个模型来分辨两条推文是否来自同一个人,实现这个目标的方法是:将两条推文编码层两个向量,连接向量,然后添加逻辑回归层;这将输出推文来自通一个作者的概率。模型将接受一对对正负表示的推特数据。
太难了,我理解不了。以后这条博客慢慢更新。
Keras函数式 API的更多相关文章
- keras函数式编程(多任务学习,共享网络层)
https://keras.io/zh/ https://keras.io/zh/getting-started/functional-api-guide/ https://github.com/ke ...
- 手写数字识别——利用keras高层API快速搭建并优化网络模型
在<手写数字识别——手动搭建全连接层>一文中,我们通过机器学习的基本公式构建出了一个网络模型,其实现过程毫无疑问是过于复杂了——不得不考虑诸如数据类型匹配.梯度计算.准确度的统计等问题,但 ...
- 【小白学PyTorch】21 Keras的API详解(下)池化、Normalization层
文章来自微信公众号:[机器学习炼丹术].作者WX:cyx645016617. 参考目录: 目录 1 池化层 1.1 最大池化层 1.2 平均池化层 1.3 全局最大池化层 1.4 全局平均池化层 2 ...
- TensorFlow 1.4利用Keras+Estimator API进行训练和预测
Tensorflow 1.4中,Keras作为作为核心模块可以直接通过tf.keas进行调用,但是考虑到keras对tfrecords文件进行操作比较麻烦,而将keras模型转成tensorflow中 ...
- 【小白学PyTorch】21 Keras的API详解(上)卷积、激活、初始化、正则
[新闻]:机器学习炼丹术的粉丝的人工智能交流群已经建立,目前有目标检测.医学图像.时间序列等多个目标为技术学习的分群和水群唠嗑答疑解惑的总群,欢迎大家加炼丹兄为好友,加入炼丹协会.微信:cyx6450 ...
- 小白如何学习PyTorch】25 Keras的API详解(下)缓存激活,内存输出,并发解决
[新闻]:机器学习炼丹术的粉丝的人工智能交流群已经建立,目前有目标检测.医学图像.时间序列等多个目标为技术学习的分群和水群唠嗑答疑解惑的总群,欢迎大家加炼丹兄为好友,加入炼丹协会.微信:cyx6450 ...
- Keras高层API之Metrics
在tf.keras中,metrics其实就是起到了一个测量表的作用,即测量损失或者模型精度的变化.metrics的使用分为以下四步: step1:Build a meter acc_meter = m ...
- 深度学习框架: Keras官方中文版文档正式发布
今年 1 月 12 日,Keras 作者 François Chollet 在推特上表示因为中文读者的广泛关注,他已经在 GitHub 上展开了一个 Keras 中文文档项目.而昨日,Françoi ...
- 3.keras实现-->高级的深度学习最佳实践
一.不用Sequential模型的解决方案:keras函数式API 1.多输入模型 简单的问答模型 输入:问题 + 文本片段 输出:回答(一个词) from keras.models import M ...
随机推荐
- 代理模式:利用JDK原生动态实现AOP
代理模式:利用JDK原生动态实现AOP http://www.cnblogs.com/qiuyong/p/6412870.html 1.概述 含义:控制对对象的访问. 作用:详细控制某个(某类)某对象 ...
- Codeforces Round #275 (Div. 2) A,B,C,D
A. Counterexample time limit per test 1 second memory limit per test 256 megabytes input standard in ...
- dynamic load javascript file.
$.ajax({ url : ("js/public/" + window.localStorage.getItem("lang") + ".js&q ...
- Spark读取结构化数据
读取结构化数据 Spark可以从本地CSV,HDFS以及Hive读取结构化数据,直接解析为DataFrame,进行后续分析. 读取本地CSV 需要指定一些选项,比如留header,比如指定delimi ...
- 雷林鹏分享:Ruby 文件的输入与输出
Ruby 文件的输入与输出 Ruby 提供了一整套 I/O 相关的方法,在内核(Kernel)模块中实现.所有的 I/O 方法派生自 IO 类. 类 IO 提供了所有基础的方法,比如 read. wr ...
- SCWS中文分词PHP扩展详细安装说明
因最近写的一段代码,需要用到中文分词,在网上找了一下,发现了scws这个不错的插件,故根据文档安装使用,下面记录下安装的全过程 系统:centos 安装scws wget http://www.xun ...
- 移动web开发适配方案之Rem
移动端为什么要做适配 移动端相对PC端来说大部分浏览器内核都是基于Webkit的,所以大部分都支持CSS3的最新语法.但是由于手机的屏幕尺寸和分辨率都不太一样(尤其是安卓),所以不得不对不同分辨率的手 ...
- [转载]LeetCode: Gray Code
The gray code is a binary numeral system where two successive values differ in only one bit. Given a ...
- 用halcon提取衣服徽章
收到一封email,有个学员求助去除衣服上纹理的干扰,然后提取衣服上徽章的边缘的方法. 我想他肯定是个很努力上进的boy,在求助以前也许已经试过各种方法,通过二值化不断的调试阈值, 寻找各种边 ...
- phpstudy2017版本的nginx 支持laravel 5.X配置
之前做开发和学习一直用phpstudy的mysql服务,确实很方便,开箱即用.QQ群交流:697028234 现在分享一下最新版本的phpstudy2017 laravel环境配置. 最新版的phps ...