HashMap的扩容机制以及默认大小为何是2次幂
回顾HashMap的put(Key k, Value v)过程:
(1)对 Key求Hash值,对n-1取模计算出Hash表数组下标
(2)如果没有碰撞,直接放入桶中,即Hash表数组对应位置的链表表头。
(3)如果碰撞了,若节点已经存在就替换旧值,否则以链表的方式将该元素链接到后面。
(4)如果链表长度超过阀值(TREEIFY_THRESHOLD == 8),就把链表转成红黑树。红黑树我不熟悉,这里不展开讲。
(5)如果桶满了(容量 * 加载因子),就需要resize。
HashMap的扩容机制
假设length为Hash表数组的大小,方法indexFor(int hash, int length)为
indexFor(int hash, int length) {
return hash % length;
}
在旧数组中同一条Entry链上的元素,在resize过程中,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。JDK8做了一些优化,resize过程中对Hash表数组大小的修改使用的是2次幂的扩展(指长度扩为原来2倍),这样有2个好处。
好处1
在hashmap的源码中。put方法会调用indexFor(int h, int length)方法,这个方法主要是根据key的hash值找到这个entry在Hash表数组中的位置,源码如下:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
上述代码也相当于对length求模。 注意最后return的是h&(length-1)。如果length不为2的幂,比如15。那么length-1的2进制就会变成1110。在h为随机数的情况下,和1110做&操作。尾数永远为0。那么0001、1001、1101等尾数为1的位置就永远不可能被entry占用。这样会造成浪费,不随机等问题。 length-1 二进制中为1的位数越多,那么分布就平均。
好处2
以下图为例,其中图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,n代表length。
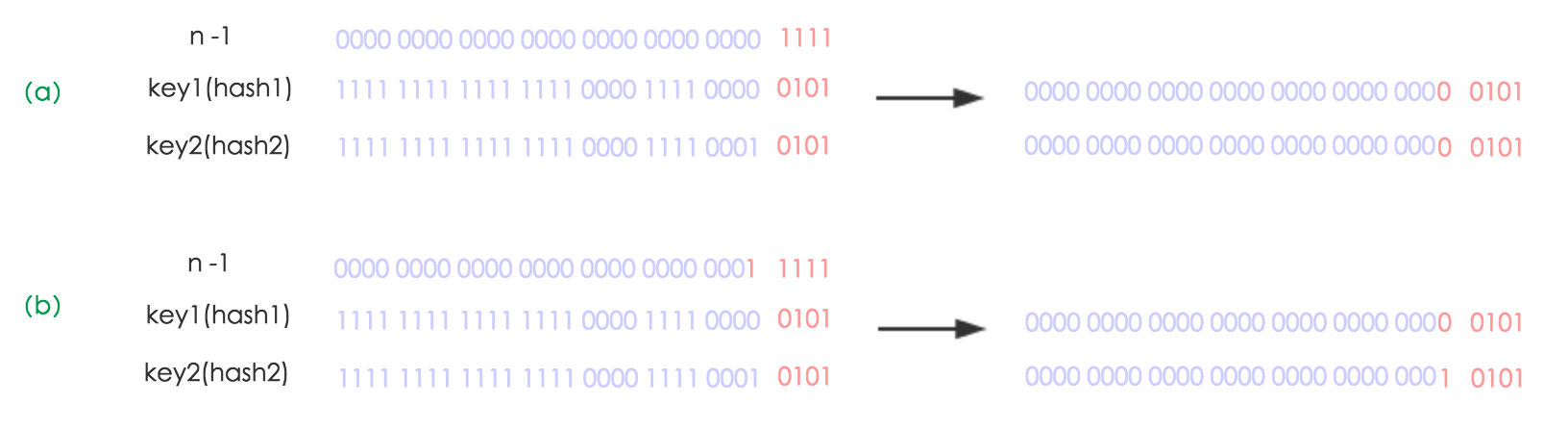
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
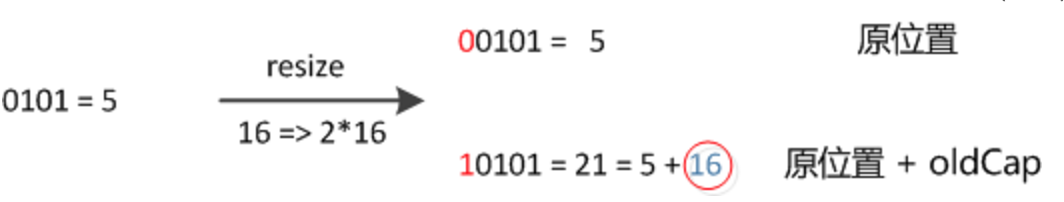
resize过程中不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图(一方面位运算更快,另一方面抗碰撞的Hash函数其实挺耗时的):

源码如下
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order 链表优化重hash的代码块
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap的扩容机制以及默认大小为何是2次幂的更多相关文章
- 深入理解HashMap的扩容机制
什么时候扩容: 网上总结的会有很多,但大多都总结的不够完整或者不够准确.大多数可能值说了满足我下面条件一的情况. 扩容必须满足两个条件: 1. 存放新值的时候当前已有元素的个数必须大于等于阈值 2. ...
- HashMap自动扩容机制源码详解
一.简介 HashMap的源码我们之前解读过,数组加链表,链表过长时裂变为红黑树.自动扩容机制没细说,今天详细看一下 往期回顾: Java1.7的HashMap源码分析-面试必备技能 Java1.8的 ...
- HashMap的扩容机制, ConcurrentHashMap和Hashtable主要区别
源代码查看,有三个常量, static final int DEFAULT_INITIAL_CAPACITY = 16; static final int MAXIMUM_CAPACITY = 1 & ...
- HashMap的扩容机制---resize()
虽然在hashmap的原理里面有这段,但是这个单独拿出来讲rehash或者resize()也是极好的. 什么时候扩容:当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值---即当前数组 ...
- HashMap原理(二) 扩容机制及存取原理
我们在上一个章节<HashMap原理(一) 概念和底层架构>中讲解了HashMap的存储数据结构以及常用的概念及变量,包括capacity容量,threshold变量和loadFactor ...
- 面试题: Java中各个集合类的扩容机制
个人博客网:https://wushaopei.github.io/ (你想要这里多有) Java 中提供了很多的集合类,包括,collection的子接口list.set,以及map等.由于它 ...
- JDK1.8前_HashMap的扩容机制原理
最近在研究hashmap的扩容机制,作为一个小白,相信我的理解,对于一些同样是刚刚接触hashmap的白白是有很很大的帮助,毕竟你去看一些已经对数据结构了解透彻的大神谈hashmap的原理等,人家说的 ...
- 浅谈JAVA中HashMap、ArrayList、StringBuilder等的扩容机制
JAVA中的部分需要扩容的内容总结如下:第一部分: HashMap<String, String> hmap=new HashMap<>(); HashSet<Strin ...
- Java常见集合的默认大小及扩容机制
在面试后台开发的过程中,集合是面试的热话题,不仅要知道各集合的区别用法,还要知道集合的扩容机制,今天我们就来谈下ArrayList 和 HashMap的默认大小以及扩容机制. 在 Java 7 中,查 ...
随机推荐
- 20170607 JDBC课堂实践 任务四
20170607 JDBC课堂实践 任务四 题目 查询world数据库,查询哪个国家的平均寿命最长. 码云链接 SQL语句 SELECT Code, Name, LifeExpectancy FROM ...
- 2017-2018-1 20155307 《信息安全系统设计基础》第十周课上未完成补充以及课下IPC作业
课上内容2:stat命令的实现-mysate 学习使用stat(1),并用C语言实现 提交学习stat(1)的截图 man -k ,grep -r的使用 伪代码 产品代码 mystate.c,提交码云 ...
- LVS入门篇(一)之ARP协议
1.概念 地址解析协议,即ARP(AddressResolutionProtocol),是根据IP地址获取物理MAC地址的一个TCP/IP协议.主机发送信息时将包含目标IP地址的ARP请求广播到网络上 ...
- HTTP 两种基本请求方法 GET和 POST的区别
GET方法 1.GET交互方式是从服务器上获取数据,而并非修改数据,所以GET交互方式是安全的.就像数据库查询一样,从数据库查询数据,并不会影响数据库的数据信息,对数据库来说,也就是安全的.2.GET ...
- CTF--zip伪加密
刷题 一.BUGKU WEB 1. 变量1 知识点php两个$$是 可变变量,就是一个变量的变量名可以动态的设置和使用 $GLOBALS一个包含了全部变量的全局组合数组.变量的名字就是数组的键 < ...
- 算法笔记(c++)--桶排序题目
算法笔记(c++)--桶排序 记得题目是排序,输入n个1-1000的数字然后去重然后排序. 桶排序没毛病 #include<iostream> using namespace std; i ...
- sql注入waf绕过简单入门
0x1 白盒 0x2 黑盒 一.架构层 1.寻找源站==> 2.利用同网段==> 3.利用边界漏洞==> ssrf只是一个例子 二.资源限制 Waf为了保证业务运行,会忽略对大的数 ...
- 简单主机批量管理工具(这里实现了paramiko 用su切换到root用户)
项目名:简单主机批量管理工具 一.需求 1.主机分组 2.可批量执行命令.发送文件,结果实时返回,执行格式如下 batch_run -h h1,h2,h3 -g web_clusters,db_ ...
- ASP.NET 异步Web API + jQuery Ajax 文件上传代码小析
该示例中实际上应用了 jquery ajax(web client) + async web api 双异步. jquery ajax post $.ajax({ type: "POST&q ...
- Linux下文件的打包、解压缩指令——tar,gzip,bzip2
本文是对 鸟叔的Linux私房菜(基础学习篇) 第三版 的学习笔记,原文可参考原书中文网站 鸟叔的Linux私房菜.更多详细信息可直接参考对应Linux命令的 man 帮助( 如 man tar). ...