Hadoop集群搭建:用三台云服务器搭建HA集群(过程记录和分享)
该文主要记录了自己用云服务器搭建集群的过程,也分享一些自己遇到的问题和解决方法。里面可能提及一些自己的理解,可能不够准确,希望大家能够指正我,谢谢。
1.什么是HA集群
HA :High Available
问题:对于只有一个namenode的集群,如果namenode的集群出现故障,集群将无法使用直到重新启动。
方法:开启HDFS的HA功能,通过在不同节点上设置Active/Standby两个namenode,当其中一个出现故障,可以很快的把namenode切换到另外一台机器(同时只有一个namenode处于Active状态)。为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog),需提 供一个共享存储系统,可以是 NFS、QJM(Quorum Journal Manager)或者 Zookeeper,Active Namenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写入,则 读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持基本一 致,如此这般,在紧急情况下 standby 便可快速切为 active namenode。为了实现快速切换,Standby 节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标,DataNode 需要配置 NameNodes 的位置,并同时给他们发送文件块信息以及心跳检测。
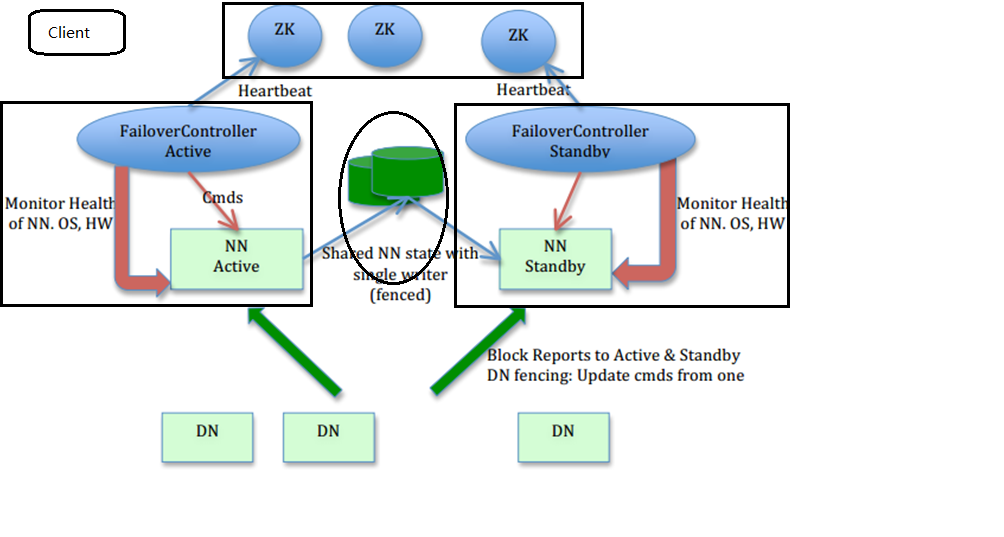
2.集群规划
三台DigitalOcean的1G内存的服务器,系统是Ubuntu 16.04.4(内存只有1G,所以配置文件中内存分配必须根据实际设置,不能使用默认值),三台组成一个Zookeeper集群(奇数且最少三台)。hadoop1和hadoop2作为namenode的主备切换,hadoop3运行resourcemanager,因为机器性能限制,namenode和resourcemanager都要占用大量资源,所以把他们分开了。而且在这里,没有启用RM的高性能模式。

3.服务器准备(注意每台机器使用的用户名必须相同,在这里我全是root用户)
3.0 修改主机名和ip-hostname映射关系
主要是修改 /etc/hostname 和 /etc/hosts 两个文件。关于修改hostname是不是必要这个问题,我刚开始是直接用的Ip地址,但是会发现HDFS里面有很多函数方法都会首先默认取主机名,从而会有很多Error出现。况且通过配置ip和主机名的映射关系,配置文件的修改会更加的方便。
a.分别在三台机器的/etc/hostname文件修改主机名,分别取名为hadoop1,hadoop2,hadoop3 。
b.在每台机器的 /etc/hosts 文件中中添加Ip和主机名的映射关系。关于这里的Ip是公网ip还是内网ip的问题,这个问题我觉得不能一刀切。一般情况下使用的是内网Ip,但是DigitalOcean的服务器自己 ping 自己的内网Ip是ping不通的,但是公网却能够ping 通。所以我在这里的ip使用的是公网Ip。Ip是公网的还是内网的涉及到不同的zookeeper的配置,所以配置时候得根据实际情况。
Ip1 hadoop1
Ip2 hadoop2
Ip3 hadoop3
3.1 ssh免登陆配置
在每台服务器的/root/.ssh/ 目录中,执行如下命令生成一对密钥,并将本地主机的公钥添加到远程主机的authorized_keys文件上。三台机器两两双向进行配置,注意包括自己对自已。
ssh-keygen -t rsa
ssh-copy-id ip
3.2 Java环境安装
apt-get install openjdk--jre
3.3 Hadoop(每台服务器Hadoop的安装目录必须一致,安装包的配置信息也必须一致)
在 /root/目录中,执行以下命令下载Hadoop安装包,然后解压到当前目录 tar -zxvf hadoop-3.8..tar.gz -C /root/ 。我安装的版本是2.8.4。也可以只现在一台服务器上安装并配置好,然后复制到其他服务器上。
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.4/hadoop-2.8.4.tar.gz
3.4 Zookeeper
在每台服务器的 /root/目录中,执行以下命令下载Zookeeper安装包,然后解压到当前目录tar -zxvf zookeeper-3.4.12tar.gz -C /root/ 。也可以在一台服务器上安装并配置好,然后复制到其他服务器上。但是zookeeper的配置文件每台服务器不同注意修改。
wget https://zookeeper.apache.org/releases.html#download
3.5 添加环境变量
在每台服务器的 /etc/profile 文件最后添加hadoop,java和zookeeper的路径。然后,执行 source /etc/profile 命令后生效。
export JAVA_HOME=/usr/lib/jvm/java--openjdk-amd64/jre
export HADOOP_HOME=/root/hadoop-2.8.
export ZOOKEEPER_HOME=/root/zookeeper-3.4.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
4.配置文件的修改(配置文件分别位于root/hadoop-2.8.4/etc/hadoop和root/zookeeper-3.4.12/conf)
4.1 hadoop-env.sh
将25行左右的那一行替换成如下语句
export JAVA_HOME=/usr/lib/jvm/java--openjdk-amd64/jre
4.2 core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns(任取)-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.8./tmp</value>
</property>
<!--流文件的缓冲区单位KB>
<property>
<name>io.file.buffer.size</name>
<value></value>
</property>
<!-- 指定zookeeper集群的地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:,hadoop2:,hadoop3:</value>
</property>
</configuration>
4.3 hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1, nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop1:</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop1:</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop2:</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop2:</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/hadoop-2.8./journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value></value>
</property>
<!--设置副本数为2>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
4.4 mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--map任务内存大小,默认1G-->
<property>
<name>mapreduce.map.memory.mb</name>
<value></value>
</property>
<!--reduce任务内存大小,默认1G-->
<property>
<name>mapreduce.reduce.memory.mb</name>
<value></value>
</property>
<!--map任务运行的JVM进程内存大小,默认-Xmx200M-->
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx184m</value>
</property>
<!--reduce任务运行的JVM进程内存,默认-Xmx200M-->
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx368m</value>
</property>
<!--MR AppMaster运行需要内存,默认1536M-->
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value></value>
</property>
<!--MR AppMaster运行的JVM进程内存,默认-Xmx1024m-->
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx368m</value>
</property>
</configuration>
4.5 yarn-site.xml
<configuration>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop3</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:,hadoop2:,hadoop3:</value>
</property>
<>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--RM中分配容器的内存最小值,默认1G-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value></value>
</property>
<!--RM中分配容器的内存最大值,默认8G-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value></value>
</property>
<!--可用物理内存大小,默认8G-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value></value>
</property>
<!--虚拟内存检查是否开始>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
4.6 slaves
在每台服务器的slaves文件中配置集群Datanode的主机名,只有这个文件里面的主机名才能被Namenode识别。
hadoop1
hadoop2
hadoop3
4.7 zoo.cfg 和 myid
首先重命名zoo_sample.cfg文件为zoo.cfg,并按如下修改文件。
#修改
dataDir=/root/zookeeper-3.4./data
dataLogDir=/root/zookeeper-3.4./datalog #末尾添加(内网IP)
server.=hadoop1::
server.=hadoop2::
server.=hadoop3::
但是如果使用的是公网IP的时候,注意把本机配置为0.0.0.0。假设我们现在在hadoop1节点上,且使用的是公网IP,则应该如下配置
#末尾添加
server.=0.0.0.0::
server.=165.227.133.86::
server.=159.65.120.185::
保存退出后。在/root/zookeeper-3.4.12/目录下,创建data和datalog两个目录,并在data目录下面创建myid文件并添加内容。在三台服务器中的myid的内容分别是1,2,3(对应server.xx)。
例如,在Hadoop1服务器上执行命令 echo > myid 。
5.集群启动(严格按照下面步骤)
5.1 在三个节点上执行如下命令启动zookeeper,并分别查看节点状态,正常情况下一个leader和两个follower。
root@hadoop1:~# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4./bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@hadoop1:~/zookeeper-3.4.12# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: leader
5.2 在hadoop1上启动journalnode集群 hadoop-daemons.sh start journalnode (注意是复数版本的)。用jps检验三个节点多了JournalNode进程。
5.3 在hadoop1上格式化HDFS hdfs namenode -format 。格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,在这里是存在 /root/hadoop-2.8.4/tmp 的目录下。然后将这个文件拷贝到hadoop2的 /root/hadoop-2.8.4/ 目录下 scp -r tmp/ root@hadoop2:/root/hadoop-2.8./ 。
5.4 在hadoop1上格式化ZK hdfs zkfc -formatZK 。
5.5 在hadoop1上启动HDFS start-dfs.sh 。
5.6 在hadoop3上启动Yarn start-yarn.sh 。
5.7 用jps查看进程
#hadoop1和hadoop2
root@hadoop1:~/hadoop-2.8.# jps
NodeManager
JournalNode
Jps
DataNode
DFSZKFailoverController
NameNode
QuorumPeerMain #hadoop3
root@hadoop3:~# jps
QuorumPeerMain
ResourceManager
DataNode
Jps
JournalNode
NodeManager
6.集群测试
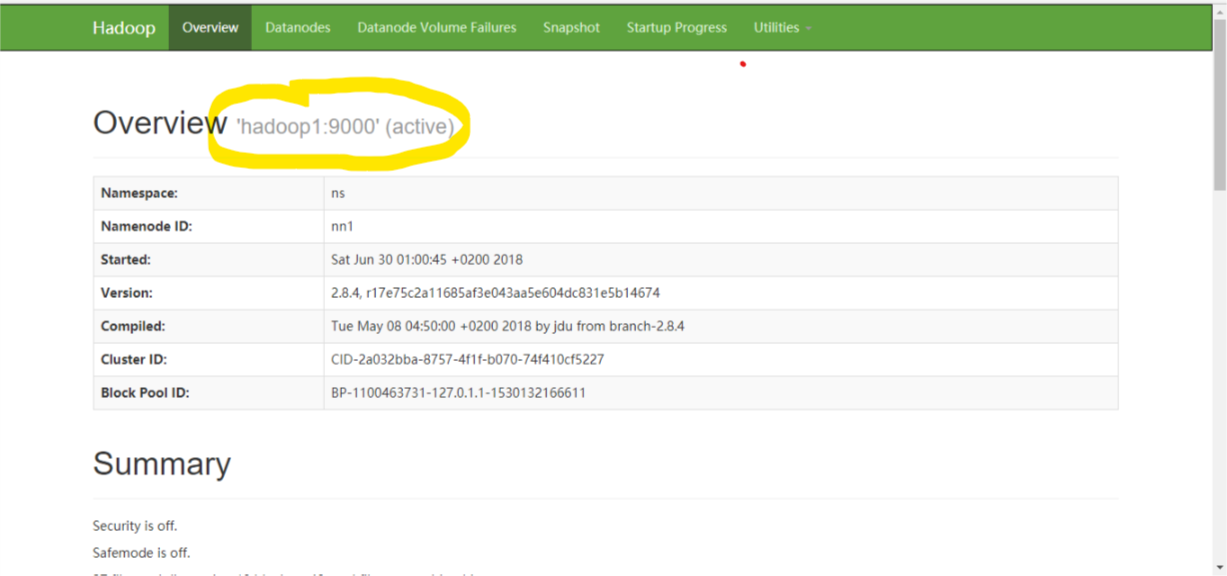
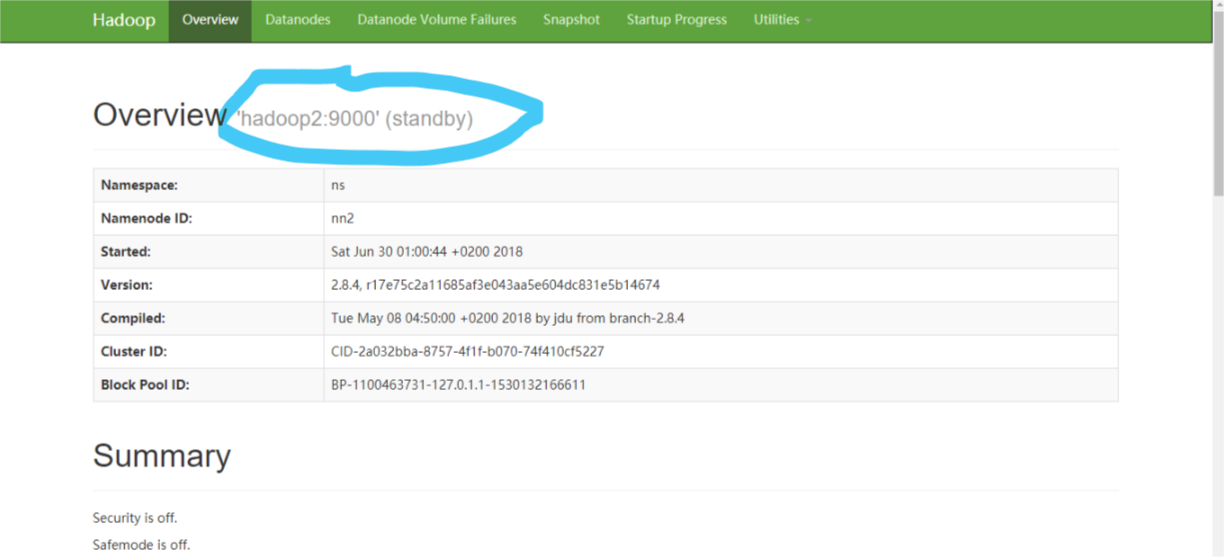
查看namenode状态,目前hadoop1上的namenode处于active的状态,尝试kill掉namenode进程,发现hadoop2上的nn2由standby变成了active。
root@hadoop1:~# hdfs haadmin -getServiceState nn1
active
root@hadoop1:~# hdfs haadmin -getServiceState nn2
standby
也可以通过浏览器访问:http://Ip1:50070;http://Ip2:50070
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4..jar wordcount input out
Hadoop集群搭建:用三台云服务器搭建HA集群(过程记录和分享)的更多相关文章
- 使用三台云服务器搭建真正的Redis集群
三台云服务器搭建redis集群# 今天花了一天的时间弄集群redis:遇到了很多坑,从头开始吧 环境讲解: 两台配置:1核2G,另一台:1核1G: 操作系统:Centos 7.6 Redis:3.2. ...
- 基于腾讯Centos7云服务器搭建SVN版本控制库
基于腾讯Centos7云服务器搭建SVN版本控制库 最近在和小伙伴组队参加一个关于人工智能的比赛,无奈不知道怎么处理好每个人的代码托管问题,于是找到了晚上免费svn托管服务器的服务,但是所给的免费空间 ...
- 阿里云服务器搭建SVN
简单步骤介绍 1:安装svn apt-get install subversion 2. 开启svn服务器 svnserve -d 检查是否开启:ps aux | grep svnserve 若出现如 ...
- 如何使用windows云服务器搭建IIs、windows服务
如何使用windows云服务器搭建IIs.windows服务,以下针对腾讯云服务器进行说明 1.购买云服务器之后,第1步需要设置的是,找到重装系统.重置密码等处. 2.设置安全组,设置完安全组之后才能 ...
- 阿里云服务器搭建Docker版AWVS
本文严重参考该文章:https://www.sqlsec.com/2020/04/awvs.html 阿里云服务器搭建Docker版AWVS,因为之前有使用Docker的经验,所以本文只是简述一下安装 ...
- centos7+腾讯云服务器搭建wordpress
title: centos7+腾讯云服务器搭建wordpress date: 2020-03-04 categories: web tags: [wordpress] 分两部分:1.搭建LEMP环境 ...
- 阿里云服务器搭建vulhub靶场
阿里云服务器搭建vulhub靶场 环境 服务器:阿里云服务器 系统:centos7 应用:vulhub 步骤 vulhub需要依赖docker搭建,首先安装docker. 使用以下方法之一: # cu ...
- 多台云服务器的 Kubernetes 集群搭建
环境 两台或多台腾讯云服务器(本人搭建用了两台),都是 CentOs 7.6, master 节点:服务器为 4C8G,公网 IP:124.222.61.xxx node1节点:服务器为 4C4G,公 ...
- 1元搭建自己的云服务器&解析域名
最近在学做微信开发,没有自己的域名和服务器就不得不寄人篱下,索性自己就到云主机上搭建了个服务器,但是水平有限弄了一个下午~~有自己的域名和服务器的好处相信不用我多说了.比如日后可以有自己域名的个性博客 ...
随机推荐
- angular based app开发流程
整理user story mock UI,生成满足上述user story的原型界面 根据上述UI,整理出data model(适用于后端和angular的数据模型) 后端CRUD开发,形成REST ...
- php 3des加密 兼容JAVA 多么痛的领悟呀
最近和别人做接口用到SOCKET TCP/IP方式 其中需要对账号和密码进行3DES加密 对方提供了一个加密比对的软件和JAVA的实现代码 并且给了我们一个长度为32位的密钥 这边需要用PHP来实现! ...
- Azure 虚拟机上的 SQL Server 常见问题
本主题提供有关运行 Azure 虚拟机中的 SQL Server 时出现的一些最常见问题的解答. 如果本文未解决你的 Azure 问题,请访问 MSDN 和 CSDN 上的 Azure 论坛. 你可以 ...
- Windows ->> Windows下安装MSI程序遇到2503和2502错误
三个步骤可以解决这个问题: 1) 以管理员身份开启命令行模式并键入msiexec /package <msi文件路径> 2) 修改组策略 计算机配置 ->> 管理模板 -> ...
- Python学习---面向对象的学习[基础]
面向对象 面向对象的三大特性是指:封装.继承和多态. 说明: Python可以函数式编程,也可以面向对象编程 l 面向过程:根据业务逻辑从上到下写垒代码 l 函数式 :将某功能代码封装到函数中,日后便 ...
- 乘风破浪:LeetCode真题_017_Letter Combinations of a Phone Number
乘风破浪:LeetCode真题_017_Letter Combinations of a Phone Number 一.前言 如何让两个或者多个集合中的随机挑选的元素结合到一起,并且得到所有的可能呢? ...
- MTK 官方 openwrt SDK 使用
来源 1.https://github.com/unigent/openwrt-3.10.14 上面有个 问题:SDK 缺少 linux-3.10.14-p112871.tar.xz 在 http ...
- C语言程序员必读的5本书
本文由 伯乐在线 - programmer_lin 翻译自 fromdev.欢迎加入技术翻译小组.转载请参见文章末尾处的要求. 你正计划着通过看书来学习C语言吗?“书籍是人类最忠诚的朋友“.海明威一定 ...
- Python 多线程 使用线程 (二)
Python中实现多线程需要使用到 threading 库,其中每一个 Thread类 的实例控制一个线程. Thread类 #类签名 def __init__(self, group=None, t ...
- 新版剑指offer14 剪绳子
int maxProduct(int length){ ) ; ) ; ) ; ; == ) numof3 -= ; )/; ,numof3))*(,numof2)); }