基于Golang的逃逸分析(Language Mechanics On Escape Analysis)
何为逃逸分析
在编译程序优化理论中,逃逸分析是一种确定指针动态范围的方法——分析在程序的哪些地方可以访问到指针。它涉及到指针分析和形状分析。
当一个变量(或对象)在子程序中被分配时,一个指向变量的指针可能逃逸到其它执行线程中,或是返回到调用者子程序。如果使用尾递归优化(通常在函数编程语言中是需要的),对象也可以看作逃逸到被调用的子程序中。如果一种语言支持第一类型的延续性在Scheme和Standard ML of New Jersey中同样如此),部分调用栈也可能发生逃逸。
如果一个子程序分配一个对象并返回一个该对象的指针,该对象可能在程序中被访问到的地方无法确定——这样指针就成功“逃逸”了。如果指针存储在全局变量或者其它数据结构中,因为全局变量是可以在当前子程序之外访问的,此时指针也发生了逃逸。
逃逸分析确定某个指针可以存储的所有地方,以及确定能否保证指针的生命周期只在当前进程或线程中。
前序(Prelude)
本系列文章总共四篇,主要帮助大家理解 Go 语言中一些语法结构和其背后的设计原则,包括指针、栈、堆、逃逸分析和值/指针传递。这是第二篇,主要介绍堆和逃逸分析。
以下是本系列文章的索引:
介绍(Introduction)
在四部分系列的第一部分,我用一个将值共享给 goroutine 栈的例子介绍了指针结构的基础。而我没有说的是值存在栈之上的情况。为了理解这个,你需要学习值存储的另外一个位置:堆。有这个基础,就可以开始学习逃逸分析。
逃逸分析是编译器用来决定你的程序中值的位置的过程。特别地,编译器执行静态代码分析,以确定一个构造体的实例化值是否会逃逸到堆。在 Go 语言中,你没有可用的关键字或者函数,能够直接让编译器做这个决定。只能够通过你写代码的方式来作出这个决定。
堆(Heaps)
堆是内存的第二区域,除了栈之外,用来存储值的地方。堆无法像栈一样能自清理,所以使用这部分内存会造成很大的开销(相比于使用栈)。重要的是,开销跟 GC(垃圾收集),即被牵扯进来保证这部分区域干净的程序,有很大的关系。当垃圾收集程序运行时,它会占用你的可用 CPU 容量的 25%。更有甚者,它会造成微秒级的 “stop the world” 的延时。拥有 GC 的好处是你可以不再关注堆内存的管理,这部分很复杂,是历史上容易出错的地方。
在 Go 中,会将一部分值分配到堆上。这些分配给 GC 带来了压力,因为堆上没有被指针索引的值都需要被删除。越多需要被检查和删除的值,会给每次运行 GC 时带来越多的工作。所以,分配算法不断地工作,以平衡堆的大小和它运行的速度。
共享栈(Sharing Stacks)
在 Go 语言中,不允许 goroutine 中的指针指向另外一个 goroutine 的栈。这是因为当栈增长或者收缩时,goroutine 中的栈内存会被一块新的内存替换。如果运行时需要追踪指针指向其他的 goroutine 的栈,就会造成非常多需要管理的内存,以至于更新指向那些栈的指针将使 “stop the world” 问题更严重。
这里有一个栈被替换好几次的例子。看输出的第 2 和第 6 行。你会看到 main 函数中的栈的字符串地址值改变了两次。https://play.golang.org/p/pxn5u4EBSI
逃逸机制(Escape Mechanics)
任何时候,一个值被分享到函数栈帧范围之外,它都会在堆上被重新分配。这是逃逸分析算法发现这些情况和管控这一层的工作。(内存的)完整性在于确保对任何值的访问始终是准确、一致和高效的。
通过查看这个语言机制了解逃逸分析。https://play.golang.org/p/Y_VZxYteKO
清单 1
package main
type user struct {
name string
email string
}
func main() {
u1 := createUserV1()
u2 := createUserV2()
println("u1", &u1, "u2", &u2)
}
//go:noinline
func createUserV1() user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V1", &u)
return u
}
//go:noinline
func createUserV2() *user {
u := user{
name: "Bill",
email: "bill@ardanlabs.com",
}
println("V2", &u)
return &u
}
我使用 go:noinline 指令,阻止在 main 函数中,编译器使用内联代码替代函数调用。内联(优化)会使函数调用消失,并使例子复杂化。我将在下一篇博文介绍内联造成的副作用。
在表 1 中,你可以看到创建 user 值,并返回给调用者的两个不同的函数。在函数版本 1 中,返回值。
清单 2
16 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
我说这个函数返回的是值是因为这个被函数创建的 user 值被拷贝并传递到调用栈上。这意味着调用函数接收到的是这个值的拷贝。
你可以看下第 17 行到 20 行 user 值被构造的过程。然后在第 23 行,user 值的副本被传递到调用栈并返回给调用者。函数返回后,栈看起来如下所示。
图 1
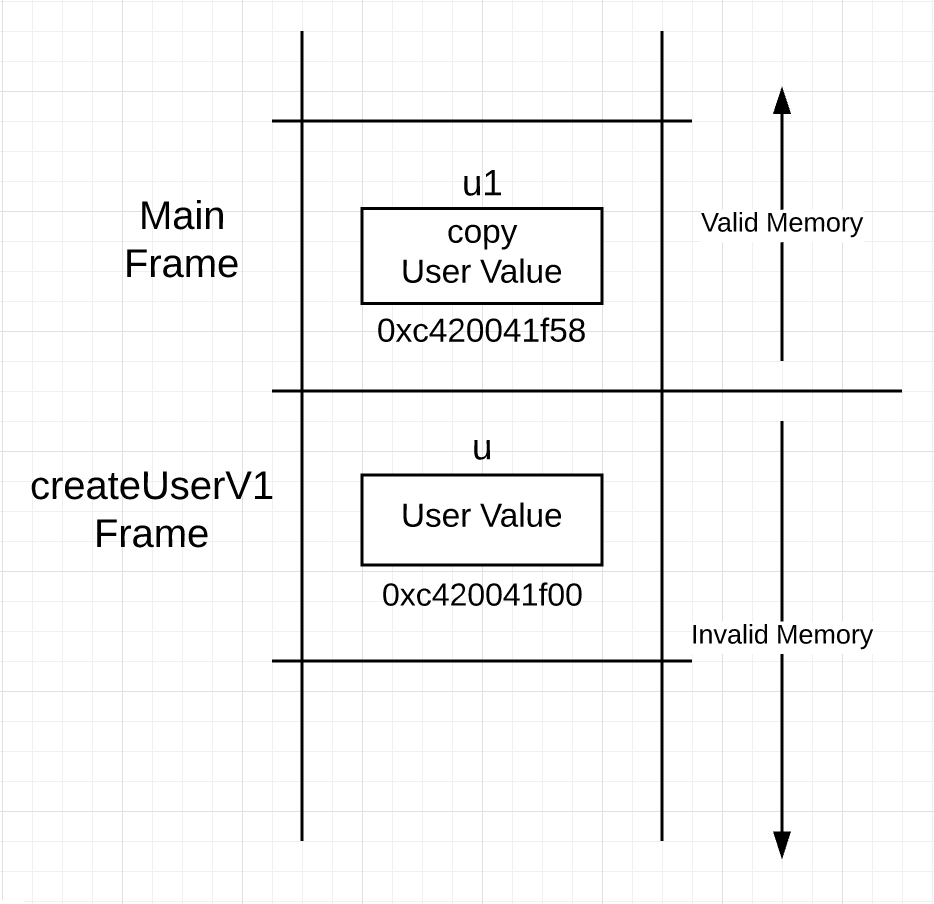
你可以看到图 1 中,当调用完 createUserV1 ,一个 user 值同时存在(两个函数的)栈帧中。在函数版本 2 中,返回指针。
清单 3
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
我说这个函数返回的是指针是因为这个被函数创建的 user 值通过调用栈被共享了。这意味着调用函数接收到一个值的地址拷贝。
你可以看到在第 28 行到 31 行使用相同的字段值来构造 user 值,但在第 34 行返回时却是不同的。不是将 user 值的副本传递到调用栈,而是将 user 值的地址传递到调用栈。基于此,你也许会认为栈在调用之后是这个样子。
图 2
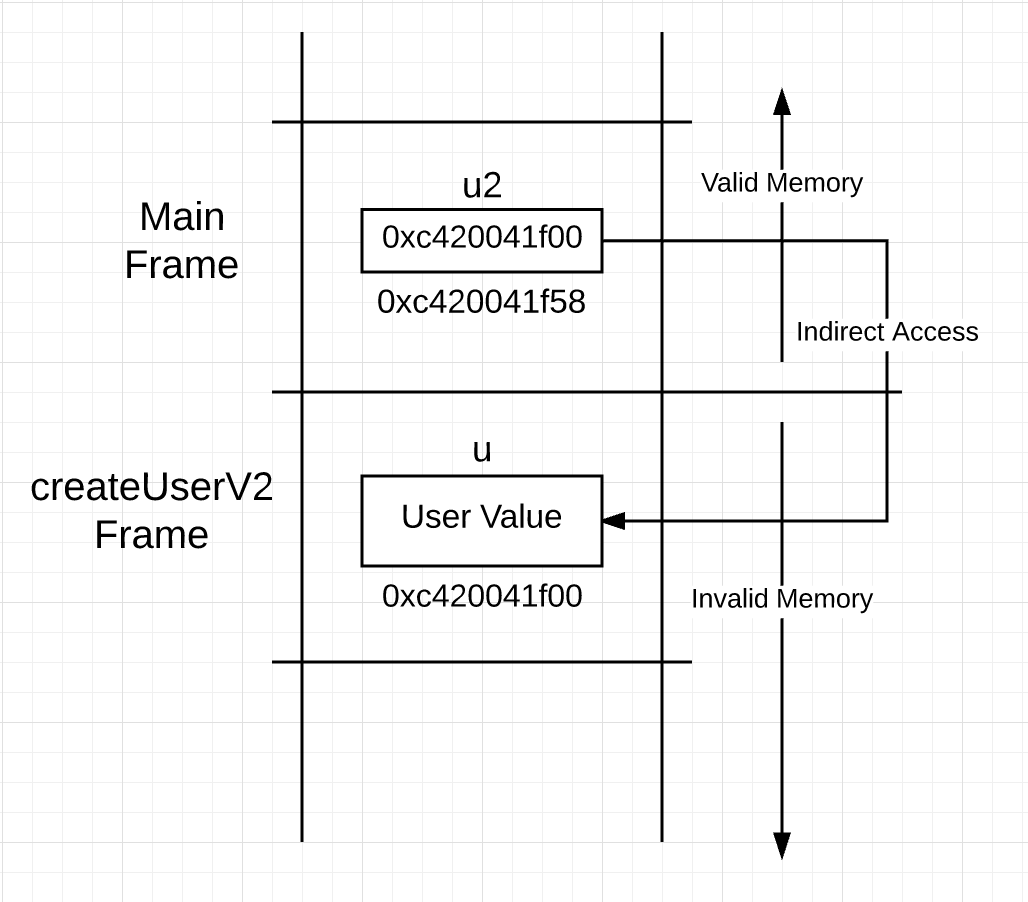
如果看到的图 2 真的发生的话,你将遇到一个问题。指针指向了栈下的无效地址空间。当 main 函数调用下一个函数,指向的内存将重新映射并将被重新初始化。
这就是逃逸分析将开始保持完整性的地方。在这种情况下,编译器将检查到,在 createUserV2 的(函数)栈中构造 user 值是不安全的,因此,替代地,会在堆中构造(相应的)值。这(个分析并处理的过程)将在第 28 行构造时立即发生。
可读性(Readability)
在上一篇博文中,我们知道一个函数只能直接访问它的(函数栈)空间,或者通过(函数栈空间内的)指针,通过跳转访问(函数栈空间外的)外部内存。这意味着访问逃逸到堆上的值也需要通过指针跳转。
记住 createUserV2 的代码的样子:
清单 4
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
语法隐藏了代码中真正发生的事情。第 28 行声明的变量 u 代表一个 user 类型的值。Go 代码中的类型构造不会告诉你值在内存中的位置。所以直到第 34 行返回类型时,你才知道值需要逃逸(处理)。这意味着,虽然 u 代表类型 user 的一个值,但对该值的访问必须通过指针进行。
你可以在函数调用之后,看到堆栈就像(图 3)这样。
图 3
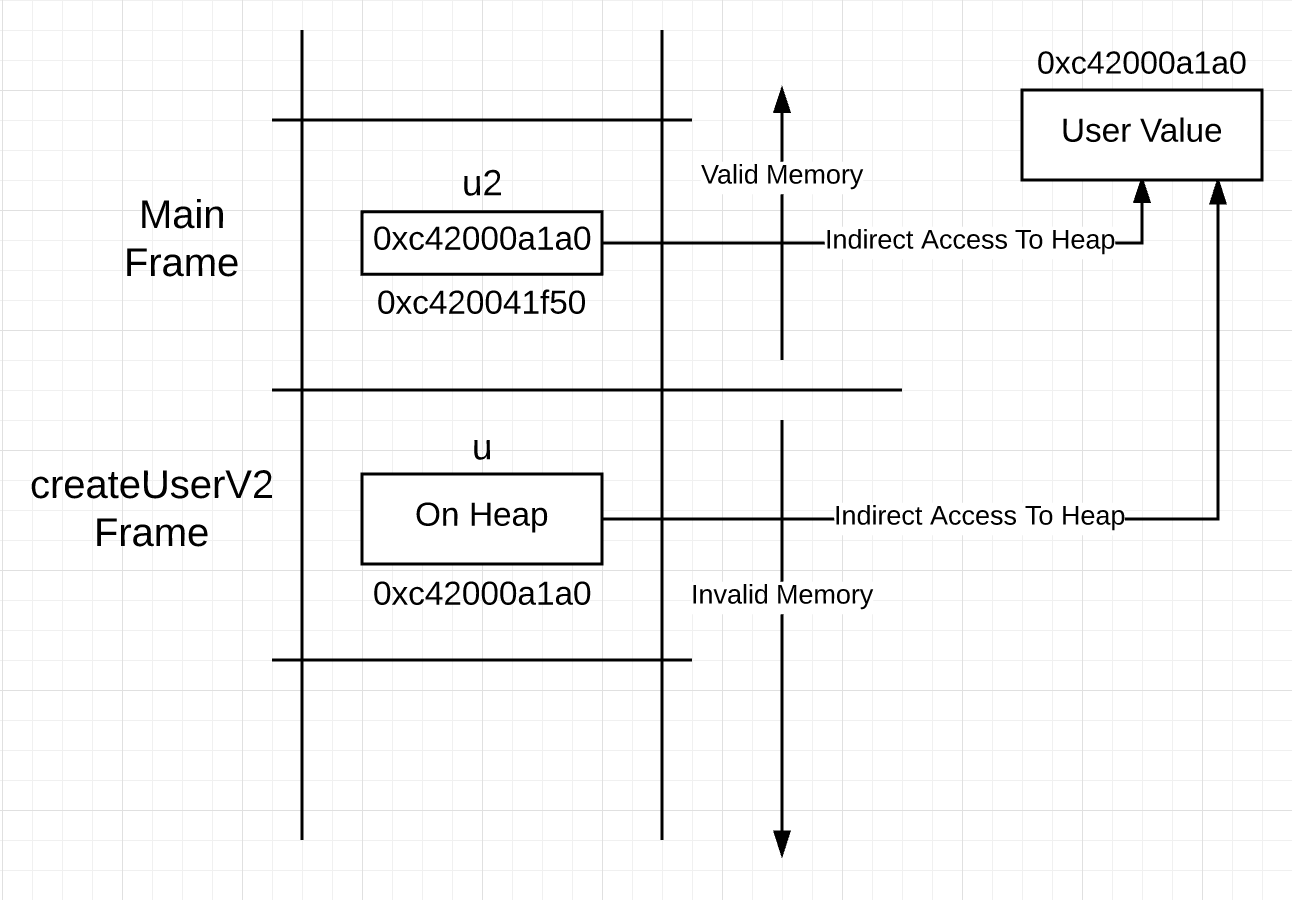
在 createUserV2 函数栈中,变量 u 代表的值存在于堆中,而不是栈。这意味着用 u 访问值时,使用指针访问而不是直接访问。你可能想,为什么不让 u 成为指针,毕竟访问它代表的值需要使用指针?
清单 5
27 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
如果你这样做,将使你的代码缺乏重要的可读性。(让我们)离开整个函数一秒,只关注 return。
清单 6
34 return u
35 }
这个 return 告诉你什么了呢?它说明了返回 u 值的副本给调用栈。然而,当你使用 & 操作符,return 又告诉你什么了呢?
清单 7
34 return &u
35 }
多亏了 & 操作符,return 告诉你 u 被分享给调用者,因此,已经逃逸到堆中。记住,当你读代码的时候,指针是为了共享,& 操作符对应单词 "sharing"。这在提高可读性的时候非常有用,这(也)是你不想失去的部分。
清单 8
01 var u *user
02 err := json.Unmarshal([]byte(r), &u)
03 return u, err
为了让其可以工作,你一定要通过共享指针变量(的方式)给(函数) json.Unmarshal。json.Unmarshal 调用时会创建 user 值并将其地址赋值给指针变量。https://play.golang.org/p/koI8EjpeIx
代码解释:
01:创建一个类型为 user,值为空的指针。
02:跟函数 json.Unmarshal 函数共享指针。
03:返回 u 的副本给调用者。
这里并不是很好理解,user值被 json.Unmarshal 函数创建,并被共享给调用者。
如何在构造过程中使用语法语义来改变可读性?
清单 9
01 var u user
02 err := json.Unmarshal([]byte(r), &u)
03 return &u, err
代码解释:
01:创建一个类型为 user,值为空的变量。
02:跟函数 json.Unmarshal 函数共享 u。
03:跟调用者共享 u。
这里非常好理解。第 02 行共享 user 值到调用栈中的 json.Unmarshal,在第 03 行 user 值共享给调用者。这个共享过程将会导致 user 值逃逸。
在构建一个值时,使用值语义,并利用 & 操作符的可读性来明确值是如何被共享的。
编译器报告(Compiler Reporting)
想查看编译器(关于逃逸分析)的决定,你可以让编译器提供一份报告。你只需要在调用 go build 的时候,打开 -gcflags 开关,并带上 -m 选项。
实际上总共可以使用 4 个 -m,(但)超过 2 个级别的信息就已经太多了。我将使用 2 个 -m 的级别。
清单 10
$ go build -gcflags "-m -m"
./main.go:16: cannot inline createUserV1: marked go:noinline
./main.go:27: cannot inline createUserV2: marked go:noinline
./main.go:8: cannot inline main: non-leaf function
./main.go:22: createUserV1 &u does not escape
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
./main.go:12: main &u1 does not escape
./main.go:12: main &u2 does not escape
你可以看到编译器报告是否需要逃逸处理的决定。编译器都说了什么呢?请再看一下引用的 createUserV1 和 createUserV2 函数。
清单 13
16 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
从报告中的这一行开始。
清单 14
./main.go:22: createUserV1 &u does not escape
这是说在函数 createUserV1 调用 println 不会造成 user 值逃逸到堆。这是必须检查的,因为它将会跟函数 println 共享(u)。
接下来看报告中的这几行。
清单 15
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
这几行是说,类型为 user,并在第 31 行被赋值的 u 的值,因为第 34 行的 return 逃逸。最后一行是说,跟之前一样,在 33 行调用 println 不会造成 user 值逃逸。
阅读这些报告可能让人感到困惑,(编译器)会根据所讨论的变量的类型是基于值类型还是指针类型而略有变化。
将 u 改为指针类型的 *user,而不是之前的命名类型 user。
清单 16
27 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
再次生成报告。
清单 17
./main.go:30: &user literal escapes to heap
./main.go:30: from u (assigned) at ./main.go:28
./main.go:30: from ~r0 (return) at ./main.go:34
现在报告说在 28 行赋值的指针类型 *user,u 引用的 user 值,因为 34 行的 return 逃逸。
结论
值在构建时并不能决定它将存在于哪里。只有当一个值被共享,编译器才能决定如何处理这个值。当你在调用时,共享了栈上的一个值时,它就会逃逸。在下一篇中你将探索一个值逃逸的其他原因。
这些文章试图引导你选择给定类型的值或指针的指导原则。每种方式都有(对应的)好处和(额外的)开销。保持在栈上的值,减少了 GC 的压力。但是需要存储,跟踪和维护不同的副本。将值放在堆上的指针,会增加 GC 的压力。然而,也有它的好处,只有一个值需要存储,跟踪和维护。(其实,)最关键的是如何保持正确地、一致地以及均衡(开销)地使用。
基于Golang的逃逸分析(Language Mechanics On Escape Analysis)的更多相关文章
- Golang逃逸分析
Golang逃逸分析 介绍逃逸分析的概念,go怎么开启逃逸分析的log. 以下资料来自互联网,有错误之处,请一定告之. sheepbao 2017.06.10 什么是逃逸分析 wiki上的定义 In ...
- 逃逸分析与栈、堆分配分析 escape_analysis
小结: 1.当形参为 interface 类型时,在编译阶段编译器无法确定其具体的类型.因此会产生逃逸,最终分配到堆上. 2.The construction of a value doesn't d ...
- golang逃逸分析和竞争检测
最近在线上发现一块代码逻辑在执行N次耗时波动很大1ms~800ms,最开始以为是gc的问题,对代码进行逃逸分析,看哪些变量被分配到堆上了,后来发现是并发编程时对一个切片并发的写,导致存在竞争,类似下面 ...
- 聊聊Golang逃逸分析
逃逸分析的概念,go怎么开启逃逸分析的log. 以下资料来自互联网,有错误之处,请一定告之. 什么是逃逸分析 wiki上的定义 在编译程序优化理论中,逃逸分析是一种确定指针动态范围的方法——分析在程序 ...
- JVM笔记-逃逸分析
参考: http://www.iteye.com/topic/473355http://blog.sina.com.cn/s/blog_4b6047bc01000avq.html 什么是逃逸分析(Es ...
- 马蜂窝搜索基于 Golang 并发代理的一次架构升级
搜索业务是马蜂窝流量分发的重要入口.很多用户在使用马蜂窝时,都会有目的性地主动搜索与自己旅行需求相关的各种信息,衣食住行,事无巨细,从而做出最符合需求的旅行决策. 因此在马蜂窝,搜索业务交互的下游模块 ...
- Go变量逃逸分析
目录 什么是逃逸分析 为什么要逃逸分析 逃逸分析是怎么完成的 逃逸分析实例 总结 写过C/C++的同学都知道,调用著名的malloc和new函数可以在堆上分配一块内存,这块内存的使用和销毁的责任都在程 ...
- 逃逸分析(Escape Analysis)
一.什么是逃逸 逃逸是指在某个方法之内创建的对象,除了在方法体之内被引用之外,还在方法体之外被其它变量引用到:这样带来的后果是在该方法执行完毕之后,该方法中创建的对象将无法被GC回收,由于其被其它变量 ...
- JVM 优化之逃逸分析
整理自 周志明<深入JVM> 1, 是JVM优化技术,它不是直接优化手段,而是为其它优化手段提供依据. 2,逃逸分析主要就是分析对象的动态作用域. 3,逃逸有两种:方法逃逸和线程逃逸. ...
随机推荐
- windows自动化测试环境搭建文档
步骤如下: 1.搭建安卓环境,需要设置系统变量“ANDROID_HOME”. 2.安装Node.js http://www.nodejs.org/download/ 下载相关操作系统的版本 3.安装A ...
- c# 第9节 数据类型之引用类型
本节内容: 1:数据类型之引用类型 2:字符串要注意的两点: 1:数据类型之引用类型 实例: 2:字符串要注意的两点: 对变量进行重新赋值:其原本的字符串并没有销毁
- 201777010217-金云馨《面向对象程序设计(java)》第十六周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...
- 201871010132-张潇潇-《面向对象程序设计(java)》第七周总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...
- 201871010135 张玉晶《面向对象程序设计(java)》第十三周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/zyja/p/11918 ...
- VSCode变换python的调试解释器
假如一个电脑上有多个Python的环境,想要设置不同的python解释器用于调试. VSCode 的设置,是通过.json的文本来配置的.打开文本的方式: 打开后的文件如下所示: 可以试试“new s ...
- Oracle告Google输了
Oracle告Google输了 boxi • 2016-05-27 • 大公司 Google表示,陪审团的认定代表了Android生态体系.Java开发社区以及依靠开放免费编程语言开发创新消费者产品的 ...
- Dubbo服务集群容错
Dubbo是Alibaba开源的分布式服务框架,我们可以非常容易地通过Dubbo来构建分布式服务,并根据自己实际业务应用场景来选择合适的集群容错模式,这个对于很多应用都是迫切希望的,只需要通过简单的配 ...
- ISerializable接口
继承ISerializable接口可以灵活控制序列化过程 格式化器的工作流程:格式化器再序列化一个对象的时候,发现对象继承了ISerializable接口,那它就会忽略掉类型所有的序列化特性,转而调用 ...
- 【oracle】ORA-12638 : 身份证明检索失败
sqlnet.ora 1.删了 2.#注释了 背后缘由:待写