GhostVLAD for set-based face recognition
GhostVLAD for set-based face recognition 中提到了文章解决的是template-based face recognition。
VLAD: vector of locally aggregated descriptors. 由Jegou et al.在2010年提出,其核心思想是aggregated(积聚),主要应用于图像检索领域。
文章的3个贡献:
- 提出一种网络来聚合并embed网络输出的面部特征向量至一个compact的固定长度的表示。
- 提出一个新奇的GhostVLAD层,其中包含ghost clusters,不对聚合做贡献。文中展示了一种高质量的自动加权方式来使得高质量的图像比低质量的图像贡献更多。并且这个ghost clusters可以提高网络能力来解决比较差质量的图像。
- 文中探索了特征维度,簇的数目,不同训练技术对识别性能的影响。最后作者在IJB-B数据集上远超sota的identification和cerification指标。
那么这种set(template) based face recognition的难处何在?在于集合里的人脸可能有不同的姿态,表情,光照,甚至质量的差异也很大。如果我给low-quality和high-quality一样的weight,那肯定会hurt performance。所以网络应该更关注于informative ones。
比较set之间的相似性一个直接的做法就是我将每个subject的所有人脸特征都存储起来,然后比较两个subject的每一对图像,这么做是非常耗存储和时间。因此聚合方法能够产生compact template representation。更重要的是,从image set获取的representation应当更加具有判别性。同一subject的template descriptors应当互相close,反之则far apart。尽管一些工作利用average pooling和max pooling可以聚合到一个比较compact的template representation,本文寻找一种更好的方案。本文灵感来源于图像检索中的编码方法:Fisher Vector encoding和T-embedding 增加从related和unrelated图像块提取到的描述子的可分性。于是作者也在利用了一种相似的encoding:NetVLAD来设计网络。作者拓展NetVLAD结构to include ghost clusters。将这些低质量人脸视为ghost clusters。尽管没有明确对template里的faces进行加权,这种特性自动会出现。即低质量人脸会contribute less。网络以端到端的方式训练,仅用identity-level labels。在IJB-A,IJB-B上面都有很大提升。
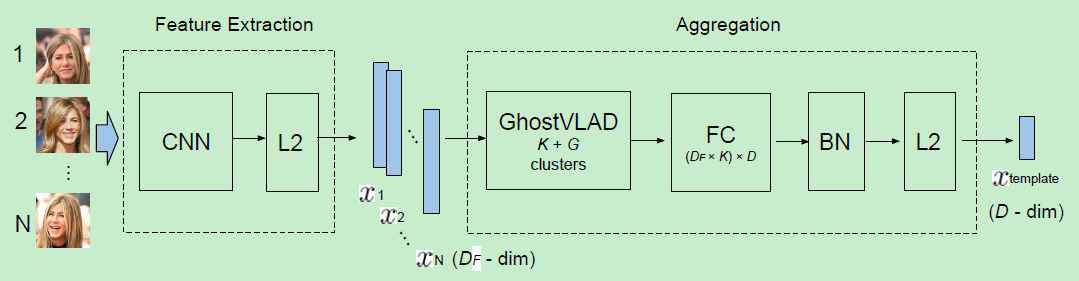
大致结构如上图:对一个template中的每个图片提取特征,然后利用GhostVLAD层来聚合这些descriptors到单一固定长度的vectors。最后的D维template描述子由FC层来削减维度,并附有BN和L2正则。
这个网络应该有如下性质:
- 输入任意数量图像,输出固定长度的template descriptor来表征输入的image set
- 输出的template descriptor应当是compact的,或低维,使得存储较小便于更快的template comparisions。
- 输出的template descriptor应当是discriminative的,使得同一subject的templates之间的相似性大于与其他不同subjects之间的相似性。(内聚性)
上面三条性质的实现方案分别如下:
- 利用一个修改后的NetVLAD层:GhostVLAD来聚合人脸描述子
- 通过一个trained layer实现维度缩减
- 因为整个网络end-to-end被训练,并且因为GhostVLAD层能够down-weight低质量图像的contribution,所以可以实现discriminative
本文的核心部件:GhostVLAD:NetVLAD with ghost clusters
这是个可训练的aggregation layer。给定N个DF维的面部向量,计算一个单一的DF乘K维的输出。它基于NetVLAD层实现了一个编码过程,类似于VLAD encoding。所以是可微可训练的。这个NetVLAD已被证实比average和max pooling的效果要好。这里简要回顾一下论文NetVLAD(NetVLAD: CNN architecture for weakly supervised place recognition)。

作者拓展NetVLAD with "ghost" clusters为GhostVLAD。即作者在原有的K个类簇中额外的加了G个“ghost”类簇来形成soft assignments。

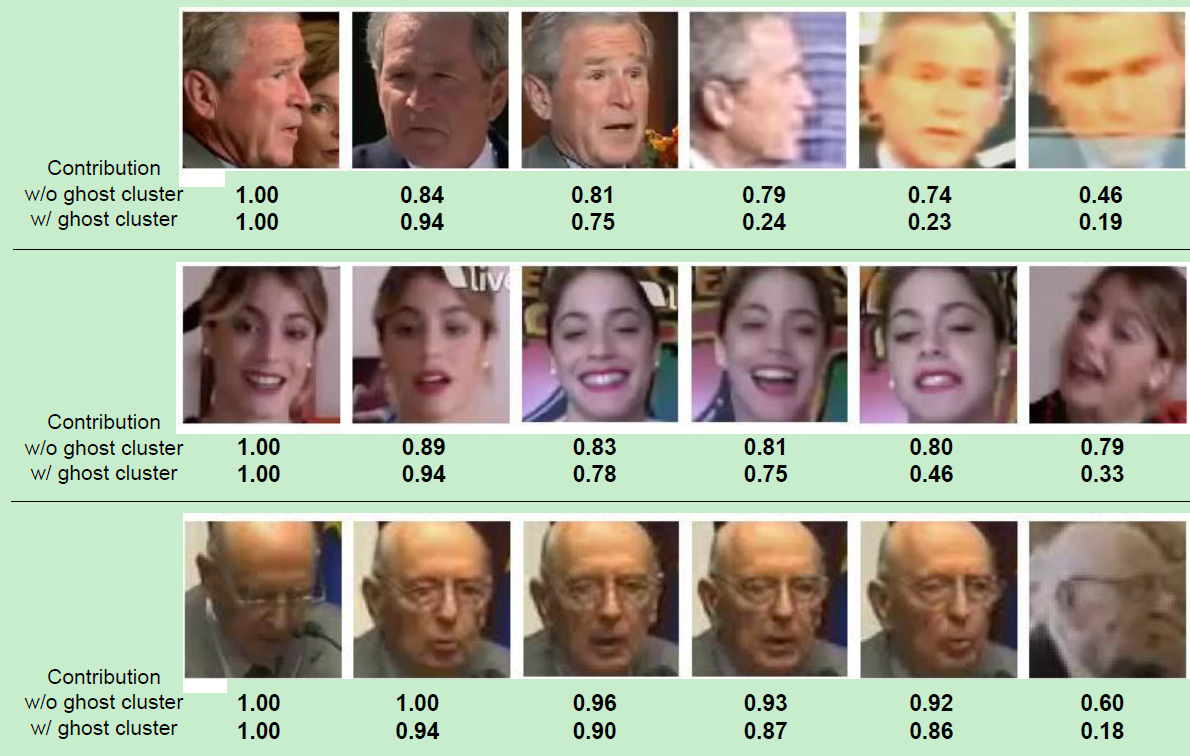
使用ghost clusters的一个直觉就是使得网络更容易调整template中的每个face example。这通过assigning examples to be ignored to the ghost clusters来实现的。例如对于一个highly blurry的人脸图像,将会被很大程度上assigned to a ghost cluster,使得它在non-ghost的clusters的权重就会趋近于0。那这样就使得它对于template representation的贡献是可忽略不计的。
一些训练细节:
为了perform set-based training,重复在线采样属于同一identity的固定数目的图像。
测试细节:
对于IJB-A和IJB-B做“1:1 face verification”和“1:N face identification”。
- 1:1 face verification的目的是决定两个templates是否属于同一人。通过设定templates之间的相似性阈值实现。验证性能由ROC曲线评估,也就是验证true accept rates(TAR)和false accept rates(FAR)的trade off。
- 1:N identification的做法是对于probe set的templates,要对给定的gallery中所有templates做评价。模型的评价方法有:true positive identification rate(TPIR)和false positive identification rate(FPIR)以及Rank-N。
结果:明显对低质量图像降低了权重。
论文:A Good Practice Towards Top Performance of Face Recognition: Transferred Deep Feature Fusion
A template refers to a collection of all media (images and/or video frames) of an interested face captured under different conditions that can be utilized as a combined single
representation for matching task.
GhostVLAD for set-based face recognition的更多相关文章
- Improved RGB-D-T based Face Recognition 论文笔记
本文将基于深度学习的卷积神经网络(CNN)应用于基于RGB-D-T的多模态人脸识别问题. 此外,引入了基于CNN的识别模块与各种纹理特征(LBP,HOG,HAAR,HOGOM)的后期融合,在基准RGB ...
- Activity Recognition行为识别
暑假听了computer vision的一个Summer School,里面Jason J. Corso讲了他们运用Low-Mid-High层次结构进行Video Understanding 和 Ac ...
- Recent papers on Action Recognition | 行为识别最新论文
CVPR2019 1.An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognit ...
- {ICIP2014}{收录论文列表}
This article come from HEREARS-L1: Learning Tuesday 10:30–12:30; Oral Session; Room: Leonard de Vinc ...
- 深入浅出QOS详解(转)
QOS学习笔记 (工作时间之余,总结了这些,累的食指快脱节了,现在还在恢复中,为的就是让文章质量再提高点,希望对大家有帮助!文章太长,为方便,我附件上文章原文.) QOS,服务质量.顾名思义,就是为了 ...
- (zhuan) Speech and Natural Language Processing
Speech and Natural Language Processing obtain from this link: https://github.com/edobashira/speech-l ...
- "Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network" 解读
简介:这是一篇17年的CVPR,作者提出使用现有的人脸识别深度神经网络Resnet101来得到一个具有鲁棒性的人脸模型. 原文链接:https://www.researchgate.net/publi ...
- ECCV 2014 Results (16 Jun, 2014) 结果已出
Accepted Papers Title Primary Subject Area ID 3D computer vision 93 UPnP: An optimal O(n) soluti ...
- CVPR 2017 Paper list
CVPR2017 paper list Machine Learning 1 Spotlight 1-1A Exclusivity-Consistency Regularized Multi-View ...
随机推荐
- QTAction Editor的简单使用(简洁明了)
1. 打开UI界面,选择如下图的模式 2. 添加资源名称并选择相应的资源,点击OK 3. 相应的资源就建立好了 4. 添加好的资源可以直接拖到MainWindow中
- css 宽高等比
1.利用js 2.容器里添加图片,让图片的等比缩放撑大容器,图片z-index=负数,
- 重构之字段改名 UML行为图 用例图 时序图&协作图 状态图&活动图 依恋情结
简单的使用一下字段改名 为什么使用字段改名: 你在一个软件上做的工作越多,对这个软件的数据的理解就越深刻,你需要把这些理解融入到代码中.利用名字的解释作用,让代码更容易被理解. 如何找到该变量的所 ...
- UI系统综述:iOS的图形绘制、动画与runloop
一.一条业务pipeline: 一个连接核心:coreanimation 二.两个进程: 1.app进程: 2.render进程: 首先,由 app 处理事件(Handle Events),如:用户的 ...
- 关于maven导入工程pom文件报错问题及解决
pom文件头报错 1.导入maven文件,经常遇到表头出错问题.报错:Failure to transfer org.apache.maven.shared:maven-filtering:pom:1 ...
- 11.04Test
11.04Test 查看请点个赞 转载请注明出处(~不然~) 题目 描述 做法 \(BSOJ5143\) 要求给\(M\)个通道染色,使得同色通道不能相交 转为矛盾模型,\(2-sat\)or二分图染 ...
- 8259A的初始化(单片)
1.单片8259A的初始化流程图: 在单片的初始化中不需要ICW3,因为ICW3是指明主片和从片的连接情况的. 2.程序解析: (1)ICW1 MOV AL,13H (2)ICW2 MOV AL,08 ...
- Numpy中数据的常用的保存与读取方法
小书匠 深度学习 文章目录: 1.保存为二进制文件(.npy/.npz) numpy.save numpy.savez numpy.savez_compressed 2.保存到文本文件 numpy. ...
- 使用charles对jmeter进行抓包
- 【转】Spring线程及线程池的使用
spring @Async 线程池使用 最近公司项目正逐渐从dubbo向springCloud转型,在本次新开发的需求中,全部使用springcloud进行,在使用时线程池,考虑使用spring封装的 ...