GJM : Python简单爬虫入门 (一) [转载]
| 版权声明:本文原创发表于 【请点击连接前往】 ,未经作者同意必须保留此段声明!如有侵权请联系我删帖处理! |
为大家介绍一个简单的爬虫工具BeautifulSoup
BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题)
此工具在搜索你想爬的数据匹配的方式就是html标签嵌套的顺序(html介绍在其它随笔内)
首先来聊聊BeautifulSoup的安装pip install python-bs4 包含BeautifulSoup方法
再来安装依赖工具requests和解析格式lxml下载安装包 解压进入目录 python setup.py install此方法是请求服务
先来写一个简单的网页解析代码如下:

#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
}
url = "http://www.jd.com/"
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
print(soup)
来简单说明下每行代码得作用:
from从bs4库里import导入BeautifulSoup方法
import导入requests方法
headers表示头文件,伪装成浏览器浏览网页,当然我这里写得简单还没写全
url网页地址
wb_data网页数据requests.get请求访问(url网页京东,headers伪装的头文件)
soup解析后的数据BeautifulSoup解析数据(wb_data网页数据,lxml解析的格式按这个要求解析)
print答应soup解析后的网页数据 也就是网页源代码如下 由于网页源代码很长所以这里截图只能显示一部分
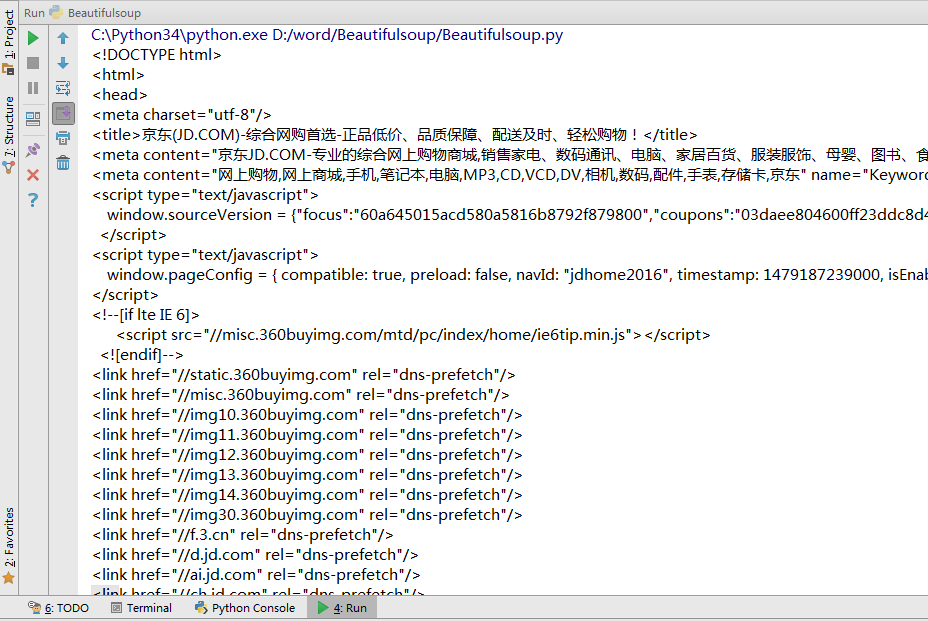
学好基础包括html的结构标签的嵌套还有CSS的名字在网页位置等后教你们怎么去抓电影等网站并且把内容归类好方便查阅
下面是我抓去某电影网站的数据及归类效果掩饰:

GJM : Python简单爬虫入门 (一) [转载]的更多相关文章
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题) 此工具在搜索 ...
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- python网络爬虫入门(二)
刚去看了一下,18年2月份写了第一篇关于爬虫的文章(仅仅介绍了使用requests库去获取HTML代码),一年多之后看来很稚嫩也没有多少参考的意义,但没想着要去修改它,留着也是一个回忆吧.至少证明着我 ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
随机推荐
- ASP.NET MVC 拦截器IResultFilter
在ASP.NET MVC中,有一个Result拦截器,实现ResultFilter需要继承一个类(System.Web.Mvc.FilterAttribute)和实现一个类(System.Web.Mv ...
- KnockoutJS 3.X API 第四章 数据绑定(4) 控制流with绑定
with绑定的目的 使用with绑定的格式为data-bind="with:attribute",使用with绑定会将其后所跟的属性看作一个新的上下文进行绑定.with绑定内部的所 ...
- SQL Server的日期和时间类型
Sql Server使用 Date 表示日期,time表示时间,使用datetime和datetime2表示日期和时间. 1,秒的精度是指使用多少位小数表示秒 DateTime数据类型秒的精度是3,D ...
- SQL Server 2014云特性:无缝集成公有云
本篇是我在IT168的约稿,原文地址:http://tech.it168.com/a2014/0620/1637/000001637358_all.shtml IT行业已经进入了云时代,未 ...
- ObjectOutputStream和ObjectInputStream
官方解释: ObjectOutputStream 将 Java 对象的基本数据类型和图形写入 OutputStream.可以使用 ObjectInputStream 读取(重构)对象.通过使用流中的文 ...
- 详细了解HTML标签内容模型
前面的话 HTML核心的部分莫过于标签(tag)了.标签是用来描述文档中的各自内容基本单元,不同标签表示着不同的含义,标签之间的嵌套表示了内容之间的结构. HTML标签在HTML5中内容模型拓展到了7 ...
- 让你心动的 HTML5 & CSS3 效果【附源码下载】
这里集合的这组 HTML5 & CSS3 效果,有的是网站开发中常用的.实用的功能,有的是先进的 Web 技术的应用演示.不管哪一种,这些案例中的技术都值得我们去探究和学习. 超炫的 HTML ...
- PHP面向对象中的重要知识点(三)
1. namespace: 和C++中的名字空间很像,作用也一样,都是为了避免在引用较多第三方库时而带来的名字冲突问题.通过名字空间,即便两个class的名称相同,但是因为位于不同的名字空间内,他们仍 ...
- ProGuard代码混淆技术详解
前言 受<APP研发录>启发,里面讲到一名Android程序员,在工作一段时间后,会感觉到迷茫,想进阶的话接下去是看Android系统源码呢,还是每天继续做应用,毕竟每天都是画UI ...
- 聚合索引(clustered index) / 非聚合索引(nonclustered index)
以下我面试经常问的2道题..尤其针对觉得自己SQL SERVER 还不错的同志.. 呵呵 很难有人答得好.. 各位在我收集每个人擅长的东西时,大部分都把SQL SERVER 标为Expert,看看是否 ...