caffe初步实践---------使用训练好的模型完成语义分割任务
caffe刚刚安装配置结束,乘热打铁!
(一)环境准备
前面我有两篇文章写到caffe的搭建,第一篇cpu only ,第二篇是在服务器上搭建的,其中第二篇因为硬件环境更佳我们的步骤稍显复杂。其实,第二篇也仅仅是caffe的初步搭建完成,还没有编译python接口,那么下面我们一起搞定吧!
首先请读者再回过头去看我的《Ubuntu16.04安装配置Caffe》( http://www.cnblogs.com/xuanxufeng/p/6150593.html )
在这篇博文的结尾,我们再增加编译Python接口,而这部分内容请参考我的博文《Ubuntu14.04搭建Caffe(仅cpu)》 http://www.cnblogs.com/xuanxufeng/p/6016945.html ,这篇文章从编译Python接口部分看就好了。
(二)下载模型
作者在github上开源了代码:Fully Convolutional Networks,我们首先将代码下载并且解压到家目录下。
项目文件结构很清晰,如果想train自己的model,只需要修改一些文件路径设置即可,这里我们应用已经train好的model来测试一下自己的图片:
我们下载voc-fcn32s,voc-fcn16s以及voc-fcn8s的caffemodel(根据提供好的caffemodel-url),fcn-16s和fcn32s都是缺少deploy.prototxt的,我们根据train.prototxt稍加修改即可。注意,这里的caffemode-url其实在各个模型的文件夹下面都已经提供给我们了,请读者细心找一找,看看是不是每一个文件夹下面都有一个caffemode-url的文件?打开里面会有模型的下载地址!
(三)修改infer.py文件
- caffe path的加入,由于FCN代码和caffe代码是独立的文件夹,因此,须将caffe的Python接口加入到path中去。这里有两种方案,一种是在所有代码中出现
import caffe之前,加入:
import sys
sys.path.append('caffe根目录/python')
- 另一种一劳永逸的方法是:在终端或者bashrc中将接口加入到
PYTHONPATH中:
export PYTHONPATH=caffe根目录/python:$PYTHONPATH
本次我们采用后者。
在解压代码的根目录下找到一个文件:infer.py。略微修改infer.py,就可以测试我们自己的图片了,请大家根据自己实际情况来进行修改。
im = Image.open('voc-fcn8s/test.jpeg') 这里指的是测试图片路径!
net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST) ,这里指的是voc-fcn8s文件下的部署文件和模型。注意,fcn下每一个模型其实都对应于一个文件夹,而每个文件夹下应当放着这个模型的caffemodel文件和prototxt文件!
plt.savefig('test.png') ,这里指的是最终分割的结果应当放置在哪个路径下,大家都知道,语义分割的结果应当是一张图片!
修改完后的infer.py如下所示:
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import caffe # load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe
im = Image.open('voc-fcn8s/test.jpeg')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= np.array((104.00698793,116.66876762,122.67891434))
in_ = in_.transpose((2,0,1)) # load net
net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_
# run net and take argmax for prediction
net.forward()
out = net.blobs['score'].data[0].argmax(axis=0) plt.imshow(out,cmap='gray');
plt.axis('off')
plt.savefig('test.png')
#plt.show()
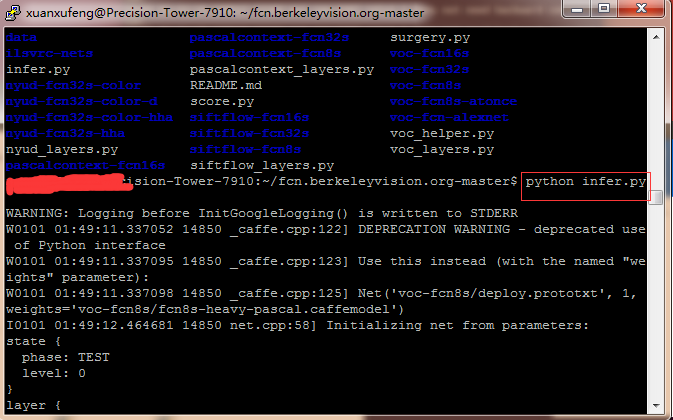
运行结束后会在软件的根目录下生成一个分割好的图片test.png!
我们可以看一下原始图片和最后生成的图片的区别:


可能会遇到的问题:
(1)no display name and no $DISPLAY environment variable
其实,在Ubuntu虚拟终端里执行python infer.py是没有任何错误的,但是我是通过远程访问连接服务器的方式运行程序的。所以在执行到最后的时候会报这个错。不过不要害怕,
在stackoverflow中找到了终极解决办法:
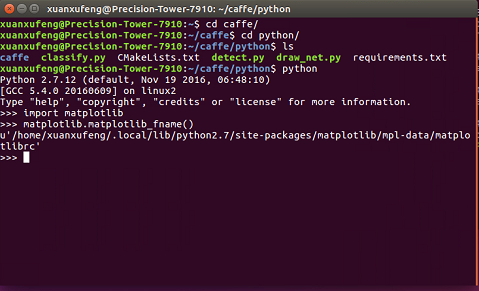
如图中所示的步骤,找到matplotlibrc,将backend从tkAGG修改为AGG。
sudo gedit /home/xuanxufeng/.local/lib/python2./site-packages/matplotlib/mpl-data/matplotlibrc

再次在putty中执行就没有任何问题了!
(2)在执行python infer.py时可能会提示缺少某一两个模块。
这个不用担心,都是小问题,百度很容易搜到,一两个命令安装就好了~
(四) 结束语
从开始读论文到现在,也算是前进了一小步,可以看见的一小步。在往后,随着实验的一步步进行,我还会再更新模型的训练以及训练数据集的制作!请各位看官耐心等待!
caffe初步实践---------使用训练好的模型完成语义分割任务的更多相关文章
- (原)ubuntu16在torch中使用caffe训练好的模型
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/5783006.html 之前使用的是torch,由于其他人在caffe上面预训练了inception模型 ...
- Caffe使用step by step:使用自己数据对已经训练好的模型进行finetuning
在经过前面Caffe框架的搭建以及caffe基本框架的了解之后,接下来就要回到正题:使用caffe来进行模型的训练. 但如果对caffe并不是特别熟悉的话,从头开始训练一个模型会花费很多时间和精力,需 ...
- 基于深度学习和迁移学习的识花实践——利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练(属于模型迁移)
基于深度学习和迁移学习的识花实践(转) 深度学习是人工智能领域近年来最火热的话题之一,但是对于个人来说,以往想要玩转深度学习除了要具备高超的编程技巧,还需要有海量的数据和强劲的硬件.不过 Tens ...
- 【神经网络与深度学习】Caffe使用step by step:使用自己数据对已经训练好的模型进行finetuning
在经过前面Caffe框架的搭建以及caffe基本框架的了解之后,接下来就要回到正题:使用caffe来进行模型的训练. 但如果对caffe并不是特别熟悉的话,从头开始训练一个模型会花费很多时间和精力,需 ...
- 利用caffe的solverstate断点训练
你可以从系统 /tmp 文件夹获取,名字是什么 caffe.ubuntu.username.log.INFO.....之类 ====================================== ...
- 第三十二节,使用谷歌Object Detection API进行目标检测、训练新的模型(使用VOC 2012数据集)
前面已经介绍了几种经典的目标检测算法,光学习理论不实践的效果并不大,这里我们使用谷歌的开源框架来实现目标检测.至于为什么不去自己实现呢?主要是因为自己实现比较麻烦,而且调参比较麻烦,我们直接利用别人的 ...
- Caffe上用SSD训练和测试自己的数据
学习caffe第一天,用SSD上上手. 我的根目录$caffe_root为/home/gpu/ljy/caffe 一.运行SSD示例代码 1.到https://github.com ...
- 【神经网络与深度学习】Caffe Model Zoo许多训练好的caffemodel
Caffe Model Zoo 许多的研究者和工程师已经创建了Caffe模型,用于不同的任务,使用各种种类的框架和数据.这些模型被学习和应用到许多问题上,从简单的回归到大规模的视觉分类,到Siames ...
- Caffe系列4——基于Caffe的MNIST数据集训练与测试(手把手教你使用Lenet识别手写字体)
基于Caffe的MNIST数据集训练与测试 原创:转载请注明https://www.cnblogs.com/xiaoboge/p/10688926.html 摘要 在前面的博文中,我详细介绍了Caf ...
随机推荐
- Jenkins_Maven_Git 持续集成及自动化部署 GentOS版
1.安装JDK JDK下载: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 新 ...
- 论文 查重 知网 万方 paperpass
相信各个即将毕业的学生或在岗需要评职称.发论文的职场人士,论文检测都是必不可少的一道程序.面对市场上五花八门的检测软件,到底该如何选择?选择查重后到底该如何修改?现在就做一个知识的普及.其中对于中国的 ...
- android性能测试与调优:使用 DDMS 查看内存分配情况
1. 启用自己的APK后 2. 点击左边更新heap 3. 点击右边的heap中的垃圾回收cause GC,等待数秒出现回收内存与数据情况(由于内存回收了APK运行出现异常crash) 4. 点击一个 ...
- 图表控件FlowChart.NET详细介绍及免费下载地址
FlowChart.NET是一款专业的.NET平台下的流程图及图表控件,它可以运行在任何C#, VB.NET或Delphi.NET语言编写的软件中.能够帮助你创建工作流程图.对象层次和关系图.网络拓扑 ...
- shell 中变量前"?"的作用
example: if ($?USER == 0 || $?prompt == 0) then .... if ( $?DS_HOME != 0 ) then if ( ${? ...
- angular 指令作用域 scope
转载自:https://segmentfault.com/a/1190000002773689 下面我们就来详细分析一下指令的作用域. 在这之前希望你对AngularJS的Directive有一定的了 ...
- 基于vue2.0的分页组件开发
今天安排的任务是写基于vue2.0的分页组件,好吧,我一开始是觉得超级简单的,但是越写越写不出来,写的最后乱七八糟的都不知道下句该写什么了,所以重新捋了思路,小结一下- 首先写组件需要考虑: 要从父组 ...
- Jquery和Javascript 实际项目中写法基础-弹出窗和弹出层 (4)
一.实际项目中有很多如下界面效果. 二.该效果可以归结为弹出窗或者弹出层来实现的,为什么这么说?看如下代码: <!DOCTYPE html> <html> & ...
- JavaScript闭包模型
JavaScript闭包模型 ----- [原创翻译]2016-09-01 09:32:22 < 一> 闭包并不神秘 本文利用JavaScript代码来阐述闭包,目的是为了使普通 ...
- (原创)基于CloudStack的平安云-云主机的生命周期
一.购买云主机1.条件筛选 涉及环境.应用系统.区域.网络.操作系统.套餐.期限.数量筛选2.校验 2.1 应用系统角色权限校验 2.2 应用系统可用配置校验 2.3 产品区域是否下架 ...