Oracle 统计信息介绍
- dba_autotask_task 字段status值ENABLED
- dba_autotask_client 字段status值ENABLED
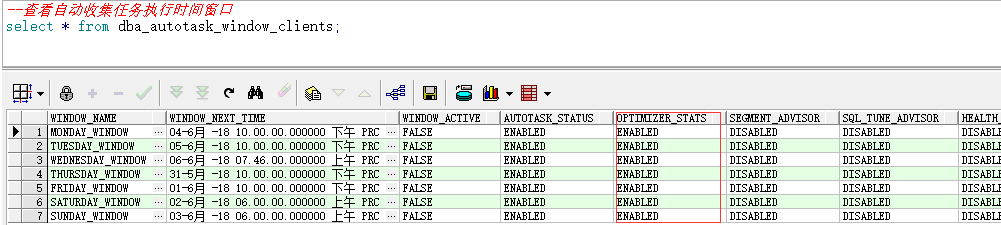
- dba_autotask_window_clients 字段AUTOTASK_STATUS值ENABLED OPTIMIZER_STATS值ENABLED WINDOW_ACTIVE值FALSE
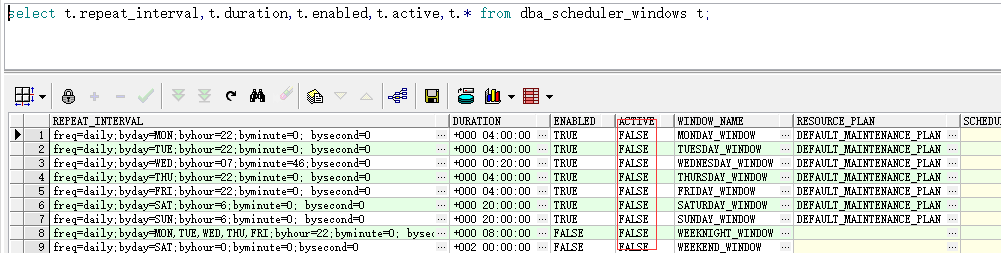
- dba_scheduler_windows 字段ENABLED值TRUE 字段ACTIVE值FALSE 字段DURATION值大于分钟
- dba_scheduler_jobs 字段ENABLED值TRUE

2、统计信息调用总过程查看视图dba_scheduler_programs

3、统计信息执行状态dba_autotask_client,可以通过如下进行修改,执行 DBMS_AUTO_TASK_ADMIN包,会更新dba_autotask_client的status字段和dba_autotask_window_clients的OPTIMIZER_STATS,SEGMENT_ADVISOR,SQL_TUNE_ADVISOR字段。
BEGIN
DBMS_AUTO_TASK_ADMIN.enable(client_name => 'auto optimizer stats collection',
operation => NULL,
window_name => 'MONDAY_WINDOW');
END; BEGIN
DBMS_AUTO_TASK_ADMIN.disable(client_name => 'auto optimizer stats collection',
operation => NULL,
window_name => NULL);
END;

4、如果执行DBMS_AUTO_TASK_ADMIN包不加参数,则更改dba_autotask_window_clients的AUTOTASK_STATUS字段
BEGIN
DBMS_AUTO_TASK_ADMIN.enable();
END;
BEGIN
DBMS_AUTO_TASK_ADMIN.disable();
END;

5、视图dba_scheduler_windows是统计信息执行的各种细节属性如(执行时间,执行时长等),可以通过如下进行设置
--设置开始时间
BEGIN
DBMS_SCHEDULER.SET_ATTRIBUTE(name => '"SYS"."WEDNESDAY_WINDOW"',
attribute => 'REPEAT_INTERVAL',
value => 'freq=daily;byday=WED;byhour=07;byminute=46;bysecond=0');
END;
--设置执行时长,如果设置值小于10分钟,统计信息貌似不能搜集
BEGIN
DBMS_SCHEDULER.SET_ATTRIBUTE(name => '"SYS"."WEDNESDAY_WINDOW"',
attribute => 'DURATION',
VALUE => '+000 00:20:00');
END;
--禁用窗口,禁用后dba_autotask_window_clients视图相关信息消失
BEGIN
dbms_scheduler.disable(name => 'WEDNESDAY_WINDOW', force => TRUE);
END;
--启用窗口
BEGIN
dbms_scheduler.enable(name => 'WEDNESDAY_WINDOW');
END;
--停止JOB
BEGIN
dbms_scheduler.stop_job('ORA$AUTOTASK_CLEAN');
END;
--手动打开窗口
BEGIN
dbms_scheduler.open_window('WEDNESDAY_WINDOW');
END;
--关闭窗口
BEGIN
dbms_scheduler.close_window('WEDNESDAY_WINDOW');
END;
Oracle 统计信息介绍的更多相关文章
- 有关Oracle统计信息的知识点[z]
https://www.cnblogs.com/sunmengbbm/p/5775211.html 一.什么是统计信息 统计信息主要是描述数据库中表,索引的大小,规模,数据分布状况等的一类信息.例如, ...
- 有关Oracle统计信息的知识点
一.什么是统计信息 统计信息主要是描述数据库中表,索引的大小,规模,数据分布状况等的一类信息.例如,表的行数,块数,平均每行的大小,索引的leaf blocks,索引字段的行数,不同值的大小等,都属于 ...
- [Oracle] oracle统计信息
Oracle统计信息 Oracle数据库里的统计信息可以分为6种类型: 表的统计信息 索引的统计信息 列的统计信息 系统统计信息 数据字典统计信息 内部对象统计信息 图 1: Oracle统计信息 基 ...
- oracle统计信息
手工刷ORACLE统计信息 select count(1) from LOG_TRX_DETAIL; select * from user_tab_statistics where table_n ...
- 收集oracle统计信息
优化器统计范围: 表统计: --行数,块数,行平均长度:all_tables:NUM_ROWS,BLOCKS,AVG_ROW_LEN:列统计: --列中唯一值的数量(NDV),NULL值的数量,数据分 ...
- Oracle 统计信息收集
官网网址参考: https://docs.oracle.com/cd/B19306_01/appdev.102/b14258/d_stats.htm#CIHBIEII https://docs.ora ...
- 测试Oracle统计信息的导出导入
背景:有时我们会希望可以对Oracle的统计信息整体进行导出导入.比如在数据库迁移前后,希望统计信息保持不变;又比如想对统计信息重新进行收集,但是担心重新收集的结果反而引发性能问题,想先保存当前的统计 ...
- Oracle 统计信息
Oracle数据库中的统计信息是这样一组数据:它存储在数据字典中,且从多个维度描述了Oracle数据库里对象的详细信息. CBO会利用这些统计信息来计算目标SQL各种可能的,不同的执行路径的成本,从中 ...
- 【练习】ORACLE统计信息--直方图
①创建表tSQL> create table t as select * from dba_objects; Table created. --收集直方图 SQL> exec dbms_s ...
随机推荐
- 如何开发优质的 Flutter App:应用架构的搭建
各位读者朋友们,好久不见了! 最近博主一直在忙于工作以及写<Flutter入门与应用实战>的书,所以没有时间打理博客.今天来给大家分享一个博主在GitChat上发起的一场Chat. 下面是 ...
- Spring源码阅读-IoC容器解析
目录 Spring IoC容器 ApplicationContext设计解析 BeanFactory ListableBeanFactory HierarchicalBeanFactory Messa ...
- Hadoop 学习之路(二)—— 集群资源管理器 YARN
一.hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是hadoop 2.0 引入的集群资源管理系统.用户可以将各种服务框架部署 ...
- 关于起点中文网的一个我自认为是BUG的BUG(花了我一毛三分钱才实验出来的)
因为最近在学关于网页的东西,所以便有了每看一个网页,总得先看看这个网页的源码的习惯. 突然我就想到了,起点中文网在看小说的界面是不允许复制粘贴,甚至连点右键都不会有反应, 那么如果我查看源码,能否复制 ...
- Spring Boot2(九):整合Jpa的基本使用
一.前言 今天早上看到一篇微信文章,说的是国内普遍用的Mybatis,而国外确普遍用的是Jpa.我之前也看了jpa,发现入门相当容易.jpa对于简单的CRUD支持非常好,开发效率也会比Mybatis高 ...
- kubernetes实战之consul篇及consul在windows下搭建consul简单测试环境
consul是一款服务发现中间件,1.12版本后增加servicemesh功能.consul是分布式的,可扩展的,高可用的根据官方文档介绍,目前已知最大的consul集群有5000个节点,consul ...
- HDU 6019:MG loves gold(暴力set)
http://acm.hdu.edu.cn/showproblem.php?pid=6019 题意:给出n个颜色的物品,你每次取只能取连续的不同颜色的物品,问最少要取多少次. 思路:从头往后扫,用se ...
- scrapy基础知识之scrapy自动下载图片pipelines
需要在settings.py配置: ITEM_PIPELINES = { 'scrapy.pipelines.images.ImagesPipeline': 1, }import os IMAGES_ ...
- Innovus教程 - Flow系列 - MMMC分析环境的配置概述(理论+实践+命令)
本文转自:自己的微信公众号<集成电路设计及EDA教程> <Innovus教程 - Flow系列 - MMMC分析环境的配置概述(理论+实践+命令)> 轻轻走过,悄悄看过,无 ...
- 利用Python模拟GitHub登录
最近学习了Fiddler抓包工具的简单使用,通过抓包,我们可以抓取到HTTP请求,并对其进行分析.现在我准备尝试着结合Python来模拟GitHub登录. Fiddler抓包分析 首先,我们想要模拟一 ...