Python爬虫基础——XPath语法的学习与lxml模块的使用
XPath与正则都是用于数据的提取,二者的区别是:
- 正则:功能相对强大,写起来相对复杂;
- XPath:语法简单,可以满足绝大部分的需求,但不能爬取注释代码(下一篇会讲到);
所以,如果你可以根据自己的需要进行选择。
一、首先,我们需要为Google浏览器配置XPath插件:
请自行学习,效果如下:

二、XPath的语法:
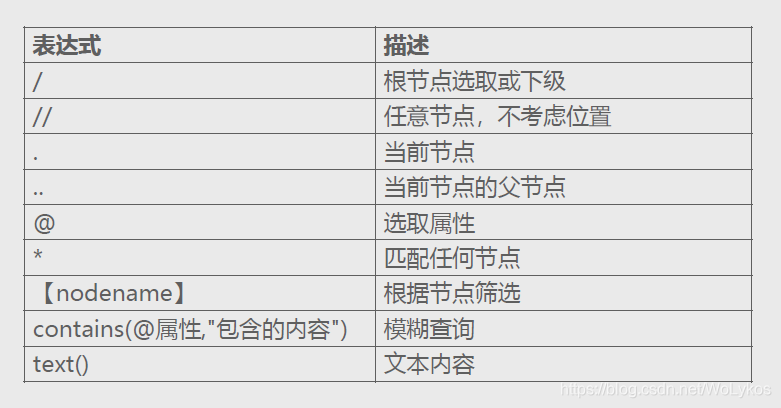
注意:
XPath的索引从1开始。
三、XPath的案例:
一级分类:
//h3[@class="classify_c_h3"]/a/text()

二级分类:
//div[@class="classify_list"]/span/a/text()

模糊查询:
//div[contains(@class,"classify_list")]/span/a/text()

四、lxml模块的使用
import lxml.etree as le
with open('edu.html', 'r', encoding='utf-8') as f:
html = f.read()
# print(html)
# 转换为XPath对象
html_x = le.HTML(html)
# print(html_x)
# 匹配一二级分类的父标签
div_x_s = html_x.xpath('//div[@class="classify_cList"]') # 直接从HTML中取则不用加.
data_s = []
for div_x in div_x_s:
# 一级分类
category1 = div_x.xpath('./h3/a/text()')[0] # 记得加.
# 二级分类
category2_s = div_x.xpath('./div/span/a/text()') # 表示从当前节点进行筛选
data_s.append(
dict(
category1=category1,
category2_s=category2_s
)
)
print(data_s)
for data in data_s:
print(data.get('category1'))
for category2 in data.get('category2_s'):
print(' ', category2)
为我心爱的女孩~~
Python爬虫基础——XPath语法的学习与lxml模块的使用的更多相关文章
- python爬虫:XPath语法和使用示例
python爬虫:XPath语法和使用示例 XPath(XML Path Language)是一门在XML文档中查找信息的语言,可以用来在XML文档中对元素和属性进行遍历. 选取节点 XPath使用路 ...
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
- Python爬虫:Xpath语法笔记
一.选取节点 常用的路劲表达式: 表达式 描述 实例 nodename 选取nodename节点的所有子节点 xpath(‘//div’) 选取了div节点的所有子节点 / 从根节点选取 xpat ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- 非常全的一份Python爬虫的Xpath博文
非常全的一份Python爬虫的Xpath博文 Xpath 是 python 爬虫过程中非常重要的一个用来定位的一种语法. 一.开始使用 首先我们需要得到一个 HTML 源代码,用来模拟爬取网页中的源代 ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- MySQL常用的查询语句回顾
让你快速复习语句的笔记宝典. create table users( username varchar(20) primary key, userpwd varchar(20) ) alt ...
- python3 之 内置函数range()
一.语法: range(stop) range(start,stop,step) start:计数从start开始,默认是从0开始.eg:range(5)等价于range(0,5) stop:计数到s ...
- iOS开发tips-PhotoKit
概述 PhotoKit应该是iOS 8 开始引入为了替代之前ALAssetsLibrary的相册资源访问的标准库,后者在iOS 9开始被弃用.当然相对于ALAssetsLibrary其扩展性更高,ap ...
- java中的运算,+-* /% | ^ &
java中运算都是操作符号,那么整形默认为int,双精度默认为都double 整数 看案例: 无法编译通过:操作默认为int,接受结果为int,所以这个地方编译无法通过,所以需要强制类型转换 再看案例 ...
- ganglia 一站式部署
1 ganglia集群监测系统简介 1.1 ganglia简介 ganglia是一款为HPC(高性能计算) 集群设计的可扩展性 的分布式监控系统,它可以监视和显示集群中节点的各种状 ...
- Django简介以及MVC模式
一.简介 Django,是当前Python世界里最负盛名且成熟的网络框架.最初用来制作在线新闻的Web站点. Django是一个基于python的web重量级框架 重指的是为发开者考虑的多 采用了MV ...
- SpringBoot+Vue+WebSocket 实现在线聊天
一.前言 本文将基于 SpringBoot + Vue + WebSocket 实现一个简单的在线聊天功能 页面如下: 在线体验地址:http://www.zhengqingya.com:8101 二 ...
- 程序员的算法课(3)-递归(recursion)算法
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
- Chapter 05—Advanced data management(Part 2)
二. 控制流 statement:一个单独的R语句或者是一个复合的R语句: cond:条件表达式,为TRUE或FALSE: expr:数字或字符表达式: seq:数字或字符串的顺序. 1.循环语句:f ...
- Day01-初识 Python
1.CPU/内存/硬盘/操作系统 CPU :计算机的运算和处理中心,相当于人类的大脑. 内存 :暂时存储数据,临时加载数据应用程序. 硬盘 :长期存储数据. 操作系统:一个软件,连接计算机的硬件与所有 ...