Redis自动化安装以及集群实现
#!/bin/bash
set -e
if [ $# -lt ]; then
echo "$(basename $0): Missing script argument"
echo "$(installdir $0) [installfilename] [port] "
exit
fi
PotInUse=`netstat -anp | awk '{print $4}' | grep $ | wc -l`
if [ $PotInUse -gt ];then
echo "ERROR" $ "Port is used by another process!"
exit
fi
basedir=$
installdir=$
installfilename=$
port=$
cd $basedir
tar -zxvf $installfilename.tar.gz >/dev/null >& &
cd $installfilename
mkdir -p $installdir
make PREFIX=$installdir install
sleep 1s
cp $basedir/redis.conf $installdir sed -i "s/instance_port/$port/g" $installdir/redis.conf
sleep 1s
cd $installdir
./bin/redis-server redis.conf >/dev/null >& &
配置文件模板
################################## INCLUDES ###################################
# include /path/to/local.conf
# include /path/to/other.conf ################################## MODULES #####################################
# loadmodule /path/to/my_module.so
# loadmodule /path/to/other_module.so ################################## NETWORK #####################################
bind 127.0.0.1 & your ip
port instance_port
tcp-backlog 511
timeout 0
tcp-keepalive 300 ################################# GENERAL #####################################
daemonize yes
supervised no
pidfile ./redis_instance_port.pid
loglevel notice
logfile ./redis_log.log
databases 16
always-show-logo yes ################################ SNAPSHOTTING ################################
save 900 1
save 300 10
save 60 10000 stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir ./ ################################# REPLICATION #################################
# masterauth <master-password>
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
replica-priority 100 ################################## SECURITY ###################################
requirepass your_passwrod ################################### CLIENTS ####################################
# maxclients 10000 ############################## MEMORY MANAGEMENT ################################
# maxmemory <bytes>
# maxmemory-policy noeviction
# maxmemory-samples 5
# replica-ignore-maxmemory yes ############################# LAZY FREEING ####################################
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no ############################## APPEND ONLY MODE ###############################
appendonly no appendfilename "appendonly.aof" # appendfsync always
appendfsync everysec
# appendfsync no no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes ################################ LUA SCRIPTING ###############################
lua-time-limit 5000 ################################ REDIS CLUSTER ###############################
cluster-enabled yes
# cluster-replica-validity-factor 10
# cluster-require-full-coverage yes
# cluster-replica-no-failover no ########################## CLUSTER DOCKER/NAT support ######################## ################################## SLOW LOG ###################################
slowlog-log-slower-than 10000
slowlog-max-len 128 ################################ LATENCY MONITOR ##############################
latency-monitor-threshold 0 ############################# EVENT NOTIFICATION ##############################
notify-keyspace-events "" ############################### ADVANCED CONFIG ###############################
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
# client-query-buffer-limit 1gb
# proto-max-bulk-len 512mb
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes ########################### ACTIVE DEFRAGMENTATION ####################### # Enabled active defragmentation
# activedefrag yes
# Minimum amount of fragmentation waste to start active defrag
# active-defrag-ignore-bytes 100mb
# Minimum percentage of fragmentation to start active defrag
# active-defrag-threshold-lower 10
# Maximum percentage of fragmentation at which we use maximum effort
# active-defrag-threshold-upper 100
# Minimal effort for defrag in CPU percentage
# active-defrag-cycle-min 5
# Maximal effort for defrag in CPU percentage
# active-defrag-cycle-max 75
# Maximum number of set/hash/zset/list fields that will be processed from
# the main dictionary scan
# active-defrag-max-scan-fields 1000
安装示例
sh redis_install.sh /usr/local/redis/ /usr/local/redis5/redis9008/ redis-5.0.4 9008
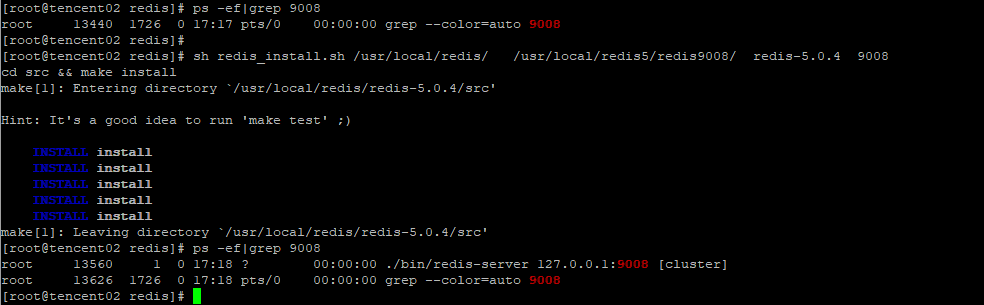
Redi实例的目录结构

基于Python的Redis自动化集群实现
基于Python的自动化集群实现,初始化节点为node_1~node_6,节点实例需要为集群模式,三主三从,自动化集群,分配slots,加入从节点,3秒钟左右完成
import redis #master
node_1 = {'host': '127.0.0.1', 'port': 9001, 'password': '***'}
node_2 = {'host': '127.0.0.1', 'port': 9002, 'password': '***'}
node_3 = {'host': '127.0.0.1', 'port': 9003, 'password': '***'}
#slave
node_4 = {'host': '127.0.0.1', 'port': 9004, 'password': '***'}
node_5 = {'host': '127.0.0.1', 'port': 9005, 'password': '***'}
node_6 = {'host': '127.0.0.1', 'port': 9006, 'password': '***'} redis_conn_1 = redis.StrictRedis(host=node_1["host"], port=node_1["port"], password=node_1["password"])
redis_conn_2 = redis.StrictRedis(host=node_2["host"], port=node_2["port"], password=node_2["password"])
redis_conn_3 = redis.StrictRedis(host=node_3["host"], port=node_3["port"], password=node_3["password"]) # cluster meet
redis_conn_1.execute_command("cluster meet {0} {1}".format(node_2["host"],node_2["port"]))
redis_conn_1.execute_command("cluster meet {0} {1}".format(node_3["host"],node_3["port"]))
print('#################flush slots #################')
redis_conn_1.execute_command('cluster flushslots')
redis_conn_2.execute_command('cluster flushslots')
redis_conn_3.execute_command('cluster flushslots')
print('#################add slots#################')
for i in range(0,16383+1):
if i <= 5461:
try:
redis_conn_1.execute_command('cluster addslots {0}'.format(i))
except:
print('cluster addslots {0}'.format(i) +' error')
elif 5461 < i and i <= 10922:
try:
redis_conn_2.execute_command('cluster addslots {0}'.format(i))
except:
print('cluster addslots {0}'.format(i) + ' error')
elif 10922 < i:
try:
redis_conn_3.execute_command('cluster addslots {0}'.format(i))
except:
print('cluster addslots {0}'.format(i) + ' error')
print()
print('#################cluster status#################')
print()
print('##################'+str(node_1["host"])+':'+str(node_1["port"])+'##################')
print(str(redis_conn_1.execute_command('cluster info'), encoding = "utf-8").split("\n")[0])
print('##################'+str(node_2["host"])+':'+str(node_2["port"])+'##################')
print(str(redis_conn_1.execute_command('cluster info'), encoding = "utf-8").split("\n")[0])
print('##################'+str(node_3["host"])+':'+str(node_3["port"])+'##################')
print(str(redis_conn_1.execute_command('cluster info'), encoding = "utf-8").split("\n")[0]) #slave cluster meet
redis_conn_1.execute_command("cluster meet {0} {1}".format(node_4["host"],node_4["port"]))
redis_conn_2.execute_command("cluster meet {0} {1}".format(node_5["host"],node_5["port"]))
redis_conn_3.execute_command("cluster meet {0} {1}".format(node_6["host"],node_6["port"])) #cluster nodes
print(str(redis_conn_1.execute_command('cluster nodes'), encoding = "utf-8")) ############################add salve in cluster##########################################
#slave cluster meet
print('################# cluster meet slave #################')
redis_conn_1.execute_command("cluster meet {0} {1}".format(node_4["host"],node_4["port"]))
redis_conn_2.execute_command("cluster meet {0} {1}".format(node_5["host"],node_5["port"]))
redis_conn_3.execute_command("cluster meet {0} {1}".format(node_6["host"],node_6["port"]))
sleep(5)
print('################# add slave in cluster #################') # get 主节点的node_id,按照主节点的顺序依次添加到主节点dict_cluster_nodes中,确保主从按照list中的顺序一一对应
redis_conn_1 = redis.StrictRedis(host=node_1["host"], port=node_1["port"], password=node_1["password"], decode_responses=True)
dict_cluster_nodes = redis_conn_1.cluster('nodes')
print(dict_cluster_nodes)
dict_master_node_id = {}
for m_node in master_node:
for key, values in dict_cluster_nodes.items():
if key[0:key.index('@')] == str(m_node["host"])+':'+str(m_node["port"]):
dict_master_node_id[key[0:key.index('@')]] = values['node_id']
# 输出示例
'''
{
'127.0.0.1:9001': '84f0c3a21ab6dd6965923915434cc62fc0f5cc2b',
'127.0.0.1:9002': 'b584f695eb9c1552c25f92e28a50c9ce62ad9ee9',
'127.0.0.1:9001': 'b95898c17761b448ea88bb9682bac9b69b045adc'
}
'''
# 依次添加slave节点
# 如何确保主从于list中的节点一一对应?
# 在主节点上任意一个节点上get 集群的node的时候,按照master节点顺序构造dict_cluster_nodes,然后遍历dict_cluster_nodes的时候自然就一一对应了。
node_index = 0
for s_node in slave_node:
slave_redis_conn = redis.StrictRedis(host=s_node["host"], port=s_node["port"], password=s_node["password"])
print(str(s_node["host"])+':'+str(s_node["port"]) + ' slave of----->' + str(master_node[node_index]["host"])+':'+str(master_node[node_index]["port"]))
repl_command = 'cluster replicate ' + dict_master_node_id[str(master_node[node_index]["host"])+':'+str(master_node[node_index]["port"])]
print(repl_command)
slave_redis_conn.execute_command(repl_command)
node_index = node_index + 1
'''
127.0.0.1:9004 slave of-----> 127.0.0.1:9001
cluster replicate 84f0c3a21ab6dd6965923915434cc62fc0f5cc2b
127.0.0.1:9005 slave of-----> 127.0.0.1:9002
cluster replicate b584f695eb9c1552c25f92e28a50c9ce62ad9ee9
127.0.0.1:9006 slave of-----> 127.0.0.1:9003
cluster replicate b95898c17761b448ea88bb9682bac9b69b045adc
'''
示例

这样一个Redis的集群,从实例的安装到集群的安装,环境依赖本身没有问题的话,基本上1分钟之内可以完成这个搭建过程。
Redis自动化安装以及集群实现的更多相关文章
- [k8s]kubespray(ansible)自动化安装k8s集群
kubespray(ansible)自动化安装k8s集群 https://github.com/kubernetes-incubator/kubespray https://kubernetes.io ...
- Redis单机安装以及集群搭建
今天主要来看一下Redis的安装以及集群搭建(我也是第一次搭建). 环境:CentOS 7.1,redis-5.0.7 一.单机安装 1.将Redis安装包放置服务器并解压 2.进入redis安装目录 ...
- linux下redis的安装和集群搭建
一.redis概述 1.1.目前redis支持的cluster特性: 1):节点自动发现. 2):slave->master 选举,集群容错. 3):Hot resharding:在线分片. 4 ...
- Redis集合 安装 哨兵集群 配置
redis相关 redis基础 redis发布订阅 redis持久化RDB与AOF redis不重启,切换RDB备份到AOF备份 redis安全配置 redis主从同步 redis哨兵集群 redis ...
- 利用ansible书写playbook在华为云上批量配置管理工具自动化安装ceph集群
首先在华为云上购买搭建ceph集群所需云主机: 然后购买ceph所需存储磁盘 将购买的磁盘挂载到用来搭建ceph的云主机上 在跳板机上安装ansible 查看ansible版本,检验ansible是否 ...
- Centos7下安装redis实战(单机版以及集群)
一.背景 因项目需要,要引入redis做缓存,就在centos7下亲自安装了一遍redis,刚好趁着这个机会就来把redis的概念以及单机版和集群版redis安装步骤记录下来,在此和大家一起分享. 二 ...
- Redis 3.0 Cluster集群配置
Redis 3.0 Cluster集群配置 安装环境依赖 安装gcc:yum install gcc 安装zlib:yum install zib 安装ruby:yum install ruby 安装 ...
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- redis + 主从 + 持久化 + 分片 + 集群 + spring集成
Redis是一个基于内存的数据库,其不仅读写速度快,每秒可以执行大约110000的写操作,81000的读取操作,而且其支持存储字符串,哈希结构,链表,集合丰富的数据类型.所以得到很多开发者的青睐.加之 ...
随机推荐
- Kettle6.1连接MongoDB报错
配置好mongodb连接之后,点击预览报下面的错: 报错: java.lang.NoClassDefFoundError: javax/crypto/spec/PBEKeySpec a ...
- 在vue中如何使用axios
1.前言 在Vue1.0的时候有一个官方推荐的 ajax 插件 vue-resource,但是自从 Vue 更新到 2.0 之后,官方就不再更新 vue-resource. 关于为什么放弃推荐? -& ...
- 『题解』洛谷P1314 聪明的质监员
更好的阅读体验 Portal Portal1: Luogu Portal2: LibreOJ Portal3: Vijos Description 小T是一名质量监督员,最近负责检验一批矿产的质量.这 ...
- 『题解』洛谷P3958 奶酪
Portal Portal1: Luogu Portal2: LibreOJ Portal3: Vijos Description 现有一块大奶酪,它的高度为\(h\),它的长度和宽度我们可以认为是无 ...
- windows使用docker运行mysql等工具(二)安装运行mysql
今天接着上一篇的内容继续来学习安装运行mysql.建议先阅读第一篇:windows安装docker 一 查看mysql版本 如果想知道mysql镜像具体有哪几个版本,需要去docker hub查看. ...
- Webpack 4 Tree Shaking 终极优化指南
几个月前,我的任务是将我们组的 Vue.js 项目构建配置升级到 Webpack 4.我们的主要目标之一是利用 tree-shaking 的优势,即 Webpack 去掉了实际上并没有使用的代码来减少 ...
- W与V模型的联系与区别
很多小白一定要注意: 看准那个是开发的工作哪个是测试的工作,不要弄混了!!! 软件测试的V模型 以“编码”为黄金分割线,将整个过程分为开发和测试,并且开发和测试之间是串行的关系 ...
- 100天搞定机器学习|Day56 随机森林工作原理及调参实战(信用卡欺诈预测)
本文是对100天搞定机器学习|Day33-34 随机森林的补充 前文对随机森林的概念.工作原理.使用方法做了简单介绍,并提供了分类和回归的实例. 本期我们重点讲一下: 1.集成学习.Bagging和随 ...
- [机器学习笔记]kNN进邻算法
K-近邻算法 一.算法概述 (1)采用测量不同特征值之间的距离方法进行分类 优点: 精度高.对异常值不敏感.无数据输入假定. 缺点: 计算复杂度高.空间复杂度高. (2)KNN模型的三个要素 kNN算 ...
- objc反汇编分析__strong和__weak
如题所说反汇编看__strong和__weak的真实样子,代码列举自然多,篇幅长不利于阅读,我就先搬出结论,后面是分析. 在NON-ARC环境,__strong和__weak不起作用.相反在ARC环境 ...