redis的安装与五种结构的使用
这次我们来说说我们的redis,在我们的redis的认知里,最熟悉的就是用redis作为缓存使用,还有我们的分布式session,其实还有很多redis的使用,还有redis的哨兵模式等等。
Redis(全称:Remote Dictionary Server 远程字典服务)是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。(百度百科)
安装(linux为例讲解):
1.先安装一下C语言的包,redis的底层是用C来写的,如果不安装可能安装的时候会报错的。输入$ yum install gcc
2.获得redis资源,输入 $ wget http://download.redis.io/releases/redis-5.0.5.tar.gz
3.开始安装,输入以下命令即可
$ tar -zxvf redis-5.0.5.tar.gz;
$ cd redis-5.0.5;
$ make
4.修改配置,直接输入vim redis.conf,然后跳转到136行(差不多就是136行,版本不同文件可能存在差异),daemonize no设置为daemonize yes,
5.启动,输入./src/redis-server redis.conf 即可启动了,输入ps -ef|grep redis可以看到redis是否启动成功。
6.输入./src/redis-cli 即可进入客户端,quit退出。

官网有如何安装的教程这里就不在继续赘述了。
redis的数据结构:
我们都知道redis是键值对的形式来存储数据的,其实内部还有几种结构的,也是我们常见常用的结构,这里来详细说一下。
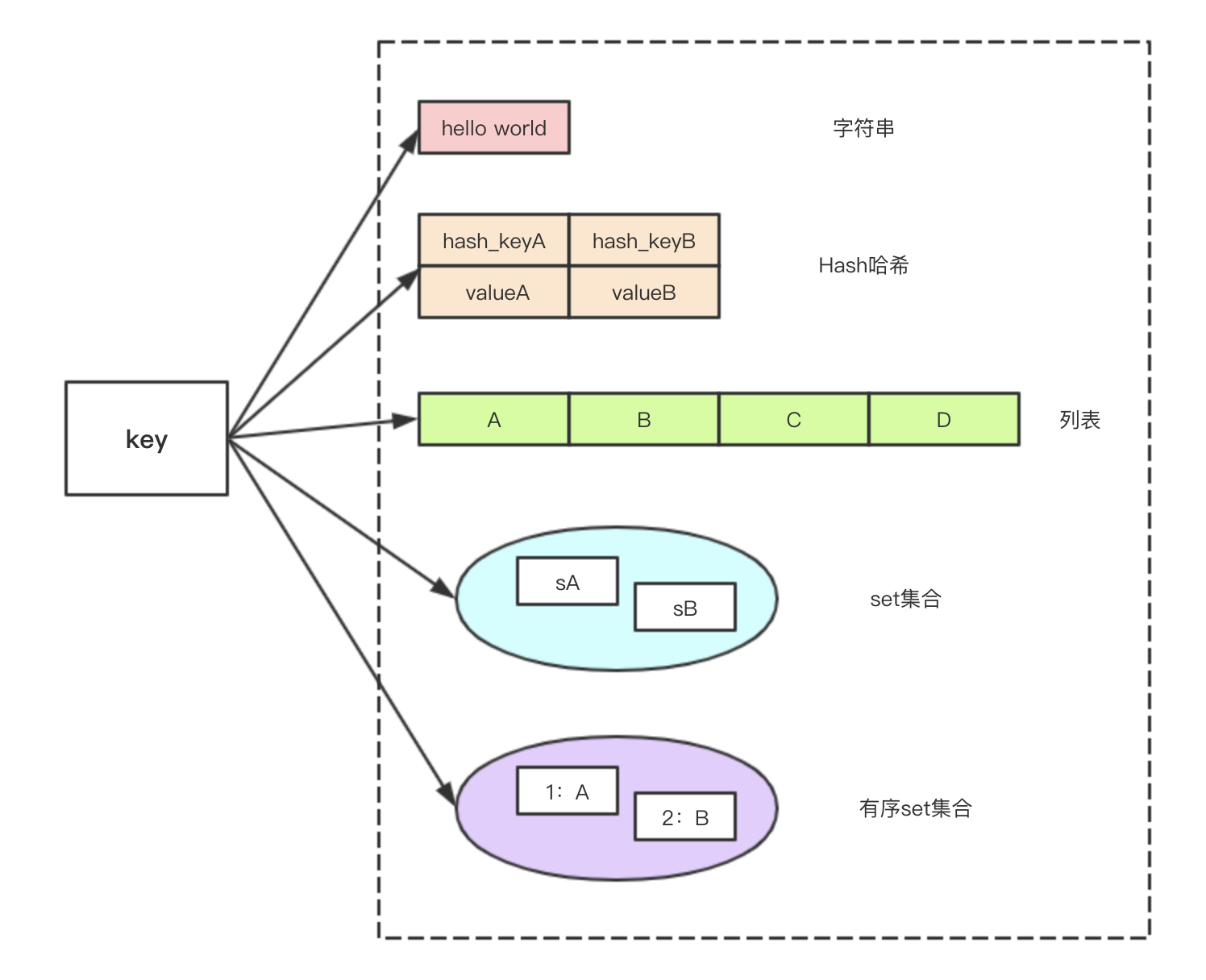
我们接下来会围绕这五种数据结构来展开去讲。
结构与常见命令场景
String常见操作
SET KEY VALUE //存入单个字符串键值对,最常见不过了,单值缓存,就不说啦。
MSET KEY VALUE//批量写入字符串,一般来存对象。看下实例
这里有一张职员表,内容如下
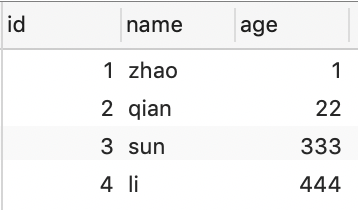
只存了姓名和年龄两个字段,以前我们的方式都是设置一个key,然后把姓名和年龄转为json然后再存储对吧。
我们来看一下我们的MSet命令是如何使用并存储的。
mset user:1:name zhang user:1:age 1
也就是说我们一口气直接把user表内id为1的对象都存在了redis里,然后我们用mget user:1:name user:1:age。就可以一次性取出来了。
SETNX //存入一个不存在的字符串键值对,我们来看一下实例。最简单的分布式锁就看可以用他来实现。
127.0.0.1:6379> setnx lock:user true
(integer) 1
127.0.0.1:6379> setnx lock:user true
(integer) 0
就是说只允许一次的写入,写入成功才会返回1,否则是0,我们的线程争抢就看谁优先写入啦。
GET KEY//取得一个键对应的字符串,上文提到过 ,不再赘述
MGET KEY//批量获得键对应的字符串,上文提到过 ,不再赘述
EXPIRE KEY SECONDS //设置一个键的过期时间,单位是秒
127.0.0.1:6379> expire lock:user 1
(integer) 1
127.0.0.1:6379> get lock:user
(nil)
原子加减
INCR key //将key中存储的数字值加1,一般用在新闻点赞计数操作 incr {文章:id}
127.0.0.1:6379> incr article:xiaocai
(integer) 1
127.0.0.1:6379> incr article:xiaocai
(integer) 2
127.0.0.1:6379> incr article:xiaocai
(integer) 3
127.0.0.1:6379> incr article:xiaocai
(integer) 4
DECR key //将key中存储的数字值减1,一般用在新闻点赞计数操作
INCRBY KEY increment //将key所存储的值加上increment
DECRBY key decrement //将key所存储的值减去decrement
哈希Hash常见操作
hash结构和我们的String有些不同,原本String是一个key对应一个value,而我们的hash是一个redis_key,对应一组值,内部还有hash_key对应我们的hash_value。但是用法几乎是一致
hset key hash_key hash_value //存储一个hash表的key的键值对
127.0.0.1:6379> hset user 1:name zhao
(integer) 0
127.0.0.1:6379> hget user 1:name
"zhao"
hsetnx key hash_key hash_value //存储一个不存在的hash表的key的键值对
127.0.0.1:6379> hsetnx lock user:locak true
(integer) 1
127.0.0.1:6379> hsetnx lock user:locak true
(integer) 0
hmset key hash_key hash_value //存储一个hash表的多个key的键值对
127.0.0.1:6379> hmset user 1:name zhoao 1:age 11
OK
127.0.0.1:6379> hmget user 1:name 1:age
1) "zhoao"
2) "11"
hget key hash_key //获取哈希表key对应的多个hash键值
hdel key hash_key //删除哈希表key中的hash键值对
hlen key //返回所有哈希表key中该键的数量
127.0.0.1:6379> hlen user
(integer) 2
hgetall key //返回所有哈希表key中所有键的键值对
127.0.0.1:6379> hgetall user
1) "1:name"
2) "zhoao"
3) "1:age"
4) "11"
hash哈希的有点在于,对于同类的数据更好的整合在了一起,方便数据的管理,相比String操作消耗的内存与cpu更小(以后会详细说明为什么小),空间占用也是比String要小的,但在集群的架构下不适合大规模的使用。
列表常见操作
lpush key value //将一个或者多个值value插入到key列表的最左边left
127.0.0.1:6379> lpush liredis a
(integer) 1
127.0.0.1:6379> lpush liredis b
(integer) 2
127.0.0.1:6379> lpush liredis c
(integer) 3
rpush key value //将一个或者多个值value插入到key列表的最右边right
127.0.0.1:6379> rpush liredis 1
(integer) 4
127.0.0.1:6379> rpush liredis 2
(integer) 5
127.0.0.1:6379> rpush liredis 3
(integer) 6
lpop key //移除并返回对应key的头元素(最左边的元素)
127.0.0.1:6379> lpop liredis
"c"
rpop key //移除并返回对应key的尾元素(最右边的元素)
127.0.0.1:6379> rpop liredis
"3"
lrange key start stop //返回列表key中start到stop的区间元素,需要注意的是角标是从0开始的,start和stop都包含在内的,不如我们输入 lrange redis_key 0 2 ,则表示取得第0,1,2三个元素。
127.0.0.1:6379> lrange liredis 1 2
1) "a"
2) "1"
blpop key timeout //从列表key的表头(最左侧)弹出第一个元素,若队列中没有元素,阻塞等待timeout秒,如果timeout=0,一直等待
127.0.0.1:6379> blpop liredis 1
1) "liredis"
2) "b"
127.0.0.1:6379> blpop liredis 1
1) "liredis"
2) "a"
127.0.0.1:6379> blpop liredis 1
1) "liredis"
2) "1"
127.0.0.1:6379> blpop liredis 1
1) "liredis"
2) "2"
127.0.0.1:6379> blpop liredis 1
(nil)
(1.04s)
brpop key timeout //从列表key的表尾(最右侧)弹出末尾元素,若队列中没有元素,阻塞等待timeout秒,如果timeout=0,一直等待
更好的理解我们的列表命令,我们可以从数据结构的角度来说一下。
栈:先进先出,也就是我们的Lpush+lpop,或者rpush+rpop就可以实现的。
队列:先进后出,也就是我们的Lpush+rpop,或者rpush+lpop就可以实现的。
阻塞队列:lpush+brpop也就可以实现啦。
set集合常见操作
sadd key member //往集合key中存入元素,元素存在则忽略
127.0.0.1:6379> sadd setredis 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd setredis 1 2
(integer) 0
srem key member //从集合key中删除元素
127.0.0.1:6379> srem setredis a
(integer) 0
127.0.0.1:6379> srem setredis 1
(integer) 1
smembers key //获取集合中的所有元素
127.0.0.1:6379> smembers setredis
1) "2"
2) "3"
3) "4"
4) "5"
scard key //获取集合key中的元素个数
127.0.0.1:6379> scard setredis
(integer) 4
sismember key member //判断member元素是否存在于集合key中
127.0.0.1:6379> sismember setredis a
(integer) 0
127.0.0.1:6379> sismember setredis 2
(integer) 1
srandmember key count //从集合key中选出count个元素,元素不从key中删除
127.0.0.1:6379> srandmember setredis 2
1) "5"
2) "4"
spop key count //从集合key中选出count个元素,元素从key中删除,抽奖小程序可以使用这个。
127.0.0.1:6379> spop setredis 1
1) "4"
127.0.0.1:6379> smembers setredis
1) "2"
2) "3"
3) "5"
集合的运算,我们在高中数学第一节课的时候就讲过集合(我们当时高中第一节讲的就是集合),不知道大家还记得交集并集补集都是什么意思吗?
sinter keyA keyB //集合keyA和集合B的交集,就是求既在集合A也在集合B内的元素
127.0.0.1:6379> sadd setA 1 2 3 4 5 6
(integer) 6
127.0.0.1:6379> sadd setB 5 6 7 9 10
(integer) 5
127.0.0.1:6379> sinter setA setB
1) "5"
2) "6"
sinterstore destination keyA keyB //将交集的结果存在新的集合destination中
127.0.0.1:6379> SINTERSTORE newset setA setB
(integer) 2
127.0.0.1:6379> smembers newset
1) "5"
2) "6"
sunion keyA keyB //得到集合A和集合B的并集结果
127.0.0.1:6379> SUNION setA setB
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "9"
9) "10"
sunionstore destination keyA keyB //将并集的结果存在新的集合destination中
sdiff keyA keyB //求集合A对于集合B的差集,也就是{A}-{B},更通俗一点说就是存在于集合A的,但是不存在于集合B的元素。
127.0.0.1:6379> smembers setA
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
127.0.0.1:6379> smembers setB
1) "5"
2) "6"
3) "7"
4) "9"
5) "10"
127.0.0.1:6379> sdiff setA setB
1) "1"
2) "2"
3) "3"
4) "4"
sdiffstore destination keyA keyB //将差集的结果存在新的集合destination中
扩展:如果我们是sdiff keyA keyB keyC //这里就表示{A}-{B}-{C}。不要琢磨什么这是A对于B和C并集的差集...乱不乱,自己都懵圈的。
集合A:[1,2,3,4,5,6]
集合B:[2,3,4]
集合C:[5,7,9]
这时我们输入sdiff keyA keyB keyC他的返回应该是[1,6]。因为{A}-{B}为{1,5,6},在用这个集合去掉C包含的元素,也就是5,最终得到集合[1,6]
有序zSet常见操作
zadd key score member score member //往有序集合key中加入带score分值的元素
127.0.0.1:6379> zadd zsetredis 1 zhaor 2 qian
(integer) 2
zrem key member //从有序集合key中删除元素
127.0.0.1:6379> zrem zsetredis zhaor
(integer) 1
zscore key member //返回有序集合key中元素member的分值
127.0.0.1:6379> zscore zsetredis qian
"2"
zincrby key increment menber //为有序集合key中元素member的分值加上increment数值
127.0.0.1:6379> ZINCRBY zsetredis 10 qian
"12"
ZCARD key //返回有序集合key中的元素个数
127.0.0.1:6379> ZCARD zsetredis
(integer) 2
zrange key start stop withscores//正序获取有序集合内从 start到stop下标的元素,加了withscores展示分值
127.0.0.1:6379> zrange zsetredis 0 999
1) "zhao"
2) "qian"
zrevrange key start stop withscores//倒序获取有序集合内从 start到stop下标的元素,加了withscores展示分值
127.0.0.1:6379> ZREVRANGE zsetredis 0 999
1) "qian"
2) "zhao"
正序倒序都是按照分值来排序的
zSet运算
zunioonstore destkey numkeys keyA keyB //求集合A和集合B的并集
127.0.0.1:6379> ZUNIONSTORE newzset 2 zsetA zsetb
(integer) 4
127.0.0.1:6379> ZRANGE newzset 0 1111
1) "wuliu"
2) "zhaogsan"
3) "wangwu"
4) "lisi"
zinterstore destkey numkeys KeyA keyB //求集合A和集合B的交集,只看元素,不看分值。
127.0.0.1:6379> ZINTERSTORE newset 2 zsetA zsetb
(integer) 1
127.0.0.1:6379> zrange newset 0 1111
1) "lisi"


最进弄了一个公众号,小菜技术,欢迎大家的加入

redis的安装与五种结构的使用的更多相关文章
- Redis安装及五种数据类型
redis是非关系型数据库,也叫内存数据库.数据是键值对的形式,通过key查找value 安装Radis:6379 sudo apt-get update sudo apt-get install r ...
- 【Redis的那些事 · 上篇】Redis的介绍、五种数据结构演示和分布式锁
Redis是什么 Redis,全称是Remote Dictionary Service,翻译过来就是,远程字典服务. redis属于nosql非关系型数据库.Nosql常见的数据关系,基本上是以key ...
- Redis(1)---五种数据结构
五种数据结构 一.全局key操作 --删 flushdb --清空当前选择的数据库 del mykey mykey2 --删除了两个 Keys --改 --将当前数据库中的 mysetkey 键移入到 ...
- redis的入门篇---五种数据类型及基本操作
查看所有的key keys * 清空所有的key flushall 检查key是否存在 exists key 设置已存在的key的时长 expire key //设置key为10s 查看key还剩多少 ...
- 矩池云安装gdal五种解决方案
1.最快最靠谱的是conda conda install gdal 命令行conda/pip search gdal查看版本,选择合适的版本,例如:conda search gdal 命令行conda ...
- Redis五种数据结构简介
Redis五种结构 1.String 可以是字符串,整数或者浮点数,对整个字符串或者字符串中的一部分执行操作,对整个整数或者浮点执行自增(increment)或者自减(decrement)操作. 字符 ...
- 第2节 storm实时看板案例:10、redis的安装使用回顾
2.redis的持久化机制: redis支持两种持久化机制:RDB AOF RDB:多少秒之内,有多少个key放生变化,将redis当中的数据dump到磁盘保存,保存成一个文件,下次再恢复的时候,首 ...
- Jedis操作笔记 redis的五种存储类型
常用数据类型简介: redis常用五种数据类型:string,hash,list,set,zset(sorted set). 1.String类型 String是最简单的类型,一个key对应一个val ...
- redis五种数据类型的使用(zz)
redis五种数据类型的使用 redis五种数据类型的使用 (摘自:http://tech.it168.com/a2011/0818/1234/000001234478_all.shtml ) 1.S ...
随机推荐
- C++中的Inline函数的使用
转载自:https://www.cnblogs.com/KellyHuang/p/4001470.html 在大多数机器上,函数调用does a lot of work:在调用函数前保存寄存器,调用结 ...
- 如何使用React搭建项目
1.首先说明node.js.npm.cnpm分别是做什么的? node.js简单的说 Node.js 就是运行在服务端的 JavaScript,安装了node.js默认安装了npm,可以使用npm - ...
- 手把手告诉你如何安装多个版本的node,妈妈再也不用担心版本高低引发的一系列后遗症(非常详细,非常实用)
简介 最近好多人都问到node怎么同时安装多个版本? 如何配置node的环境变量,如何自如的在多个版本中切换node?还有就是自己在做appium自动化的时候,有时候会因为node的版本过高或者是太低 ...
- Java 字符串常量存放在堆内存还是JAVA方法区?
JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池. JDK1.8开始,取消了Java方法区,取而代之的是位于直接内 ...
- 更换SVN项目资源库目录出现的问题
今天在做SVN资源库管理时出现了如下问题: 因为当时把资源库地址写错了,所以想换个资源库,所以先断开资源库 然后我重新导入新的资源库位置: 于是就出现了这种问题: 其实这个问题困扰我好久了之前一直放过 ...
- android 百度地图入门01 (史上最详没有之一)
最近一直和百度地图打交道,写几篇博客记录一下吧,目前最新版是4.0的 ,之前我用的是3.7的, 就以4.0的为例说一下最基本的配置流程吧. 一.准备工作 1.申请一个百度地图开发者账户--地址:htt ...
- apache ignite系列(一): 简介
apache-ignite简介(一) 1,简介 ignite是分布式内存网格的一种实现,其基于java平台,具有可持久化,分布式事务,分布式计算等特点,此外还支持丰富的键值存储以及SQL语法(基于 ...
- CoDeSys
CoDeSys是全球最著名的PLC内核软件研发厂家德国的3S(SMART,SOFTWARE,SOLUTIONS)公司出的一款与制造商无关的IEC 61131-1编程软件.CoDeSys 支持完整版本的 ...
- 字符串之————三向字符串快速排序(Quick3string)
上一篇介绍了字符串的两种经典排序方法(LSD MSD): https://www.cnblogs.com/Unicron/p/11531111.html 下面我们来介绍一种通用的字符串排序方法——三向 ...
- 【全网首创】修改 Ext.ux.UploadDialog.Dialog 源码支持多选添加文件,批量上传文件
公司老框架的一个页面需要用到文件上传,本以为修改一个配置参数即可解决,百度一番发现都在说这个第三方插件不支持文件多选功能,还有各种各样缺点,暂且不讨论这些吧.先完成领导安排下来的任务. 任务一:支持多 ...