jieba分词原理-DAG(NO HMM)
最近公司在做一个推荐系统,让我给论坛上的帖子找关键字,当时给我说让我用jieba分词,我周末回去看了看,感觉不错,还学习了一下具体的原理
首先,通过正则表达式,将文章内容切分,形成一个句子数组,这个比较好理解
然后构造出句子的有向无环图(DAG)
def get_DAG(self, sentence):
self.check_initialized()
DAG = {}
N = len(sentence)
for k in xrange(N):
tmplist = []
i = k
frag = sentence[k]
while i < N and frag in self.FREQ:#对每一个字从这个字开始搜索成词位置
if self.FREQ[frag]:
tmplist.append(i)#如果可以成词就加入到DAG中
i += 1
frag = sentence[k:i + 1]
if not tmplist:
tmplist.append(k)#如果找不到词语,就将自己加入DAG
DAG[k] = tmplist
return DAG
- 对句子中的每个字进行分析,从右边一位开始,看sentence[k:i+1]这个词语是否在预设的字典中,这个字典保存了常用的词语(和词语的一部分,但权重为0)和其权重.如果有,并且如果字典中的这个词的权值不等于0,那么就将i放到tmplist里,然后i+=1,继续下一轮循环,如果没有这个词,那就停下来,然后移动k,让k=k+1,找下一个字的成词位置
- 比如有这样一个句子:'我从海淀区搬到了朝阳区',一共11个字
- 通过上面的计算,得到一个字典:<class 'dict'>: {0: [0], 1: [1], 2: [2, 3, 4], 3: [3, 4], 4: [4], 5: [5, 6], 6: [6], 7: [7], 8: [8, 9, 10], 9: [9], 10: [10]},字典键代表每个字在字符串中的位置,比如,0代表'我',1代表'从',而每个键对应一个数组,比如2对应[2,3,4],这个表示:'海'(2)/'海淀'(2-3)/'海淀区'(2-4),这三个字符串可以成为词语
- 这样,我们就得到了所有可以成词的位置了
选出成词概率最大的位置
def calc(self, sentence, DAG, route):
N = len(sentence)
route[N] = (0, 0)
logtotal = log(self.total)#常数值
for idx in xrange(N - 1, -1, -1):#从后往前分析
route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) -
logtotal + route[x + 1][0], x) for x in DAG[idx])
- 对于句子中的每一个字,计算候选位置中,哪个成词概率最大
- 比如2:[2,3,4],分别对2/3/4进行计算,计算公式:log(词的概率)-常数+下一个字的成词概率
- 词语的概率还是用之前保存了所有常用词的字典(也可以自己定义字典),下一个字的成词概率是上一个循环计算出来的,我们要从末尾开始计算,得到的结果作为下一个循环的参数,这样我们就找到了最大成词概率的切分位置
- 为什么要加上下一个字的成词概率的呢?因为下一个词的成词概率高的话,我们做出的切分就越正确,越有可能切成两个正确的词语,而不是左边的词语概率高,而右边根本不是一个正确的词语
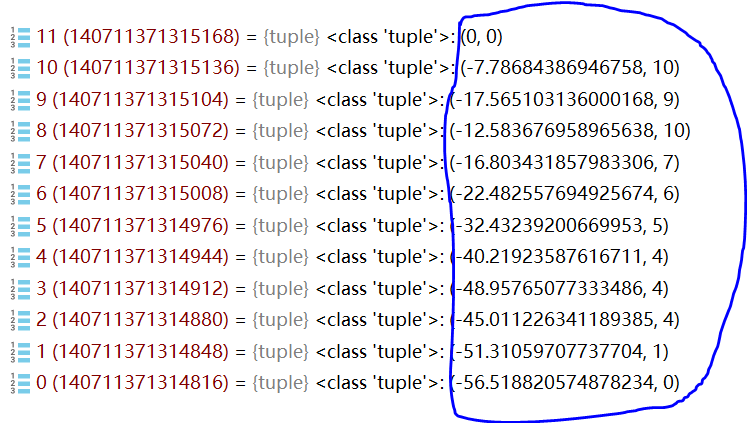
如上图,蓝色圈中的部分,括号右边代表了成词的位置,比如2,括号的右边是4,说明2-4这个词的成词概率高,我们就切成'海淀区'
切分的过程是这样的
- 从头开始,寻找每个位置对应的成词位置,取出来
- 跳到成词位置的下一个位置开始循环
这样,我们就能得到:0/1/2-4/5/6/7/8-10
具体为:我/从/海淀区/搬/到/了/朝阳区
到此为止整个过程就结束了
不过,官方默认算法还有个hmm,这次先不说了,请听下回分解
jieba分词原理-DAG(NO HMM)的更多相关文章
- Jieba分词原理与解析
https://www.jianshu.com/p/dfdfeaa7d01f 1 HMM模型 image.png 马尔科夫过程: image.png image.png 以天气判断为例:引 ...
- jieba分词原理解析:用户词典如何优先于系统词典
目标 查看jieba分词组件源码,分析源码各个模块的功能,找到分词模块,实现能自定义分词字典,且优先级大于系统自带的字典等级,以医疗词语邻域词语为例. jieba分词地址:github地址:https ...
- 自然语言处理课程(二):Jieba分词的原理及实例操作
上节课,我们学习了自然语言处理课程(一):自然语言处理在网文改编市场的应用,了解了相关的基础理论.接下来,我们将要了解一些具体的.可操作的技术方法. 作为小说爱好者的你,是否有设想过通过一些计算机工具 ...
- python环境jieba分词的安装
我的python环境是Anaconda3安装的,由于项目需要用到分词,使用jieba分词库,在此总结一下安装方法. 安装说明======= 代码对 Python 2/3 均兼容 * 全自动安装:`ea ...
- python结巴(jieba)分词
python结巴(jieba)分词 一.特点 1.支持三种分词模式: (1)精确模式:试图将句子最精确的切开,适合文本分析. (2)全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解 ...
- 自然语言处理之jieba分词
在处理英文文本时,由于英文文本天生自带分词效果,可以直接通过词之间的空格来分词(但是有些人名.地名等需要考虑作为一个整体,比如New York).而对于中文还有其他类似形式的语言,我们需要根据来特殊处 ...
- 自然语言处理之中文分词器-jieba分词器详解及python实战
(转https://blog.csdn.net/gzmfxy/article/details/78994396) 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自 ...
- python jieba分词工具
源码地址:https://github.com/fxsjy/jieba 演示地址:http://jiebademo.ap01.aws.af.cm/ 特点 1,支持三种分词模式: a,精确模式,试图将句 ...
- python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库 -转载
转载请注明出处 “结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库. jieba的分词,提取关 ...
随机推荐
- 关于OC中直接打印结构体(CGRectCGSize、CGPoint、UIOffset)等数据类型
关于OC直接打印结构体,点(CGRect,CGSize,CGPoint,UIOffset)等数据类型,我们完全可以把其转换为OC对象来进项打印调试,而不必对结构体中的成员变量进行打印.就好比我们可以使 ...
- spark 在yarn模式下提交作业
1.spark在yarn模式下提交作业需要启动hdfs集群和yarn,具体操作参照:hadoop 完全分布式集群搭建 2.spark需要配置yarn和hadoop的参数目录 将spark/conf/目 ...
- [20190530]ORACLE 18c - ALTER SEQUENCE RESTART.txt
[20190530]ORACLE 18c - ALTER SEQUENCE RESTART.txt --//以前遇到要重置或者调整seq比较麻烦,我有时候采用比较粗暴的方式就是删除重建.--//18c ...
- react中界面跳转 A界面跳B界面,返回A界面,A界面状态保持不变 redux的state方法
在上一篇文章中说过了react中界面A跳到B,返回A,A界面状态保持不变,上篇中使用的是传统的localStorage方法,现在来使用第二种redux的state方法来实现这个功能 现在我刚接触red ...
- c# 第39节 抽象类、抽象方法
本节内容: 1:抽象类的说明 2:抽象类的实例 1:抽象类的说明 抽象类定义:方法前有abstract就称为抽象类.抽象方法,抽象方法不提供任何实际实现. 注意点1: 抽象方法必须在抽象类中声明: 不 ...
- [C1W3] Neural Networks and Deep Learning - Shallow neural networks
第三周:浅层神经网络(Shallow neural networks) 神经网络概述(Neural Network Overview) 本周你将学习如何实现一个神经网络.在我们深入学习具体技术之前,我 ...
- Mybatis全局配置文件详解(三)
每个基于Mybatis应用都是以一个SqlSessionFactory实例为中心.SqlSessionFactory实例可以由SqlSessionFactoryBuild获得,而SqlSessionF ...
- 期望DP的一般思路
期望DP的一般思路 转载自_new2zy_ 期望\(dp\),也加概率\(dp\) 一般来说,期望\(dp\)找到正确的状态后,转移是比较容易想到的. 但一般情况下,状态一定是"可数&quo ...
- JDOJ3011 铺地板III
JDOJ3011 铺地板III https://neooj.com/oldoj/problem.php?id=3011 题目描述 有3 x N (0 <= N <= 105)的网格,需要用 ...
- Spring Cloud Alibaba Sentinel对Feign的支持
Spring Cloud Alibaba Sentinel 除了对 RestTemplate 做了支持,同样对于 Feign 也做了支持,如果我们要从 Hystrix 切换到 Sentinel 是非常 ...