spark 在yarn模式下提交作业
1、spark在yarn模式下提交作业需要启动hdfs集群和yarn,具体操作参照:hadoop 完全分布式集群搭建
2、spark需要配置yarn和hadoop的参数目录
将spark/conf/目录下的spark-env.sh.template文件复制一份,加入配置:
YARN_CONF_DIR=/opt/hadoop/hadoop-2.8.3/etc/hadoop
HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.8.3/etc/hadoop
3、将spark整个目录分发到hdfs集群中每台机器上,分发命令可以参考:linux rsync
如果不想用rsync也可以直接用scp -r拷贝,测试环境下差别不大。
4、提交作业测试
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.4.4.jar 200
正常情况下很快就能计算完成:

在yarn的UI可以监控到执行的作业:
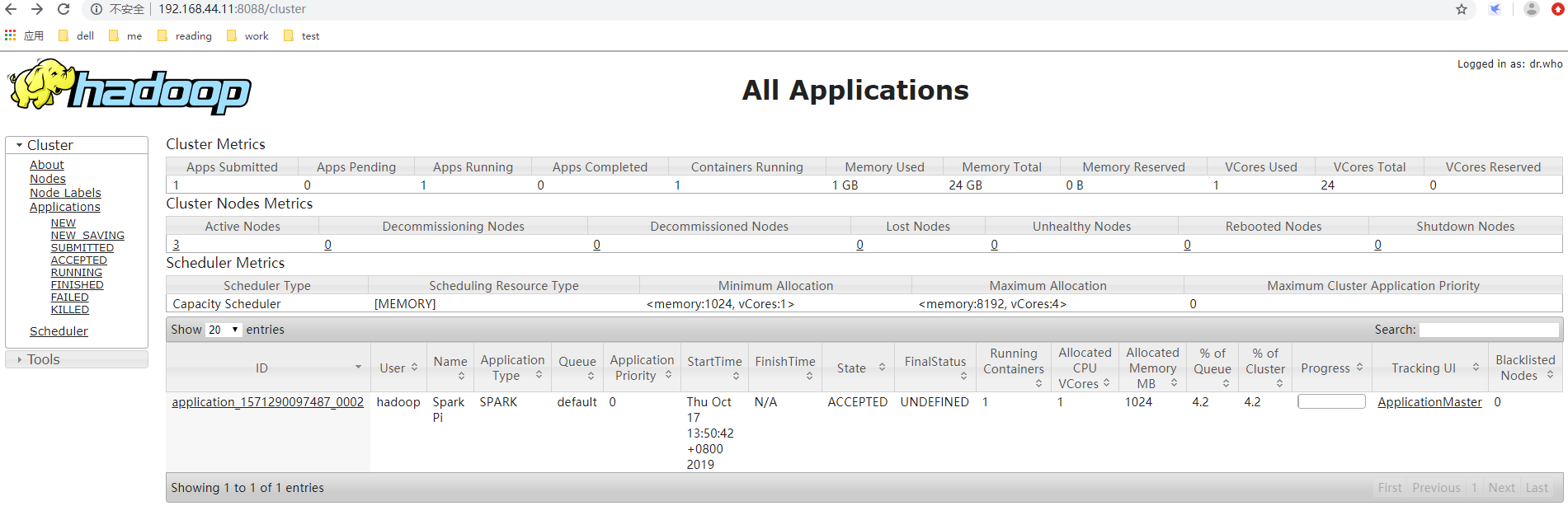
5、spark参数优先级
Spark加载属性参数的优先顺序是:
(1)直接在SparkConf设置的属性参数
(2)通过 spark-submit 或 spark-shell 方式传递的属性参数
(3)最后加载 spark-defaults.conf 配置文件的属性参数
如果在程序里指定了SparkConf的参数,则spark缺省参数以及命令行参数都将失效,如果想灵活一下,我们可以在SparkConf加载缺省配置(spark-defaults.conf),然后在命令方式下覆盖参数。
val conf: SparkConf = new SparkConf(true).setAppName("SparkWordCount")
master这个参数就可以指定local或者yarn等模式,但是name参数在命令指定是无效的,因为已经内置了。
bin/spark-submit --master yarn --name myWordCount --class com.home.spark.WordCount --executor-memory 512M ~/sparkWordCount.jar hdfs://vmhome10.com:9000/input
spark 在yarn模式下提交作业的更多相关文章
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- spark on yarn模式下内存资源管理(笔记1)
问题:1. spark中yarn集群资源管理器,container资源容器与集群各节点node,spark应用(application),spark作业(job),阶段(stage),任务(task) ...
- spark on yarn模式下内存资源管理(笔记2)
1.spark 2.2内存占用计算公式 https://blog.csdn.net/lingbo229/article/details/80914283 2.spark on yarn内存分配** 本 ...
- Spark在StandAlone模式下提交任务,spark.rpc.message.maxSize太小而出错
1.错误信息org.apache.spark.SparkException: Job aborted due to stage failure:Serialized task 32:5 was 172 ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- flink on yarn模式下两种提交job方式
yarn集群搭建,参见hadoop 完全分布式集群搭建 通过yarn进行资源管理,flink的任务直接提交到hadoop集群 1.hadoop集群启动,yarn需要运行起来.确保配置HADOOP_HO ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- spark on yarn模式里需要有时手工释放linux内存
为什么要提出这个问题? spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED) 然后执行 [spark@master spark--bin- ...
随机推荐
- Locust压测结果准确性验证
最近闲着没事做,就重新研究了一下基于python语言的Locust性能测试框架 发现在压测的过程中,虽然设置了100并发,但是通过实际监控,完全看不到100并发压测的效果 通过代码AOP日志监控接口的 ...
- ENDIAN的由来及BIG-EDIAN 和LITTLE-ENDIAN(转)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/kingmax54212008/arti ...
- Burpsuite抓取https数据包
Burpsuite抓取https包 浏览器代理设置 Burpsuite代理设置 启动Burpsuite,浏览器访问127.0.0.1:8080,点击CA Certificate,下载cacert.de ...
- GitHub最强技术面试手册:Tech Interview Handbook
摘要: 求职还是需要认真准备的. 原文:超实用技术面试手册,从工作申请.面试考题再到优势谈判,GitHub获30000星 作者:量子位 技术人员求职面试,单刷leetcode上的大厂题库可能还不够. ...
- 3-SQL过滤
# 筛选最大生命值大于6000,最大法力值大1700的英雄,然后按照二者之和从高到低进行排序 SELECT NAME , hp_max, mp_max FROM he ...
- linux 性能调优工具参考 (linux performance tools)
之前发现几张图对于linux使用者有着较强的参考意义,下面对其进行简单备忘: # linux 静态信息查看工具 # linux 性能测试工具 benchmark # linux 性能观测工具 # li ...
- Java总结转载,持续更新。。。
1.Java中内存划分 https://www.cnblogs.com/yanglongbo/p/10981680.html
- class与class的继承
class Point{ constructor(x,y){ this.x = x; this.y = y; } toString(){ return '(' + this.x + ',' + thi ...
- layUI学习第二日:非模块化方法使用layUI
layUI采用非模块化方式(即所有模块一次性加载),操作示例代码如下(如果问怎么创建项目和工具,参考layUI学习第一日的步骤): 运行的结果如下: 运行的显示不会太持久,过几秒就会消失,具体封装的代 ...
- php精确计算
php BC高精确度函数库 结果: php一般的取余 只是除以整数 bc精度取余 精确到了小数