Java入门系列之集合LinkedList源码分析(九)
前言
上一节我们手写实现了单链表和双链表,本节我们来看看源码是如何实现的并且对比手动实现有哪些可优化的地方。
LinkedList源码分析
通过上一节我们对双链表原理的讲解,同时我们对照如下图也可知道双链表算法实现有如下特点。
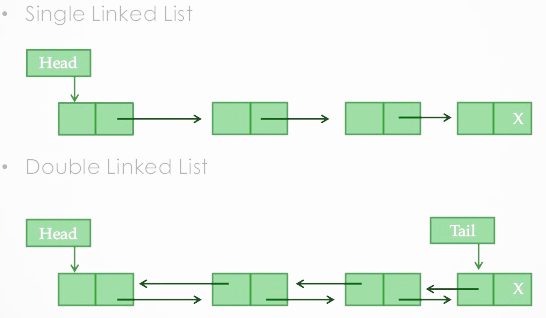
1、链表中的每个链接都是一个对象(也称为元素,节点等)。
2、每个对象都包含一个引用(地址)到下一个对象的位置。
3、链表中前驱节点指向null表示链表的头,链表中的后继节点指向null,表示链表的尾。
4、链接列表可以在运行时(程序运行时,编译后)动态增长和缩小,仅受可用物理内存的限制。
我们首先看看LinkedList给我们提供了哪些可操作的方法,如下:
LinkedList<String> list = new LinkedList();
//添加元素到尾结点
list.add("str");
//添加元素到指定索引节点
list.add(1,"str");
//添加元素到头节点
list.addFirst("first");
//添加元素到尾节点
list.addLast("last");
//返回指定索引元素
list.get(1);
//返回头节点元素
list.getFirst();
//返回尾节点元素
list.getLast();
//添加元素到尾结点
list.offer("str");
//添加元素到头节点
list.offerFirst("str");
//添加元素到尾节点
list.offerLast("str");
首先我们来看看LinkedList中定义了哪些变量。首先对节点元素的操作在该类中定义了节点内部类,因为其他地方用不到该节点类,这点和我们上一节所定义的节点类没有什么差异。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
接下来我们再来看看对链表的定义,如下:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{ //链表长度
transient int size = 0; //链表头节点
transient Node<E> first; //链表尾节点
transient Node<E> last; //构造函数
public LinkedList() {
} //构造函数传入集合进行转换
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
}
上述我们所定义的双链表类继承了对应的类,实现了对应的接口,我们通过一张图来进行归纳,如下:
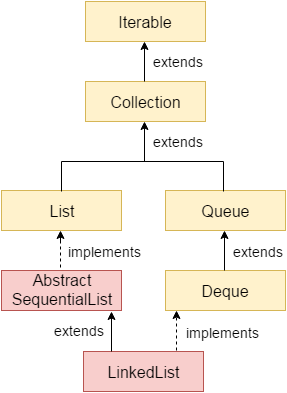
紧接着通过如上一张图以及上一节我们对双链表的基本原理讲解,我们首先给出源码中双链表特点,如下:
1、可以用作队列,双端队列或栈。因为已实现了List可作为队列,同时也实现了Queue和Deque接口可作为双端队列或栈。
2、允许所有元素且可包含重复和NULL。
3、LinkedList维护元素的插入顺序。
4、非线程安全。 如果多个线程同时访问链表,并且若有一个线程在结构上修改了列表,则必须在外部进行同步,使用Collections.synchronizedList(new LinkedList())获取同步的链表。
5、迭代器支持快速失败(Fail-Fast),可能会抛出ConcurrentModificationException。
6、未实现RandomAccess接口。所以它不支持随机访问元素,我们只能按顺序访问元素。
由于上一节我们实现了其基本原理,而在java中实现双链表只不过是给我们提供了更多可操作的方法,比如在头结点、尾节点插入元素是一样的,这里我们就不一一贴出源码了,针对在指定索引插入元素这点比我们处理的好,上一节我们对指定索引插入元素采取循环遍历的方式,同时我们只用到了后继节点,而在java中,它是如何处理的呢,我们下面来分析其源码:
//指定索引插入元素
public void add(int index, E element) {
//检查插入索引位置是否超过边界,否则抛出异常
checkPositionIndex(index); //如果插入索引和链表长度相等则插入尾节点
if (index == size)
linkLast(element);
else
//否则在指定索引插入元素
linkBefore(element, node(index));
}
接下来我们继续看看若不是插入尾节点,那么插入指定索引位置,它是如何处理的呢?
//在节点succ后插入元素e
void linkBefore(E e, Node<E> succ) {
//定义succ节点的前驱节点
final Node<E> pred = succ.prev;
//实例化要插入元素的节点
final Node<E> newNode = new Node<>(pred, e, succ);
//插入元素的前驱节点即为succ
succ.prev = newNode;
if (pred == null)
//如果succ的前驱为null,说明为头节点则插入元素的节点为头节点
first = newNode;
else
//否则待插入指定索引的节点的后继节点为插入元素的节点
pred.next = newNode;
size++;
modCount++;
} //获取指定索引的节点
Node<E> node(int index) { //若索引位置小于链表长度的一半,则从头节点指向后继节点循环查找索引元素
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//否则从尾节点指向前驱节点循环查找索引元素
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
由上看出我们上一节手动指定索引插入元素,在java中处理的更为巧妙且性能更好,因为通过指定索引和链表的长度的二分之一作为判断依据能更快查找到指定索引节点。通过查看源码我们会发现add对应offer方法都是插入到尾节点,而addFirst对应offerFirst都是插入到头节点,addLast对应offerLast都是插入到尾节点。详细区别请参考园友文章,这里我就不列举了。https://www.cnblogs.com/skywang12345/p/3308807.html。只要我们了解了算法基本原理,再去看看源码其实很简单,只不过是对照着看看是否有更好的实现方式而已,关于源码分析我们就到此为止。这里我们需要强调下双链表的特点有一个是快速失败机制及Fail-Fast,这里我们通过例子来说明。
Fail-Fast VS Fail-Safe
快速迭代失败 - 当我们尝试在迭代时修改集合的内部结构时,它会抛出ConcurrentModificationException,是失败的快速迭代器。让我们来看如下例子
LinkedList<String> listObject = new LinkedList<>();
listObject.add("ram");
listObject.add("mohan");
listObject.add("shyam");
listObject.add("mohan");
listObject.add("ram");
Iterator it = listObject.iterator();
while (it.hasNext()) {
listObject.add("raju");
System.out.println(it.next());
}

在进一步讨论之前,我们分析为什么会出现此异常,我们注意到从next()方法开始的异常堆栈问题。 在next()方法中,还有另一个方法checkForComodification(),它根据某些条件抛出了ConcurrentModificationException异常,接下来 让我们看看next()和checkForComodification()方法中发生了什么。
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
在checkForComodification()方法内部,如果modcount不等于expectedModCount则抛出ConcurrentModificationException(扩展RuntimException)。根据上述情况,当我们在循环中执行listObject.add(“raju”)时,modCount的值变为6但是expectedCount的值仍然是5,这就是我们得到ConcurrentModificationException的原因。所以看来我们迭代时在next()方法中遇到了问题,显然这种处理方式毫无疑问是正确的, 如果我们不使用next方法打印元素,我们使用增强的for循环试试。
LinkedList<String> listObject = new LinkedList<>();
listObject.add("ram");
listObject.add("mohan");
listObject.add("shyam");
listObject.add("mohan");
listObject.add("ram");
for (String s : listObject ){
listObject.add("raju");
System.out.println(s);
}

通过使用增强的for循环我们仍然得到ConcurrentModificationException异常,这是为什么呢?我们没有使用Iterator进行迭代啊,通过如上堆栈信息我们知道,即使我们使用增强的for循环,内部的next()方法也会被调用。在JDK1.5中,一些新类(CopyOnWriteArrayList,CopyOnWriteArraySet,ConcurrentHashMap等)不会抛出ConcurrentModificationException,即使我们在迭代时修改List,Set或Map的结构。 这些类用于克隆或复制集合Object。
List<String> listObject = new CopyOnWriteArrayList<>();
listObject.add("ram");
listObject.add("mohan");
listObject.add("shyam");
listObject.add("mohan");
listObject.add("ram");
Iterator it = listObject.iterator();
while (it.hasNext()) {
listObject.add("raju");
System.out.println(it.next());
}

接下来我们总结出Fail-Fast和Fail Safe的区别所在,如下:
| 序号 | Fail Fast | Fail Safe |
|---|---|---|
| 1. | Fail fast应用于集合对象 | 应用于克隆或集合对象的副本。 |
| 2. | 当迭代时,我们对集合元素进行修改时将抛出ConcurrentModificationException异常 | 不会抛出任何异常 |
| 3. | 需要更少的内存 | 需要额外的内存 |
| 4. | ArrayList,HashSet, HashMap等等被使用时 | CopyOnWriteArrayList,ConcurrentHashMap等等类被使用时 |
数组与LinkedList相互转换
我们来看看在java中是如何将数组转换为LinkedList或将Linkedlist如何转换为数组的呢。
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("A");
linkedList.add("B");
linkedList.add("C");
linkedList.add("D");
//1. LinkedList to Array
String array[] = new String[linkedList.size()];
linkedList.toArray(array);
System.out.println(Arrays.toString(array));
//2. Array to LinkedList
LinkedList<String> linkedListNew = new LinkedList<>(Arrays.asList(array));
System.out.println(linkedListNew);

LinkedList排序
我们可以使用Collections.sort()方法对链接列表进行排序,若是对于对象的自定义排序,我们可以使用Collections.sort(链接的List,比较器)方法。如下:
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("A");
linkedList.add("C");
linkedList.add("B");
linkedList.add("D");
//Unsorted
System.out.println(linkedList);
//1. Sort the list
Collections.sort(linkedList);
//Sorted
System.out.println(linkedList);
//2. Custom sorting
Collections.sort(linkedList, Collections.reverseOrder());
linkedList.sort(Collections.reverseOrder());
//Custom sorted
System.out.println(linkedList);

LinkedList VS ArrayList
在Java LinkedList类中,操作很快,因为不需要发生转换,基本上,所有添加和删除方法都提供了非常好的性能O(1)。LinkedList常用方法时间复杂度总结如下:
- add(E element) :O(1).
- get(int index) 和add(int index, E element) : O(N).
- remove(int index) :O(N).
- Iterator.remove() : O(1).
- ListIterator.add(E element) : O(1).
前面我们也详细分析了ArrayList源码,如下我们详细分析比较下LinkedList和ArraryList,如下:
1、ArrayList使用动态扩容来调整数组大小。而LinkedList使用双向链表实现。
2、ArrayList允许随机访问它的元素,而LinkedList则不允许,只能按顺序访问链表中的节点,因此访问特定节点会很慢。
3、LinkedList也实现了Queue接口,它添加了比ArrayList更多的方法,例如offer,peek,poll等。
4、与LinkedList相比,ArrayList在添加和删除方面较慢,但在get中更快,因为如果在LinkedList中数组已满,则无需调整数组大小并将内容复制到新数组。
5、LinkedList比ArrayList具有更多的内存开销,因为在ArrayList中,每个索引仅保存实际对象,但在LinkedList的情况下,每个节点都保存后继节点和前驱节点的数据和地址。
综上所述LinkedList貌似毫无用武之地,那么我们究竟什么时候可以用LinkedList呢?我认为可从以下三方面考虑
1、不需要随机访问任何特定元素。
2、需要频繁进行插入和删除。
3、不确定链表中有多少项。
总结
本节我们稍微分析了下LinkedList源码,然后对比了ArrayList和LinkedList优缺点,以及我们应当什么时候用LinkedList,除开极少数情况,大部分情况下都不太会用到LinkedList,好了本节我们到这里为止,下一节我们进入Hashtable的学习。感谢您的阅读,下节见。
Java入门系列之集合LinkedList源码分析(九)的更多相关文章
- Java入门系列之集合ArrayList源码分析(七)
前言 上一节我们通过排队类实现了类似ArrayList基本功能,当然还有很多欠缺考虑,只是为了我们学习集合而准备来着,本节我们来看看ArrayList源码中对于常用操作方法是如何进行的,请往下看. A ...
- Java入门系列之集合HashMap源码分析(十四)
前言 我们知道在Java 8中对于HashMap引入了红黑树从而提高操作性能,由于在上一节我们已经通过图解方式分析了红黑树原理,所以在接下来我们将更多精力投入到解析原理而不是算法本身,HashMap在 ...
- Java入门系列之集合Hashtable源码分析(十一)
前言 上一节我们实现了散列算法并对冲突解决我们使用了开放地址法和链地址法两种方式,本节我们来详细分析源码,看看源码中对于冲突是使用的哪一种方式以及对比我们所实现的,有哪些可以进行改造的地方. Hash ...
- Java -- 基于JDK1.8的LinkedList源码分析
1,上周末我们一起分析了ArrayList的源码并进行了一些总结,因为最近在看Collection这一块的东西,下面的图也是大致的总结了Collection里面重要的接口和类,如果没有意外的话后面基本 ...
- Java集合-LinkedList源码分析
目录 1.数据结构-链表 2.ArrayList结构特性 3.构造方法 4.成员变量 5.常用的成员方法 6.Node节点 7.序列化原理 8.迭代器 9.总结 1.数据结构-链表 链表(Linked ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- Java集合之LinkedList源码分析
概述 LinkedLIst和ArrayLIst一样, 都实现了List接口, 但其内部的数据结构不同, LinkedList是基于链表实现的(从名字也能看出来), 随机访问效率要比ArrayList差 ...
- ArrayList 和 LinkedList 源码分析
List 表示的就是线性表,是具有相同特性的数据元素的有限序列.它主要有两种存储结构,顺序存储和链式存储,分别对应着 ArrayList 和 LinkedList 的实现,接下来以 jdk7 代码为例 ...
- 一步步实现windows版ijkplayer系列文章之六——SDL2源码分析之OpenGL ES在windows上的渲染过程
一步步实现windows版ijkplayer系列文章之一--Windows10平台编译ffmpeg 4.0.2,生成ffplay 一步步实现windows版ijkplayer系列文章之二--Ijkpl ...
随机推荐
- 抓包工具Charles的使用说明
Charles介绍&前期准备: Charles介绍:Charles跟fiddler是目前行业中比较常用的抓包工具,这里主要介绍Charles的使用,fiddler的使用类似. 前期准备:使用前 ...
- 基于TCP协议之socket编程
#服务端 #导入一个socket模块 import socket #想象成买手机打电话:socket.SOCK_STREAM 表示建立tcp连接 ,udp连接socket.SOCK_DGRAM #买了 ...
- java基础-数据类型之殇
一 前言 Java的数据类型分为2种,分别是基本数据类型和引用数据类型:java的数据类型是强数据类型,意味着每声明一个变量,其必定有与之对应的数据类型:面试常问的java8大基本数据类型其实是基本数 ...
- 在 .NET Core 中使用 Diagnostics (Diagnostic Source) 记录跟踪信息
前言 最新一直在忙着项目上的事情,很久没有写博客了,在这里对关注我的粉丝们说声抱歉,后面我可能更多的分享我们在微服务落地的过程中的一些经验.那么今天给大家讲一下在 .NET Core 2 中引入的全新 ...
- Blazor(WebAssembly) + .NETCore 实现斗地主
之前群里大神发了一个 html5+ .NETCore的斗地主,刚好在看Blazor WebAssembly 就尝试重写试试. 还有就是有些标题党了,因为文章里几乎没有斗地主的相关实现:),这里主要介绍 ...
- 可以设置实体在Dynamics 365高级查找中不显示吗?
我是微软Dynamics 365 & Power Platform方面的工程师罗勇,也是2015年7月到2018年6月连续三年Dynamics CRM/Business Solutions方面 ...
- 仿Inshot分享页图片圆形展开缩放动画
版权声明:本文为xing_star原创文章,转载请注明出处! 本文同步自http://javaexception.com/archives/221 圆形展开缩放动画 关键代码: final Anima ...
- MySQL基础-存储过程
存储过程 定义:将一批为了完成特定功能的SQL语句集,根据传入的参数(也可没有),调用,完成单个sql语句更复杂的功能 存储过程思想很简单,就是SQL语句层面上的代码封装和重用 优点:1) 可封装,并 ...
- Sqlite—Python接口
#!/usr/bin/env python # -*- coding:utf-8 -*- import sqlite3,os,time import traceback class Sqlite(): ...
- Spring Boot Web开发与thymeleaf模板引擎
简介: 使用Springboot应用,选中需要的模块, Spring已经默认将场景配置好了,只需在配置文件中少量配置就可以运行起来 自己编写业务代码 自动配置原理 这个场景Springboot帮我们配 ...