pytorch笔记
Tensor create
#创建特定shape value为random值的tensor
input = torch.rand((64,64,3))
Tensor slice
- 以[2,3]矩阵为例,slice后可以得到任意shape的矩阵,并不是说一定会小于2行3列.
import torch
truths=torch.Tensor([[1,2,3],[4,5,6]])
#代表新生成一个[3,]的矩阵,行位置分别取原先矩阵的第1,第0,第1行.
print(truths[[1,0,1],:])
print(truths[[1,0,1]]) #等同于truths[[1,0,1],:]
#代表新生成一个[,4]的矩阵,列位置分别取原先矩阵的第2,第2,第2,第2列
print(truths[:,[2,2,2,2]])
输出

- 用bool型的tensor去切片
import torch
x = torch.tensor([[1,2,3],[4,5,6]])
index = x>2
print(index.type())
x[index]

tensor扩展

Expanding a tensor does not allocate new memory, but only creates a new view on the existing tensor where a dimension of size one is expanded to a larger size by setting the stride to 0. Any dimension of size 1 can be expanded to an arbitrary value without allocating new memory.
并不分配新内存. 只是改变了已有tensor的view. size为1的维度被扩展为更大的size.
>>> x = torch.tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
>>> x.expand(-1, 4) # -1 means not changing the size of that dimension
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
gather
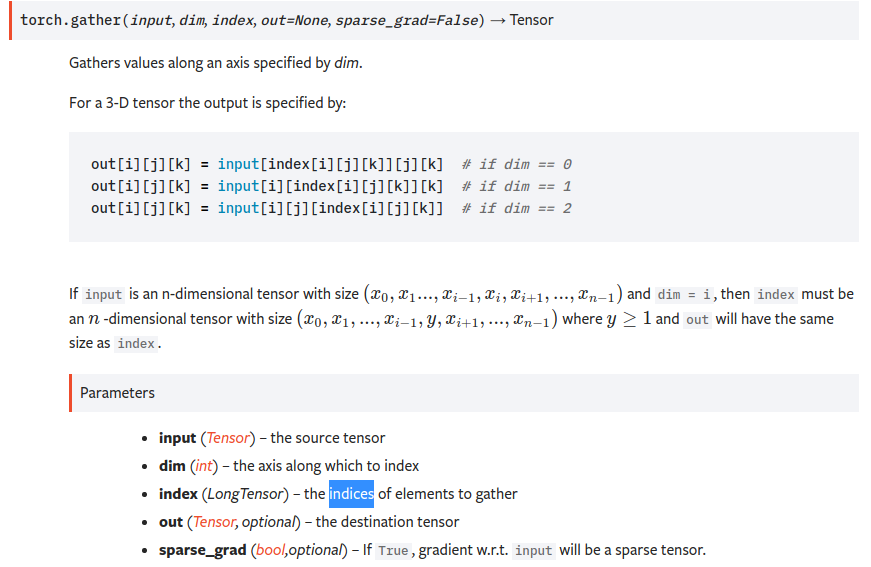
torch.gather(input, dim, index, out=None, sparse_grad=False) → Tensor
即dim维度的下标由index替换.input是n维的,index也得是n维的,tensor在第dim维度上的size可以和input不一致. 最终的output和index的shape是一致的.
即对dim维度的数据按照index来索引.
比如
import torch
t = torch.tensor([[1,2],[3,4]])
index=torch.tensor([[0,0],[1,0]])
torch.gather(t,1,index)
输出
tensor([[1, 1],
[4, 3]])
gather(t,1,index)替换第1维度的数据(即列方向),替换成哪些列的值呢?[[0,0],[1,0]],对第一行,分别为第0列,第0列,对第二行,分别为第1列,第0列.
从而得到tensor([[1, 1],[4, 3]])
sum

沿着第n维度,求和.keepdim表示是否保持维度数目不变.
import torch
t = torch.tensor([[1,2],[3,4]])
a=torch.sum(t,0)
b=torch.sum(t,1,keepdim=True)
print(a.shape,b.shape)
print(a)
print(b)

sort
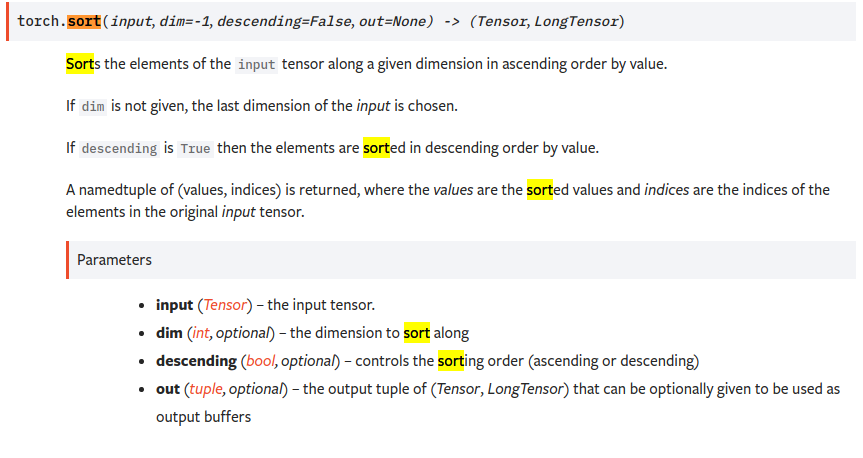
沿着第n个维度的方向排序
import torch
t = torch.tensor([[1,9,7],[8,5,6]])
_sorted,_index = t.sort(1)
print(_sorted)
print(_index)
_sorted,_index = t.sort(0)
print(_sorted)
print(_index)

clamp
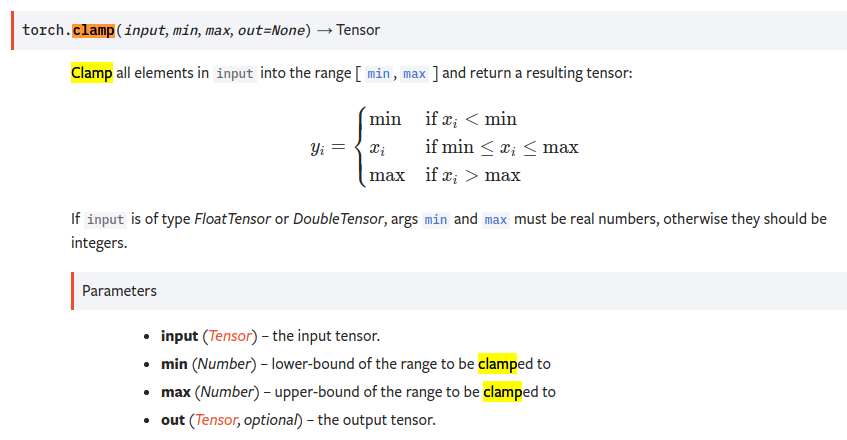
import torch
print()
t = torch.tensor([[1,2,7],[3,4,8]])
res = t.clamp(3,7) #<3的变为3,>7的变为7 中间范围的不变
print(res)
res2 = torch.clamp(t,max=5) #所有大于5的都改为5
print(res2)

各种损失函数
https://blog.csdn.net/zhangxb35/article/details/72464152
有用link:
pytorch笔记的更多相关文章
- [Pytorch] pytorch笔记 <三>
pytorch笔记 optimizer.zero_grad() 将梯度变为0,用于每个batch最开始,因为梯度在不同batch之间不是累加的,所以必须在每个batch开始的时候初始化累计梯度,重置为 ...
- [Pytorch] pytorch笔记 <二>
pytorch笔记2 用到的关于plt的总结 plt.scatter scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, ...
- [Pytorch] pytorch笔记 <一>
pytorch笔记 - torchvision.utils.make_grid torchvision.utils.make_grid torchvision.utils.make_grid(tens ...
- 【转载】 pytorch笔记:06)requires_grad和volatile
原文地址: https://blog.csdn.net/jiangpeng59/article/details/80667335 作者:PJ-Javis 来源:CSDN --------------- ...
- pytorch笔记:09)Attention机制
刚从图像处理的hole中攀爬出来,刚走一步竟掉到了另一个hole(fire in the hole*▽*) 1.RNN中的attentionpytorch官方教程:https://pytorch.or ...
- [pytorch笔记] 调整网络学习率
1. 为网络的不同部分指定不同的学习率 class LeNet(t.nn.Module): def __init__(self): super(LeNet, self).__init__() self ...
- [pytorch笔记] torch.nn vs torch.nn.functional; model.eval() vs torch.no_grad(); nn.Sequential() vs nn.moduleList
1. torch.nn与torch.nn.functional之间的区别和联系 https://blog.csdn.net/GZHermit/article/details/78730856 nn和n ...
- Pytorch笔记 (3) 科学计算1
一.张量 标量 可以看作是 零维张量 向量 可以看作是 一维张量 矩阵 可以看作是 二维张量 继续扩展数据的维度,可以得到更高维度的张量 ————> 张量又称 多维数组 给定一个张量数据 ...
- Pytorch笔记 (2) 初识Pytorch
一.人工神经网络库 Pytorch ———— 让计算机 确定神经网络的结构 + 实现人工神经元 + 搭建人工神经网络 + 选择合适的权重 (1)确定人工神经网络的 结构: 只需要告诉Pytorc ...
- PyTorch笔记之 Dataset 和 Dataloader
一.简介 在 PyTorch 中,我们的数据集往往会用一个类去表示,在训练时用 Dataloader 产生一个 batch 的数据 https://pytorch.org/tutorials/begi ...
随机推荐
- [AWS] 02 - Pipeline on EMR
Data Analysis with EMR. Video demo: Run Spark Application(Scala) on Amazon EMR (Elastic MapReduce) c ...
- js运动基础2(运动的封装)
简单运动的封装 先从最简单的封装开始,慢慢的使其更丰富,更实用. 还是上一篇博文的代码,在此不作细说. 需求:点击按钮,让元素匀速运动. <!DOCTYPE html> <html ...
- asp.netcore 3.0 Docker Nginx(震惊,原来docker是这样的!)
引言 Docker发布于2013年,Docker是dotCloud公司创始人在法国期间发起的一个公司内部项目,他是dotCloud多年云技术的一个革新.Docker在容器基础上进行了一步的封装,从网络 ...
- Spring Boot 监听 Activemq 中的特定 topic ,并将数据通过 RabbitMq 发布出去
1.Spring Boot 和 ActiveMQ .RabbitMQ 简介 最近因为公司的项目需要用到 Spring Boot , 所以自学了一下, 发现它与 Spring 相比,最大的优点就是减少了 ...
- JS/Jquery关系
1. JS / JQuery介绍 Jquery是JS库,何为JS库,即把常用的js方法进行封装,封装到单独的JS文件中,要用的时候直接调用即可: 2. JS / JQuery对象 1. 定义 (1) ...
- Angular 内嵌视图、宿主视图
解析视图: 内嵌视图 - 连接到模板的嵌入视图,在组件模板元素中添加模板(DOM元素.DOM元素组) 宿主视图 - 连接到组件的嵌入视图,在组件元素中添加别的组件 使用类说明: ElementRef ...
- 同时支持EF+Dapper的混合仓储,助你快速搭建数据访问层
背景 17年开始,公司开始向DotNet Core转型,面对ORM工具的选型,当时围绕Dapper和EF发生了激烈的讨论.项目团队更加关注快速交付,他们主张使用EF这种能快速开发的ORM工具:而在线业 ...
- python - json模块使用 / 快速入门
json基本格式 """ json格式 -> [{}, {}]: [{ "name": "Bob", "gende ...
- 六、springboot 简单优雅是实现短信服务
前言 上一篇讲了 springboot 集成邮件服务,接下来让我们一起学习下springboot项目中怎么使用短信服务吧. 项目中的短信服务基本上上都会用到,简单的注册验证码,消息通知等等都会用到.所 ...
- RocketMQ消息队列部署与可视化界面安装
MQ安装部署 最新版本下载:http://rocketmq.apache.org/release_notes 修改配置 vi conf/broker.conf 添加brokerIP1 brokerIP ...