DFA敏感词过滤实现
package test.java.com.odianyun.util.sensi; import java.util.*; /**
* 敏感词处理工具 - DFA算法实现
*
* @author sam
* @since 2017/9/4
*/
public class test { /**
* 敏感词匹配规则
*/
public static final int MinMatchTYpe = 1; //最小匹配规则,如:敏感词库["中国","中国人"],语句:"我是中国人",匹配结果:我是[中国]人
public static final int MaxMatchType = 2; //最大匹配规则,如:敏感词库["中国","中国人"],语句:"我是中国人",匹配结果:我是[中国人] /**
* 敏感词集合
*/
public static HashMap sensitiveWordMap; /**
* 初始化敏感词库,构建DFA算法模型
*
* @param sensitiveWordSet 敏感词库
*/
public static synchronized void init(Set<String> sensitiveWordSet) {
initSensitiveWordMap(sensitiveWordSet);
} /**
* 初始化敏感词库,构建DFA算法模型
*
* @param sensitiveWordSet 敏感词库
*/
private static void initSensitiveWordMap(Set<String> sensitiveWordSet) {
//初始化敏感词容器,减少扩容操作
sensitiveWordMap = new HashMap(sensitiveWordSet.size());
String key;
Map nowMap;
Map<String, String> newWorMap;
//迭代sensitiveWordSet
Iterator<String> iterator = sensitiveWordSet.iterator();
while (iterator.hasNext()) {
//关键字
key = iterator.next();
nowMap = sensitiveWordMap;
for (int i = 0; i < key.length(); i++) {
//转换成char型
char keyChar = key.charAt(i);
//库中获取关键字
Object wordMap = nowMap.get(keyChar);
//如果存在该key,直接赋值,用于下一个循环获取
if (wordMap != null) {
nowMap = (Map) wordMap;
} else {
//不存在则,则构建一个map,同时将isEnd设置为0,因为他不是最后一个
newWorMap = new HashMap<>();
//不是最后一个
newWorMap.put("isEnd", "0");
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
} if (i == key.length() - 1) {
//最后一个
nowMap.put("isEnd", "1");
}
}
}
} /**
* 判断文字是否包含敏感字符
*
* @param txt 文字
* @param matchType 匹配规则 1:最小匹配规则,2:最大匹配规则
* @return 若包含返回true,否则返回false
*/
public static boolean contains(String txt, int matchType) {
boolean flag = false;
for (int i = 0; i < txt.length(); i++) {
int matchFlag = checkSensitiveWord(txt, i, matchType); //判断是否包含敏感字符
if (matchFlag > 0) { //大于0存在,返回true
flag = true;
}
}
return flag;
} /**
* 判断文字是否包含敏感字符
*
* @param txt 文字
* @return 若包含返回true,否则返回false
*/
public static boolean contains(String txt) {
return contains(txt, MaxMatchType);
} /**
* 获取文字中的敏感词
*
* @param txt 文字
* @param matchType 匹配规则 1:最小匹配规则,2:最大匹配规则
* @return
*/
public static Set<String> getSensitiveWord(String txt, int matchType) {
Set<String> sensitiveWordList = new HashSet<>(); for (int i = 0; i < txt.length(); i++) {
//判断是否包含敏感字符
int length = checkSensitiveWord(txt, i, matchType);
if (length > 0) {//存在,加入list中
sensitiveWordList.add(txt.substring(i, i + length));
i = i + length - 1;//减1的原因,是因为for会自增
}
} return sensitiveWordList;
} /**
* 获取文字中的敏感词
*
* @param txt 文字
* @return
*/
public static Set<String> getSensitiveWord(String txt) {
return getSensitiveWord(txt, MaxMatchType);
} /**
* 替换敏感字字符
*
* @param txt 文本
* @param replaceChar 替换的字符,匹配的敏感词以字符逐个替换,如 语句:我爱中国人 敏感词:中国人,替换字符:*, 替换结果:我爱***
* @param matchType 敏感词匹配规则
* @return
*/
public static String replaceSensitiveWord(String txt, char replaceChar, int matchType) {
String resultTxt = txt;
//获取所有的敏感词
Set<String> set = getSensitiveWord(txt, matchType);
Iterator<String> iterator = set.iterator();
String word;
String replaceString;
while (iterator.hasNext()) {
word = iterator.next();
replaceString = getReplaceChars(replaceChar, word.length());
resultTxt = resultTxt.replaceAll(word, replaceString);
} return resultTxt;
} /**
* 替换敏感字字符
*
* @param txt 文本
* @param replaceChar 替换的字符,匹配的敏感词以字符逐个替换,如 语句:我爱中国人 敏感词:中国人,替换字符:*, 替换结果:我爱***
* @return
*/
public static String replaceSensitiveWord(String txt, char replaceChar) {
return replaceSensitiveWord(txt, replaceChar, MaxMatchType);
} /**
* 替换敏感字字符
*
* @param txt 文本
* @param replaceStr 替换的字符串,匹配的敏感词以字符逐个替换,如 语句:我爱中国人 敏感词:中国人,替换字符串:[屏蔽],替换结果:我爱[屏蔽]
* @param matchType 敏感词匹配规则
* @return
*/
public static String replaceSensitiveWord(String txt, String replaceStr, int matchType) {
String resultTxt = txt;
//获取所有的敏感词
Set<String> set = getSensitiveWord(txt, matchType);
Iterator<String> iterator = set.iterator();
String word;
while (iterator.hasNext()) {
word = iterator.next();
resultTxt = resultTxt.replaceAll(word, replaceStr);
} return resultTxt;
} /**
* 替换敏感字字符
*
* @param txt 文本
* @param replaceStr 替换的字符串,匹配的敏感词以字符逐个替换,如 语句:我爱中国人 敏感词:中国人,替换字符串:[屏蔽],替换结果:我爱[屏蔽]
* @return
*/
public static String replaceSensitiveWord(String txt, String replaceStr) {
return replaceSensitiveWord(txt, replaceStr, MaxMatchType);
} /**
* 获取替换字符串
*
* @param replaceChar
* @param length
* @return
*/
private static String getReplaceChars(char replaceChar, int length) {
String resultReplace = String.valueOf(replaceChar);
for (int i = 1; i < length; i++) {
resultReplace += replaceChar;
} return resultReplace;
} /**
* 检查文字中是否包含敏感字符,检查规则如下:<br>
*
* @param txt
* @param beginIndex
* @param matchType
* @return 如果存在,则返回敏感词字符的长度,不存在返回0
*/
private static int checkSensitiveWord(String txt, int beginIndex, int matchType) {
//敏感词结束标识位:用于敏感词只有1位的情况
boolean flag = false;
//匹配标识数默认为0
int matchFlag = 0;
char word;
Map nowMap = sensitiveWordMap;
for (int i = beginIndex; i < txt.length(); i++) {
word = txt.charAt(i);
//获取指定key
nowMap = (Map) nowMap.get(word);
if (nowMap != null) {//存在,则判断是否为最后一个
//找到相应key,匹配标识+1
matchFlag++;
//如果为最后一个匹配规则,结束循环,返回匹配标识数
if ("1".equals(nowMap.get("isEnd"))) {
//结束标志位为true
flag = true;
//最小规则,直接返回,最大规则还需继续查找
if (MinMatchTYpe == matchType) {
break;
}
}
} else {//不存在,直接返回
break;
}
}
if (matchFlag < 2 || !flag) {//长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
} public static void main(String[] args) { Set<String> sensitiveWordSet = new HashSet<>();
sensitiveWordSet.add("太多");
sensitiveWordSet.add("爱恋");
sensitiveWordSet.add("静静");
sensitiveWordSet.add("哈哈");
sensitiveWordSet.add("啦啦");
sensitiveWordSet.add("感动");
sensitiveWordSet.add("发呆");
//初始化敏感词库
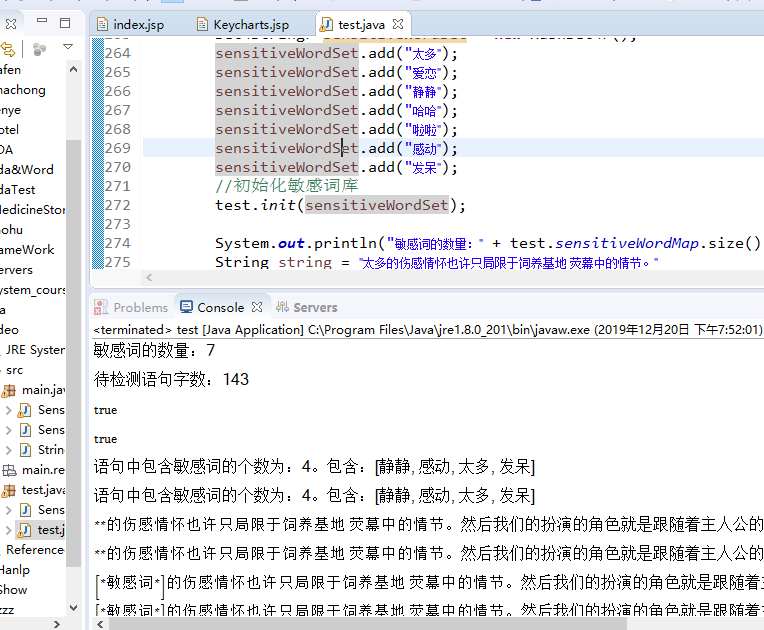
test.init(sensitiveWordSet); System.out.println("敏感词的数量:" + test.sensitiveWordMap.size());
String string = "太多的伤感情怀也许只局限于饲养基地 荧幕中的情节。"
+ "然后我们的扮演的角色就是跟随着主人公的喜红客联盟 怒哀乐而过于牵强的把自己的情感也附加于银幕情节中,然后感动就流泪,"
+ "难过就躺在某一个人的怀里尽情的阐述心扉或者手机卡复制器一个贱人一杯红酒一部电影在夜 深人静的晚上,关上电话静静的发呆着。";
System.out.println("待检测语句字数:" + string.length()); //是否含有关键字
boolean result = test.contains(string);
System.out.println(result);
result = test.contains(string, test.MinMatchTYpe);
System.out.println(result); //获取语句中的敏感词
Set<String> set = test.getSensitiveWord(string);
System.out.println("语句中包含敏感词的个数为:" + set.size() + "。包含:" + set);
set = test.getSensitiveWord(string, test.MinMatchTYpe);
System.out.println("语句中包含敏感词的个数为:" + set.size() + "。包含:" + set); //替换语句中的敏感词
String filterStr = test.replaceSensitiveWord(string, '*');
System.out.println(filterStr);
filterStr = test.replaceSensitiveWord(string, '*', test.MinMatchTYpe);
System.out.println(filterStr); String filterStr2 = test.replaceSensitiveWord(string, "[*敏感词*]");
System.out.println(filterStr2);
filterStr2 = test.replaceSensitiveWord(string, "[*敏感词*]", test.MinMatchTYpe);
System.out.println(filterStr2);
} }
效果:
转自博客:https://www.cnblogs.com/magicalSam/p/7473780.html
DFA敏感词过滤实现的更多相关文章
- DFA敏感词过滤
import java.io.UnsupportedEncodingException; import java.nio.ByteBuffer; import java.util.ArrayList; ...
- java实现敏感词过滤(DFA算法)
小Alan在最近的开发中遇到了敏感词过滤,便去网上查阅了很多敏感词过滤的资料,在这里也和大家分享一下自己的理解. 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxo ...
- DFA和trie特里实现敏感词过滤(python和c语言)
今天的项目是与完成python开展,需要使用做关键词检查,筛选分类,使用前c语言做这种事情.有了线索,非常高效,内存小了,检查快. 到达python在,第一个想法是pip基于外观的c语言python特 ...
- Java实现敏感词过滤 - DFA算法
Java实现DFA算法进行敏感词过滤 封装工具类如下: 使用前需对敏感词库进行初始化: SensitiveWordUtil.init(sensitiveWordSet); package cn.swf ...
- 敏感词过滤的算法原理之DFA算法
参考文档 http://blog.csdn.net/chenssy/article/details/26961957 敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有 ...
- 基于DFA算法、RegExp对象和vee-validate实现前端敏感词过滤
面临敏感词过滤的问题,最简单的方案就是对要检测的文本,遍历所有敏感词,逐个检测输入的文本是否包含指定的敏感词. 很明显上面这种实现方法的检测时间会随着敏感词库数量的增加而线性增加.系统会因此面临性能和 ...
- Java实现敏感词过滤
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
- java敏感词过滤
敏感词过滤在网站开发必不可少.一般用DFA,这种比较好的算法实现的. 参考链接:http://cmsblogs.com/?p=1031 一个比较好的代码实现: import java.io.IOExc ...
- Java实现敏感词过滤(转)
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
随机推荐
- Batch Normalization详解
目录 动机 单层视角 多层视角 什么是Batch Normalization Batch Normalization的反向传播 Batch Normalization的预测阶段 Batch Norma ...
- 使用IDEA2017.3.5搭建SSM框架
转载自博客园,附上原文地址https://www.cnblogs.com/hackyo/p/6646051.html?utm_source=itdadao&utm_medium=referra ...
- 链接脚本(Linker Script)用法解析(二) clear_table & copy_table
可执行文件中的.bss段和.data段分别存放未赋初值的全局变量和已赋初值的全局变量,两者的特点分别为: (1).bss段:①无初值,所以不占ROM空间:②运行时存储于RAM:③默认初值为0 (2). ...
- 华为ARM64服务器上手体验--不吹不黑,用实际应用来看看TaiShan鲲鹏的表现
背景 中美贸易冲突以来,相信最大的感受,并不是我对你加多少关税,而是我有,可我不卖给你."禁售"成了市场经济中最大的竞争力. 相信也是因为这个原因,华为"备胎转正&quo ...
- gitbook 入门教程之自定义不一样的多语言首页插件
自定义多语言主页 中文 | English
- MySql数据库之单表数据查询
查询数据 1.查询所有数据: select * from 表名; 2.根据指定条件查询数据:
- 使用 nginx 实现虚拟主机
当多个系统需要部署的时候,有系统访问很小,为了节省成本,就需要将多个系统部署到同一台服务器上,怎么在同一台服务器上,完成不同系统的部署和访问,就需要使用虚拟主机实现. 使用端口实现虚拟主机 配置 ng ...
- UVA-11995
There is a bag-like data structure, supporting two operations:1 x Throw an element x into the bag.2 ...
- Swap Digits
Description ) in the first line, which has the same meaning as above. And the number is in the next ...
- CodeForces-617E XOR And Favorite Numbers(莫队)
Bob has a favorite number k and ai of length n. Now he asks you to answer m queries. Each query is g ...