Solr搜索引擎【索引提交、事务日志、原子更新】
一.索引提交
当一个文档被添加到Solr中,但没有提交给索引之前,这个文档是无法被搜索的。换句话说,从查询的角度看,文档直到提交之后才是可见的。Solr有两种类型的提交:软提交和正常提交【也称硬提交】。
1.正常提交
Solr正常提交是将所有未提交的文档写入磁盘,并刷新一个内部搜索器组件,让新提交的文档能够被搜索。搜索器实际上可以看作索引中所有已提交文档的只读视图。可以这样说,硬提交是花销很大的操作,由于硬提交需要开启一个新搜索器,所以会影响到查询性能。
当正常提交成功后,新提交的文档被安全保存在持久存储器上不会因为正常的维护操作或服务器崩溃重启而丢失。出于高可用性考虑,如果磁盘发生故障,就需要一套故障转移方案,这一点在以后接着讨论。
2.软提交
软提交支持近实时搜索【Near Real-Time NRT】。软提交作为近乎实时可被搜索到的一种机制,跳过了硬提交的高消耗,例如,刷新到持久存储器就是花销较大的操作。软提交相对而言花销较低,可以每一秒都执行一次软提交,使得新近被索引的文档在添加到Solr之后很快被搜索到。但要记住,在某一时刻仍然需要执行硬提交操作,以确保文档最终被写入到持久化存储器中。
综上所述:
》硬提交让文档可被搜索,由于需要将其写入到持久化存储器中,所以花销较大
》软提交也可以让文档被搜索,不需要将其写入到持久化存储中
3.自动提交
不管是正常提交还是软提交,都可以采用以下三种策略中的一种来自动提交文档:
》在指定时间内提交文档
》一旦达到用户指定的未提交文档数阈值,就提交那么未提交的文档
》每隔特定时间间隔提交所有文档
4.配置
Solr硬提交与软提交的自动提交需要在solrconfig.xml中进行配置。
<!-- AutoCommit
Perform a hard commit automatically under certain conditions.
Instead of enabling autoCommit, consider using "commitWithin"
when adding documents.
http://wiki.apache.org/solr/UpdateXmlMessages
maxDocs - Maximum number of documents to add since the last
commit before automatically triggering a new commit.
maxTime - Maximum amount of time in ms that is allowed to pass
since a document was added before automatically
triggering a new commit.
openSearcher - if false, the commit causes recent index changes
to be flushed to stable storage, but does not cause a new
searcher to be opened to make those changes visible.
If the updateLog is enabled, then it's highly recommended to
have some sort of hard autoCommit to limit the log size.
-->
<autoCommit>
<maxTime>${solr.autoCommit.maxTime:15000}</maxTime> <!-- 上一次提交到自动提交的最长时间间隔 -->
<openSearcher>false</openSearcher> <!-- 提交后是否开启一个新的搜索器 -->
</autoCommit>
执行自动提交时通常会打开一个新搜索器。在默认情况下【未开启】,某文件自动提交,该文件将被写入到磁盘,但在搜索结果中不可见。Solr之所以提供这个选项,是为了减少未提交更新的事务日志大小,并避免在大规模索引过程中打开太多搜索器。
在solrconfig.xml中使用autoSoftCommit元素也可以自动配置软提交。
<!-- softAutoCommit is like autoCommit except it causes a
'soft' commit which only ensures that changes are visible
but does not ensure that data is synced to disk. This is
faster and more near-realtime friendly than a hard commit.
--> <autoSoftCommit>
<maxTime>${solr.autoSoftCommit.maxTime:-1}</maxTime> <!-- -1表示无限大 -->
</autoSoftCommit>
二.事务日志
Solr使用事务日志来确保提交到索引并已接受的更新保存在持久化存储器中。事务日志用来避免因提交过程中的异常情况而导致提交的文档丢失的情况。具体来说,事务日志主要有三个作用:
》支持近实时获取和原子更新【下面具体讲解】
》解除提交过程中写入的持久性
》通过solrcloud的分片代表支持副本的同步
在solrconfig.xml中的一个Solr内核的事务日志配置如下:
<!-- Enables a transaction log, used for real-time get, durability, and
and solr cloud replica recovery. The log can grow as big as
uncommitted changes to the index, so use of a hard autoCommit
is recommended (see below).
"dir" - the target directory for transaction logs, defaults to the
solr data directory.
"numVersionBuckets" - sets the number of buckets used to keep
track of max version values when checking for re-ordered
updates; increase this value to reduce the cost of
synchronizing access to version buckets during high-volume
indexing, this requires 8 bytes (long) * numVersionBuckets
of heap space per Solr core.
-->
<updateLog>
<str name="dir">${solr.ulog.dir:}</str> <!-- 默认目录是data目录下的tlog -->
<int name="numVersionBuckets">${solr.ulog.numVersionBuckets:65536}</int>
</updateLog>
每次提交情况都会被记录到事务日志中。直到发起提交之前,事务日志会持续增长。在提交期间会处理活动的事务日志,之后将打开一个新的事务日志。一个更新执行步骤如下:
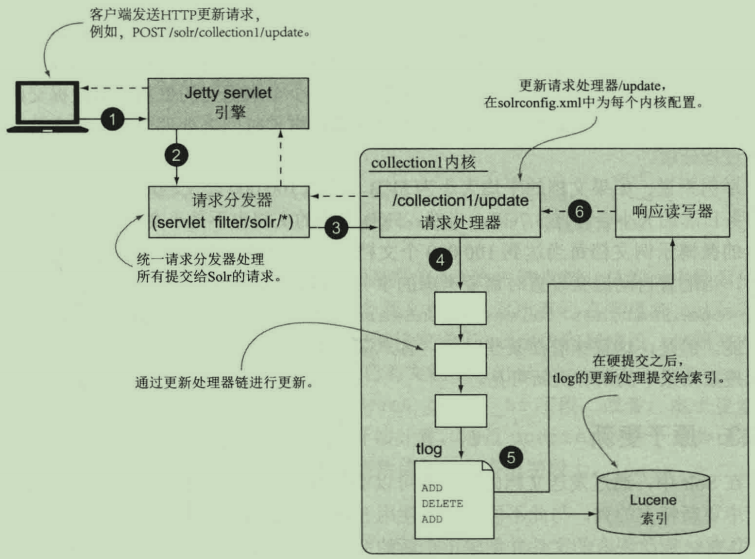
执行步骤解释如下:
1.客户端应用程序使用HTTP POST方式发送一个更新请求,可以是JSON/XML或者Solr内部二进制javabin格式
2.Jetty【Solr内部自带的WEB服务器】将此请求发送给Solr的Web应用程序
3.Solr的请求调度器通过请求路径中的collection名称确定调用的solr内核。接下来调度器定位到/update请求处理器
4.更新请求处理器对该请求进行处理,且该请求处理器将调用一个可配置的更新处理器链,在索引时为每个文档进行额外的处理
5.ADD请求写入到事务日志中
6.一旦更新请求被安全地保存到持久存储器,就会通过响应读写器回应客户端应用。这时,客户端应用得知更新请求成功执行,就可以继续执行下面的请求
注意,事务日志的关键在于权衡事务日志的长度与硬提交的执行频率。如果事务日志变得很庞大,重启就需要更长时间来处理更新,也会造成恢复过程缓慢。
三.原子更新
1.字段级别的更新
在Solr中,通过发送文档的新版本可以实现对已有文档的更新。数据库可以在一行中更新特定的列,与此不同的是,使用Solr必须更新整个文档。Solr实际执行的操作是,删除现有的文件并创建一个新的文件。不管是更改一个字段还是全部字段,都是这样执行。
从客户端的角度来看,应用程序必须发送整个文档的新版本。对于文档来自于其他来源的应用程序来说,这不是什么大问题。但是,对于那些将Solr作为主要数据存储的应用程序来说,为了更新单个字段而要重新创建全部文档,这可能会产生问题。在实践中,这需要客户先查询出整个文档,并将指定的文档整体发回给Solr。
对于已存在的文档请求所有字段,更新字段的子集,并发送新版本给Solr。这样的做法在实践中是很常见的。因此,原子更新就是为了解决这种情况,通过它可以实现仅对需要更新的字段进行更新,这让Solr更符合数据库的更新操作。Solr内部仍是删除和新建文档,但这些对客户端应用程序代码来说是通明的。
在更新操作中只需指定操作类型是更新即可:
xml配置:update="set"
java接口:
Map<String,String> map = new HashMap<String, String>();
map.set("name", "zhangshan")
doc.addField("set", map)
2.积极的并发控制
当两个用户同时对同一个文档进行更新时,如何执行就是一个并发的问题。当然,我们可以通过一些繁琐的过程,在一个用户更新前,显式锁定文档,但这会降低处理效率。因此,需要一些方法来防止同一文档上的并发更新,也就是积极的并发控制。
为了避免冲突,Solr通过版本跟踪字段_version_来支持积极的并发控制。在schema.xml中定义版本字段:
<!-- If you remove this field, you must _also_ disable the update log in solrconfig.xml
or Solr won't start. _version_ and update log are required for SolrCloud
-->
<!-- doc values are enabled by default for primitive types such as long so we don't index the version field -->
<field name="_version_" type="plong" indexed="false" stored="false"/> <!-- 禁止删除或修改这个字段 -->
当添加一个新文档时,Solr会自动分配一个唯一版本号。当需要警惕并发更新时,则在更新请求中包含精确的更新版本。当Solr处理此更新时,它会比较更新请求的_version_值与文档最新版本。文档的最新版本从索引或事务日志中获得。如果版本匹配,则进行更新。否则,更新失败。要获取最新的版本号,最好的方法是使用近实时的get请求。
全部匹配策略如下:

Solr搜索引擎【索引提交、事务日志、原子更新】的更多相关文章
- solr的原子更新/局部更新
solr支持三种类型的原子更新: set - to set a field. add - to add to a multi-valued field. inc - to increment a fi ...
- solr4.x之原子更新
solr4.x发布以后,最值得人关注的一个功能,就是原子更新功能,传说的solr是否能真正的做到像数据库一样,支持单列更新呢? 在solr官方的介绍中,原子更新是filed级别的更新,不会涉及整个Do ...
- solr/solrj原子更新
lucene原子更新自己不用多介绍,但solr它的包装,下面是一个简单的介绍是:这个操作是用于索引非常有用. 详细在代码中使用例如以下: /** * 原子更新方式 * */ public static ...
- 配置好solr搜索引擎服务器后java后台如何将商品信息导入索引库
首先,在配置文件目录中添加solr 服务器的bean 配置文件 solr服务器的url可以写在配置文件中: url地址其实就是我们网页可以访问的solr地址: 然后我们写 service packag ...
- 最全BT磁力搜索引擎索引(整理分享,不断更新...)
最全BT磁力搜索引擎索引(整理分享,不断更新...) btkitty:http://cnbtkitty.com/(知名的BT磁力搜索,资源很多) idope.se:https://idope.se/( ...
- c#实例化继承类,必须对被继承类的程序集做引用 .net core Redis分布式缓存客户端实现逻辑分析及示例demo 数据库笔记之索引和事务 centos 7下安装python 3.6笔记 你大波哥~ C#开源框架(转载) JSON C# Class Generator ---由json字符串生成C#实体类的工具
c#实例化继承类,必须对被继承类的程序集做引用 0x00 问题 类型“Model.NewModel”在未被引用的程序集中定义.必须添加对程序集“Model, Version=1.0.0.0, Cu ...
- Elasticsearch vs Solr 搜索引擎对比和选型
前言 全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选. 基于Lucene它可以快速地储存.搜索和分析海量数据.维基百科.Stack Overflow.Githu ...
- SQL Server中的事务日志管理(9/9):监控事务日志
当一切正常时,没有必要特别留意什么是事务日志,它是如何工作的.你只要确保每个数据库都有正确的备份.当出现问题时,事务日志的理解对于采取修正操作是重要的,尤其在需要紧急恢复数据库到指定点时.这系列文章会 ...
- SQL Server中的事务日志管理(8/9):优化日志吞吐量
当一切正常时,没有必要特别留意什么是事务日志,它是如何工作的.你只要确保每个数据库都有正确的备份.当出现问题时,事务日志的理解对于采取修正操作是重要的,尤其在需要紧急恢复数据库到指定点时.这系列文章会 ...
随机推荐
- python3 range 倒序
话不多说上代码,要求简单,从100到1遍历操作. //第三个参数表示的是100所有进行的操作,每次加上-1,直到0 for i in range(100,0,-1): print(i)
- 学习笔记03http协议
1.浏览器就是一个sokect客户端,使用http协议与服务器进行交流.http请求:请求头:(请求方法)sp(url)sp http/1.x <cr><lf>(通用头类型名) ...
- 学习笔记51_MongoDB使用
MongoDB的包: 例如:设置Mongodb端口 在命令行: F:\MongoDB>mongod.exe --port:3306 做集群: 安装和使用: 1.在服务中添加MongoDB ( 指 ...
- Pandas IO 操作
数据分析过程中经常需要进行读写操作,Pandas实现了很多 IO 操作的API 格式类型 数据描述 Reader Writer text CSV read_csv to_csv text JSON r ...
- .netcore之DI批量注入(支持泛型) - xms
一旦系统内模块比较多,按DI标准方法去逐个硬敲AddScoped/AddSingleton/AddTransient缺乏灵活性且效率低下,所以批量注入提供了很大的便捷性,特别是对于泛型的服务类,下面介 ...
- 腾讯正式开源图计算框架Plato,十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- RocketMQ ACL使用指南
目录 1.什么是ACL? 2.ACL基本流程图 3.如何配置ACL 3.1 acl配置文件 3.2 RocketMQ ACL权限可选值 3.3.权限验证流程 4.使用示例 4.1 Broker端安装 ...
- redis 数据库主从不一致问题解决方案
在聊数据库与缓存一致性问题之前,先聊聊数据库主库与从库的一致性问题. 问:常见的数据库集群架构如何? 答:一主多从,主从同步,读写分离. 如上图: (1)一个主库提供写服务 (2)多个从库提供读服务 ...
- 理解Spark运行模式(一)(Yarn Client)
Spark运行模式有Local,STANDALONE,YARN,MESOS,KUBERNETES这5种,其中最为常见的是YARN运行模式,它又可分为Client模式和Cluster模式.这里以Spar ...
- (二)初识NumPy库(数组的操作和运算)
本章主要介绍的是ndarray数组的操作和运算! 一. ndarray数组的操作: 操作是指对数组的索引和切片.索引是指获取数组中特定位置元素的过程:切片是指获取数组中元素子集的过程. 1.一维数组的 ...