scrapy获取汽车之家数据
1、创建scrapy项目
>scrapy startproject scrapy_carhome
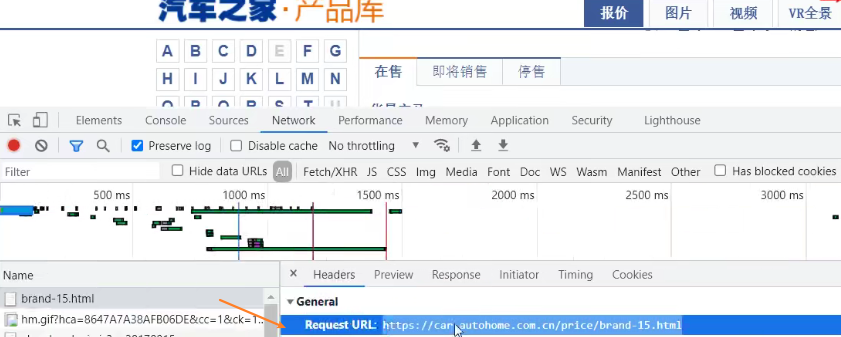
2、找到对应接口
3、创建爬虫文件
> cd scrapy_carhome\scrapy_carhome\spiders
scrapy_carhome\scrapy_carhome\spiders> scrapy genspider car https://car.autohome.com.cn/price/brand-15.html
4、注释robots协议
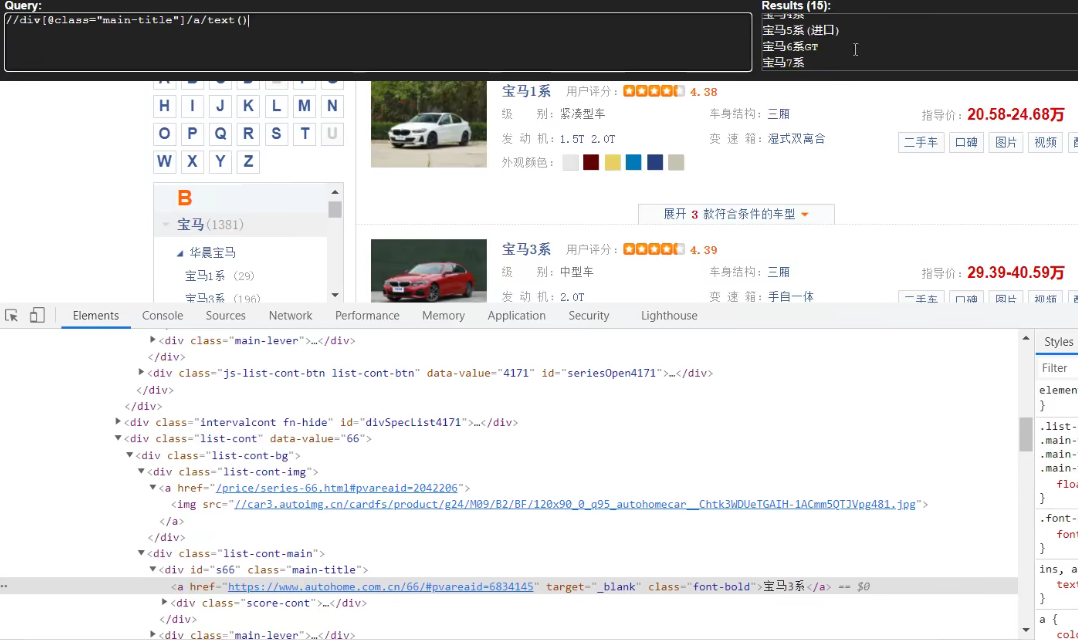
//div[@class="main-title"]/a/text()
//div[@class="main-lever"]//span/span/text()

car.py
import scrapy class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['https://car.autohome.com.cn/price/brand-15.html']
# 注意如果你的请求的接口是html为结尾的 那么是不需要加/的
start_urls = ['https://car.autohome.com.cn/price/brand-15.html'] def parse(self, response):
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//div[@class="main-lever"]//span/span/text()')
# 遍历列表
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
print(name,price)
运行爬虫文件
scrapy_carhome\scrapy_carhome\spiders>scrapy crawl car



scrapy获取汽车之家数据的更多相关文章
- PuppeteerSharp+AngleSharp的爬虫实战之汽车之家数据抓取
参考了DotNetSpider示例, 感觉DotNetSpider太重了,它是一个比较完整的爬虫框架. 对比了以下各种无头浏览器,最终采用PuppeteerSharp+AngleSharp写一个爬虫示 ...
- python爬虫——汽车之家数据
相信很多买车的朋友,首先会在网上查资料,对比车型价格等,首选就是"汽车之家",于是,今天我就给大家扒一扒汽车之家的数据: 一.汽车价格: 首先获取的数据是各款汽车名称.价格范围以及 ...
- scrapy获取当当网中数据
yield 1. 带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代 2. yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yiel ...
- 爬虫实战:汽车之家配置页面 破解伪元素和混淆JS
本篇介绍如何破解汽车之家配置页面的伪元素和混淆的JS. ** 温馨提示:如需转载本文,请注明内容出处.** 本文链接:https://www.cnblogs.com/grom/p/9242156.ht ...
- 汽车之家店铺数据抓取 DotnetSpider实战[一]
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- 汽车之家店铺商品详情数据抓取 DotnetSpider实战[二]
一.迟到的下期预告 自从上一篇文章发布到现在,大约差不多有3个月的样子,其实一直想把这个实战入门系列的教程写完,一个是为了支持DotnetSpider,二个是为了.Net 社区发展献出一份绵薄之力,这 ...
- 汽车之家店铺数据抓取 DotnetSpider实战
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- python3 爬取汽车之家所有车型数据操作步骤(更新版)
题记: 互联网上关于使用python3去爬取汽车之家的汽车数据(主要是汽车基本参数,配置参数,颜色参数,内饰参数)的教程已经非常多了,但大体的方案分两种: 1.解析出汽车之家某个车型的网页,然后正则表 ...
- Python 爬取汽车之家口碑数据
本文仅供学习交流使用,如侵立删!联系方式见文末 汽车之家口碑数据 2021.8.3 更新 增加用户信息参数.认证车辆信息等 2021.3.24 更新 更新最新数据接口 2020.12.25 更新 添加 ...
随机推荐
- 从commons-beanutils反序列化到shiro无依赖的漏洞利用
目录 0 前言 1 环境 2 commons-beanutils反序列化链 2.1 TemplatesImple调用链 2.2 PriorityQueue调用链 2.3 BeanComparator ...
- Java初步学习——2021.09.24每日总结,第三周周五
(1)今天做了什么: (2)明天准备做什么? (3)遇到的问题,如何解决? 今天学了将数组传递给方法和方法返回数组,其中传递的是数组的引用. 明天把例子做了,尽量把查找也学习了. 遇到了两个问题: 1 ...
- 题解 「HDU6403」卡片游戏
link Description 桌面上摊开着一些卡牌,这是她平时很爱玩的一个游戏.如今卡牌还在,她却不在我身边.不知不觉,我翻开了卡牌,回忆起了当时一起玩卡牌的那段时间. 每张卡牌的正面与反面都各有 ...
- Hive架构及搭建方式
目录 前言 hive的基础知识 基本架构 metastore 内嵌服务和数据库 内嵌服务 服务和数据库单独部署 hcatalog 客户端 客户端的本地模式 beeline beeline的自动模式 j ...
- Mybatis 动态Sql练习
建表 CREATE TABLE `student` ( `s_id` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT ...
- Java:重载和重写
Java:重载和重写 对 Java 中的 重载和重写 这个概念,做一个微不足道的小小小小结 重载 重载:编译时多态,同一个类中的同名的方法,参数列表不同,与返回值无关. 有以下几点: 方法名必须相同: ...
- [对对子队]事后总结Beta
设想和目标 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 要做一个游戏,定义的很清楚,实现出来的效果贴近定义,对用户和场景有清晰描述 我们达到目标了么(原计划的功 ...
- [对对子队]会议记录5.14(Scrum Meeting1)
今天已完成的工作 何瑞 工作内容:初步完成循环指令系统 相关issue:实现循环语句系统的逻辑 相关签入:feat:循环语句的指令编辑系统初步完成 吴昭邦 工作内容:将流水线系统和循环 ...
- STM32学习笔记之核心板PCB设计
PCB设计流程 PCB规则设置 设计规则的单位跟随画布属性里设置的单位,此处单位是mil.导线线宽最小为10mil;不同网络元素之间最小间距为8mil;孔外径为24mil,孔内径为12mil;线长不做 ...
- linux下文件后面带~
之前发现有时候在命令行ls会看到一些文件后面带有-,而这些文件的名字和我们文件夹中的某些文件是一模一样的文件,在文件夹中没发现就很大胆地删掉了也没是,一直没管,觉得是什么临时复制的文件或者隐藏文件.今 ...