(数据科学学习手札124)pandas 1.3版本主要更新内容一览
本文示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
就在几天前,pandas发布了其1.3版本,在这次新的版本中添加了诸多实用的新特性,今天的文章我们就一起来get其中主要的一些内容更新~

2 pandas 1.3主要更新内容一览
使用pip install pandas==1.3.0 -U -i https://pypi.douban.com/simple/安装1.3版本后,下面我们来看看新的版本给我们带来了哪些新特性:
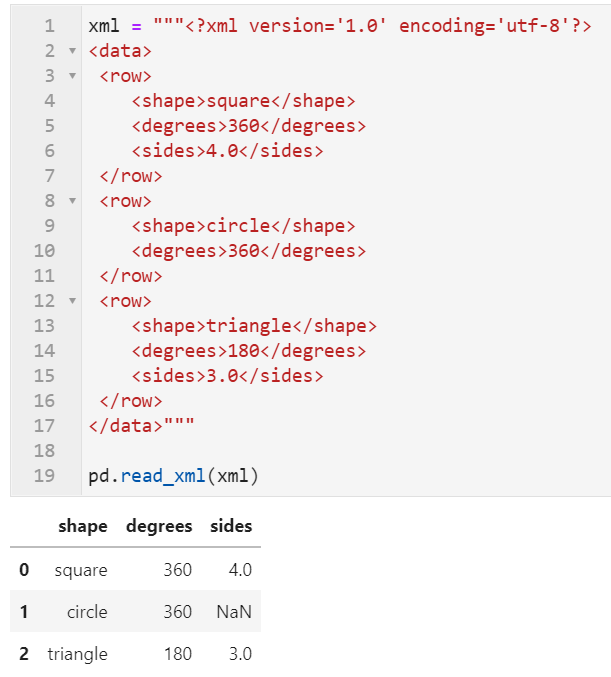
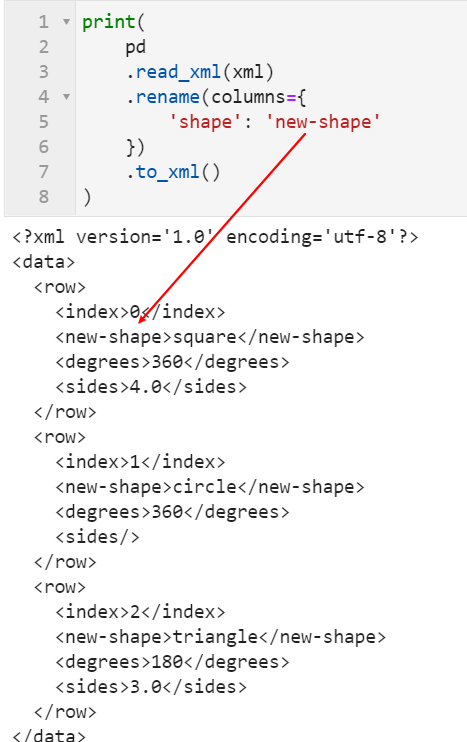
2.1 新增对xml文件的读写操作
在这次新版本中新增了对xml格式数据进行解析读写的功能,对此有特殊需求的朋友可以前往https://pandas.pydata.org/docs/user_guide/io.html#xml详细了解:
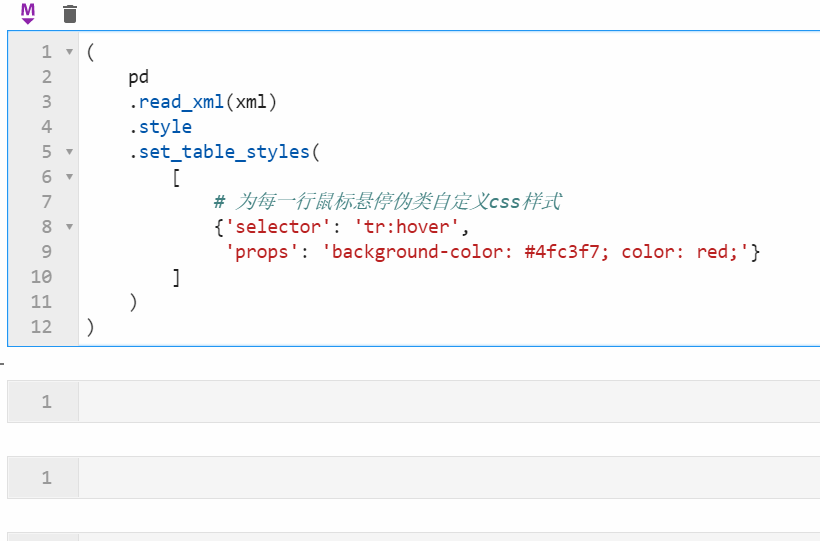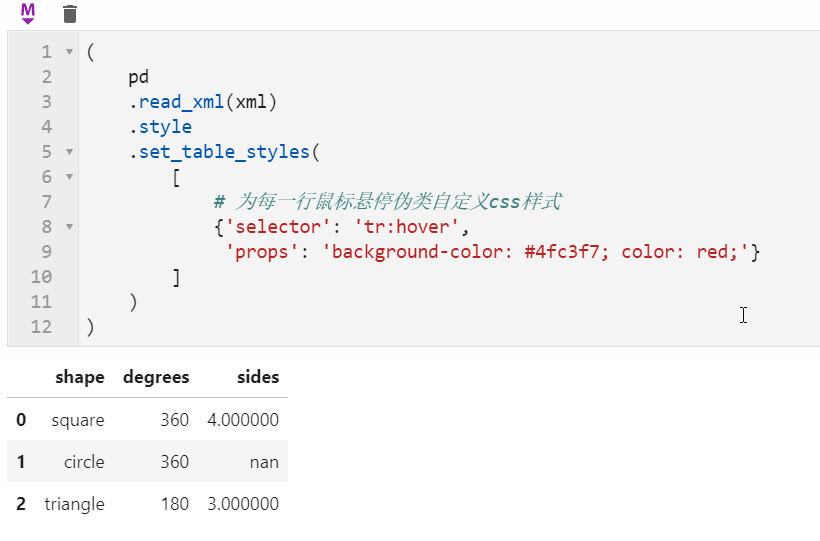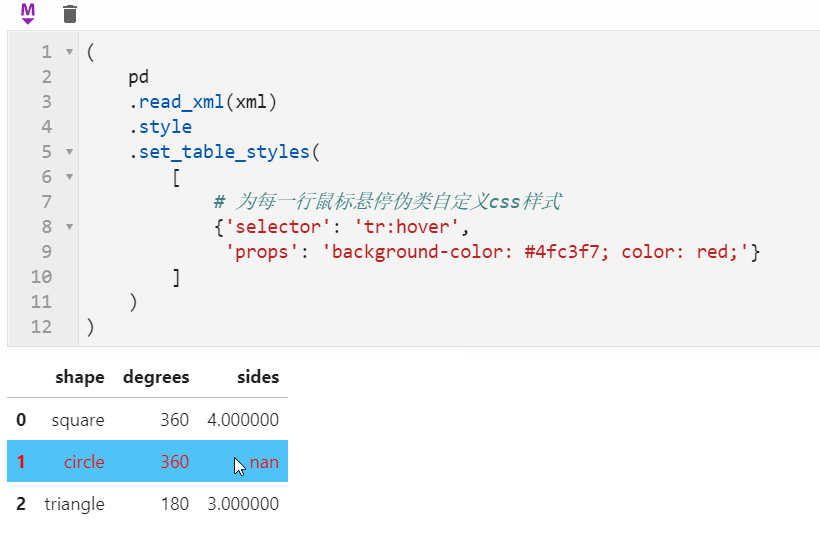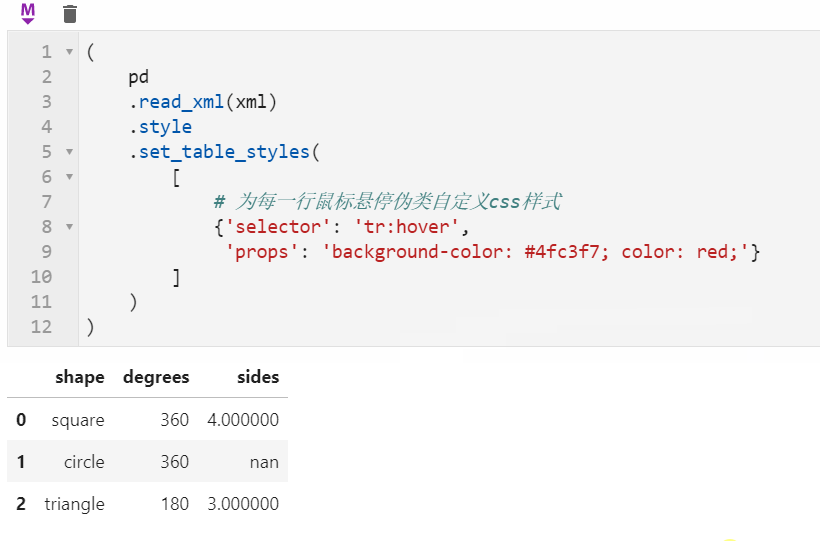
2.2 Styler可使用原生css语法
很多朋友都知道pandas中可以配合Styler对数据框进行自定义样式输出,其中最自由的是通过Styler.set_table_styles()来自定义css样式,以前的方式需要将一条css属性写到二元组中传入,在1.3版本中可以直接传入css字符串,比如下面我们通过设置hover伪类样式,来修改每一行鼠标悬停时的样式:
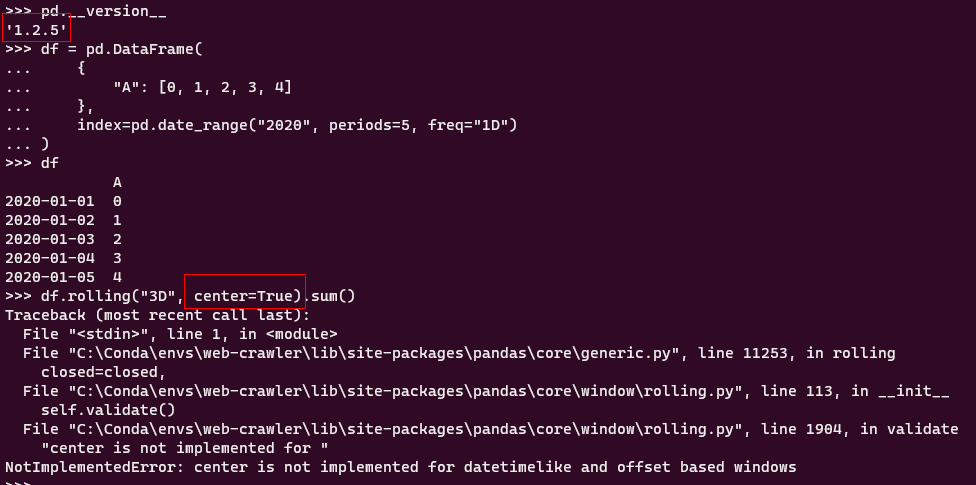
2.3 center参数在时间日期index的数据框rolling操作中可用
在先前的版本中,如果针对行索引为时间日期型的数据框进行rolling滑窗操作使用center参数将每行记录作为窗口中心时会报错:
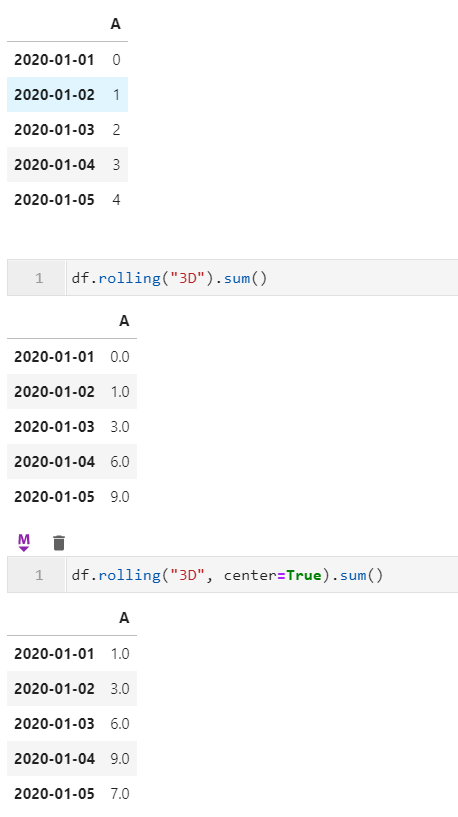
而在1.3中这个问题终于得到解决~方便了许多时序数据分析时的操作:
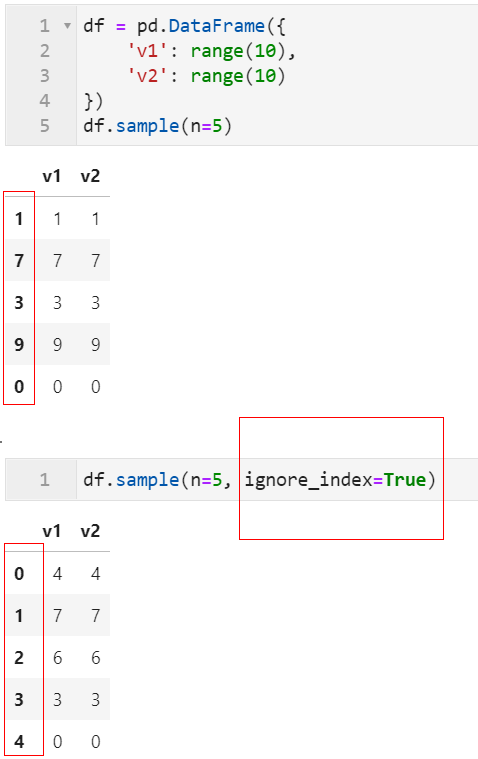
2.4 sample()随机抽样新增ignore_index参数
我们都知道在pandas中可以使用sample()方法对数据框进行各种放回/不放回抽样,但以前版本中抽完样的数据框每行记录还保持着先前的行索引,使得我们还得多一步reset_index()操作,而在1.3中,新增类似sort_values()和drop_duplicates()中的同名参数ignore_index:
2.5 explode()新增多列操作支持
当数据框中某些字段某些位置元素为列表、元组等数据结构时,我们可以使用explode()方法来基于这些序列型元素进行展开扩充,但在以前的版本中每次explode()操作只支持对单个字段的展开,如果数据中多个字段之间同一行对应序列型元素位置是一一对应的,需要展开后也是一一对应的,操作起来就比较棘手。
而1.3版本中直接对多字段同步explode()进行了支持:

2.6 append模式下写出多工作表excel文件的新策略
在1.3版本中,针对mode='a'模式下向外写出多工作表excel文件,新增了参数if_sheet_exists来设定新工作表与已存在工作表重名时的处理策略,默认为'error'即直接抛出错误,'new'则会自动修改工作表名,'replace'则会覆盖原同名工作表:

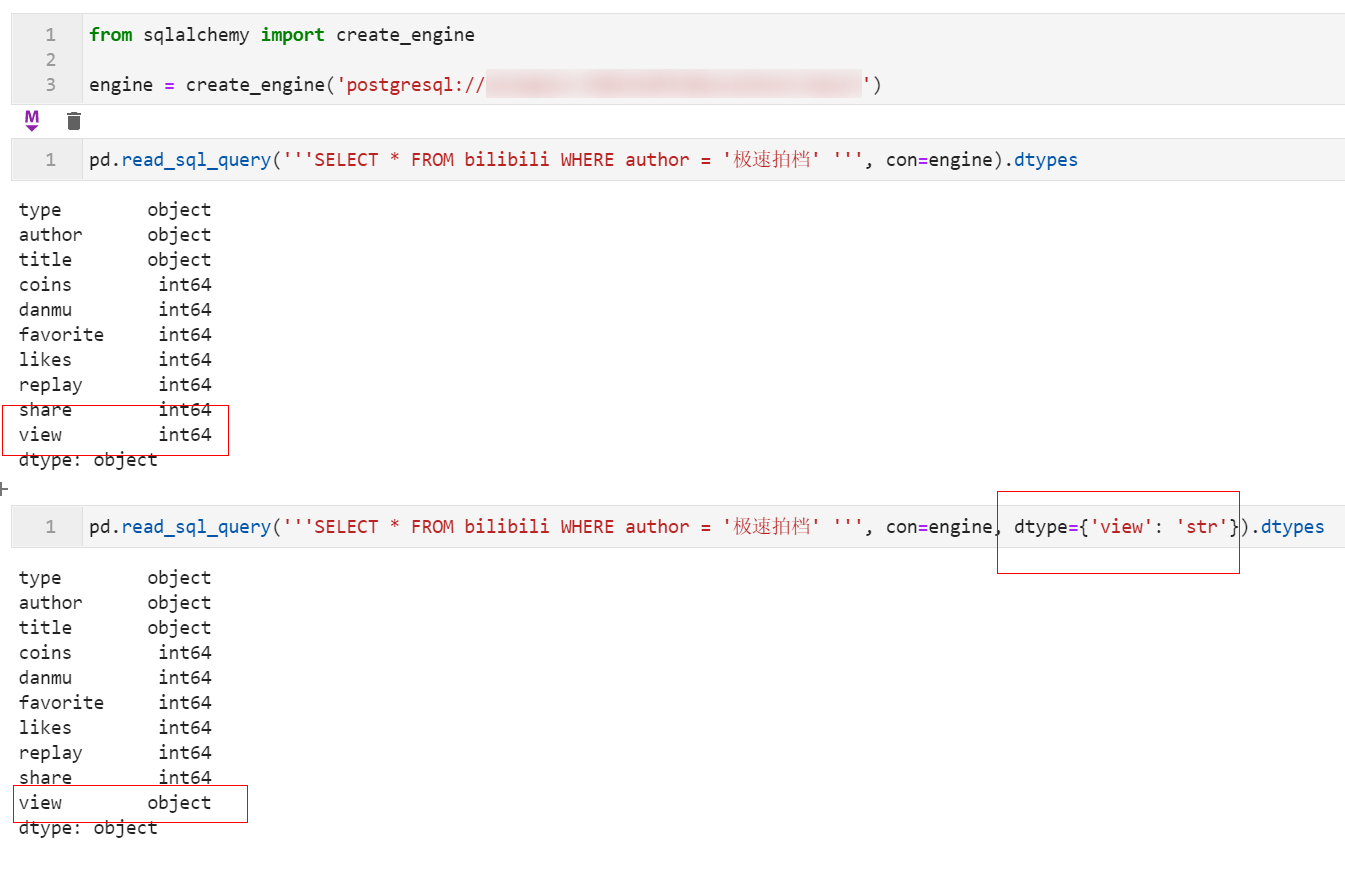
2.7 结合SQL读取数据库表时可直接设置类型转换
在1.3版本中,我们在使用read_sql_query()结合SQL查询数据库时,新增了参数dtype可以像在其他API中那样一步到位转换查询到的数据:
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札124)pandas 1.3版本主要更新内容一览的更多相关文章
- (数据科学学习手札89)geopandas&geoplot近期重要更新
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 最近一段时间(本文写作于2020-07-1 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- (数据科学学习手札90)Python+Kepler.gl轻松制作时间轮播图
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl作为一款强大的开源地理信 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
随机推荐
- Centos 7.4搭建es7.12.0+Skywalking7.8.5
Skywalking整体架构图和分布式追踪系统原理:https://blog.csdn.net/weixin_39866487/article/details/111581322 软件包版本1.ela ...
- 关于UCOSII的学习资料
UCOSII学习资料: 在战舰的A盘资料包中 ->软件资料->ucosii 有一个叫做简易OS讲解的文档,此文从简单的OS将其,通俗易懂的讲解大体的OS运行原理,任务调度的实现过程,是入门 ...
- STM32 串口接收大量数据导致死机
http://blog.csdn.net/origin333/article/details/49992383 以下文章出自上面的链接.感谢原创作者的分享. 在一项目中,使用STM32作为主控,程序运 ...
- AlertDailog中的which问题
在做一个AlertDialog的点击事件设置的时候: AlertDialog.Builder(this).apply { var numberIndex = 0 setTitle("choo ...
- Win10 安装 Python3 (上)
Python3 For Windows 10 installer 参考 The full installer 安装 随后可以看到,installer 在用户环境变量PATH中,添加了三项: 卸载 使用 ...
- linux ( crontab 定时任务命令)
linux ( crontab 定时任务命令) crontab 定时任务命令 linux 系统则是由 cron (crond) 这个系统服务来控制的.Linux 系统上面原本就有非常多的计划性工 ...
- GO语言基础---值传递与引用传递
package main import ( "fmt" ) /* 值传递 函数的[形式参数]是对[实际参数]的值拷贝 所有对地址中内容的修改都与外界的实际参数无关 所有基本数据类型 ...
- 将Tensor核心引入标准Fortran
将Tensor核心引入标准Fortran 调优的数学库是从HPC系统提取最终性能的一种简单而可靠的方法.但是,对于寿命长的应用程序或需要在各种平台上运行的应用程序,为每个供应商或库版本调整库调用可能是 ...
- YOLOV4各个创新功能模块技术分析(二)
YOLOV4各个创新功能模块技术分析(二) 四.数据增强相关-GridMask Data Augmentation 论文名称:GridMask Data Augmentation 论文地址:https ...
- TVM部署和集成Deploy and Integration
TVM部署和集成Deploy and Integration 本文包含如何将TVM部署到各种平台以及如何将其与项目集成. 与传统的深度学习框架不同.TVM堆栈分为两个主要组件: TVM编译器,完成所有 ...