python爬取疫情数据存入MySQL数据库
import requests
from bs4 import BeautifulSoup
import json
import time
from pymysql import * def mes():
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0' #请求地址
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36 SLBrowser/6.0.1.6181'}#创建头部信息
resp = requests.get(url,headers = headers) #发送网络请求
content=resp.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
listA = soup.find_all(name='script',attrs={"id":"getAreaStat"})
account =str(listA)
mes = account.replace('[<script id="getAreaStat">try { window.getAreaStat = ', '')
mes=mes.replace('}catch(e){}</script>]','')
#mes=account[52:-21]
messages_json = json.loads(mes)
print(messages_json)
times=time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
print(times)
provinceList=[]
cityList=[]
lenth=total()
con=len(messages_json)+lenth#算出数据库已有的条数+今天省份的条数,才是城市的开始id
for item in messages_json:
lenth+=1
provinceName=item['provinceName']
confirmedCount=item['confirmedCount']
suspectedCount=item['suspectedCount']
curedCount=item['curedCount']
deadCount=item['deadCount']
cities=item['cities']
provinceList.append((lenth,times,provinceName,None,confirmedCount,suspectedCount,curedCount,deadCount))
for i in cities:
con+=1
provinceName = item['provinceName']
cityName=i['cityName']
confirmedCount = i['confirmedCount']
suspectedCount = item['suspectedCount']
curedCount = i['curedCount']
deadCount = i['deadCount']
cityList.append((con,times,provinceName,cityName,confirmedCount,suspectedCount,curedCount,deadCount))
insert(provinceList,cityList) def insert(provinceList, cityList):
provinceTuple=tuple(provinceList)
cityTuple=tuple(cityList)
cursor = db.cursor()
sql = "insert into info_new values (%s,%s,%s,%s,%s,%s,%s,%s) "
try:
cursor.executemany(sql,provinceTuple)
print("插入成功")
db.commit()
except Exception as e:
print(e)
db.rollback()
try:
cursor.executemany(sql,cityTuple)
print("插入成功")
db.commit()
except Exception as e:
print(e)
db.rollback()
cursor.close()
def total():
sql= "select * from info_new"
cursor = db.cursor()
try:
cursor.execute(sql)
results = cursor.fetchall()
lenth = len(results)
db.commit()
return lenth
except:
print('执行失败,进入回调1')
db.rollback() # 连接数据库的方法
def connectDB():
try:
db = connect(host='localhost', port=3306, user='root', password='password', db='virus',charset='utf8')
print("数据库连接成功")
return db
except Exception as e:
print(e)
return NULL
if __name__ == '__main__':
db=connectDB()
mes()
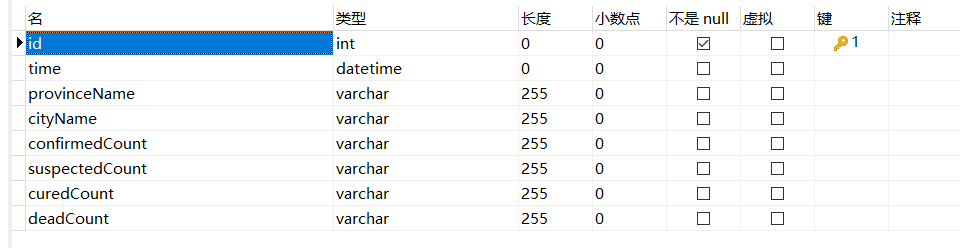
数据库结构:

python爬取疫情数据存入MySQL数据库的更多相关文章
- python爬取疫情数据详解
首先逐步分析每行代码的意思: 这是要引入的东西: from os import path import requests from bs4 import BeautifulSoup import js ...
- 利用Python爬取疫情数据并使用可视化工具展示
import requests, json from pyecharts.charts import Map, Page, Pie, Bar from pyecharts import options ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- 如何使用Python爬取基金数据,并可视化显示
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于Will的大食堂,作者打饭大叔 前言 美国疫情越来越严峻,大选也进入 ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- 使用selenium再次爬取疫情数据(链接数据库)
爬取网页地址: 丁香医生 数据库连接代码: def db_connect(): try: db=pymysql.connect('localhost','root','zzm666','payiqin ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- Python爬取房产数据,在地图上展现!
小伙伴,我又来了,这次我们写的是用python爬虫爬取乌鲁木齐的房产数据并展示在地图上,地图工具我用的是 BDP个人版-免费在线数据分析软件,数据可视化软件 ,这个可以导入csv或者excel数据. ...
随机推荐
- [TensorFlow2.0]-张量与常用函数
本人人工智能初学者,现在在学习TensorFlow2.0,对一些学习内容做一下笔记.笔记中,有些内容理解可能较为肤浅.有偏差等,各位在阅读时如有发现问题,请评论或者邮箱(右侧边栏有邮箱地址)提醒. 若 ...
- MySQL-20-MySQL优化
MySQL优化哲学 1 为什么优化? 为了获得成就感? 为了证实比系统设计者更懂数据库? 为了从优化成果来证实优化者更有价值? 但通常事实证实的结果往往会和你期待相反!优化有风险,涉足需谨慎! 2 优 ...
- DVWA-sql注入(盲注)
DVWA简介 DVWA(Damn Vulnerable Web Application)是一个用来进行安全脆弱性鉴定的PHP/MySQL Web应用,旨在为安全专业人员测试自己的专业技能和工具提供合法 ...
- Linux、Windows 下手动生成 sha256 等类型的校验文件
目录 1 - 校验文件的作用 2 - Linux 下生成校验文件 3 - Windows 下生成校验文件 参考资料 版权声明 1 - 校验文件的作用 从网服务器下载文件,尤其是比较大的文件时,很容易由 ...
- 理解SpingAOP
目录 什么是AOP? AOP术语 通知(Advice) 连接点(Join point) 切点(Pointcut) 连接点和切点的区别 切面(Aspect) 引入(Introduction) 织入(We ...
- NOIP 模拟 $21\; \rm Game$
题解 考试的时候遇到了这个题,没多想,直接打了优先队列,但没想到分差竟然不是绝对值,自闭了. 正解: 值域很小,所以我们开个桶,维护当前最大值. 如果新加入的值大于最大值,那么它肯定直接被下一个人选走 ...
- Docker创建seafile搭建私有云
docker-compose.yml version: '2.0' services: db: image: mariadb:10.1 container_name: seafile-mysql en ...
- 接口和包--Java学习笔记
接口 定义及基础用法 interface定义:没有字段的抽象类 interface person{ void hello(); String getName(); } /*接口本质上就是抽象类 abs ...
- css - 响应式
css - 响应式 移动设备尺寸 移动设备的尺寸各不相同,大体上可以做如下划分: 768px以下的是手机屏幕 768px-991px是平板ipad屏幕 992px-1199是大平板屏幕 1200极其以 ...
- grpc基础
RPC 框架原理 RPC 框架的目标就是让远程服务调用更加简单.透明,RPC 框架负责屏蔽底层的传输方式(TCP 或者 UDP).序列化方式(XML/Json/ 二进制)和通信细节.服务调用者可以像调 ...