MapReduce08 数据清洗(ETL)和压缩
数据清洗(ETL)
ETL(Extract抽取-Transform转换-Load加载)用来描述数据从来源端经过抽取、转换、加载至目的端的过程。一般用于数据仓库,但其对象并不限于数据仓库
在运行核心业务MapReduce程序之前,往往需要对数据进行清洗,清理掉不符合用户要求的数据,清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
ETL清洗案例
需求
去除日志中字段(通过空格切割)个数小于等于11的日志
输入数据D:\hadoop\hadoop_data\inputlog
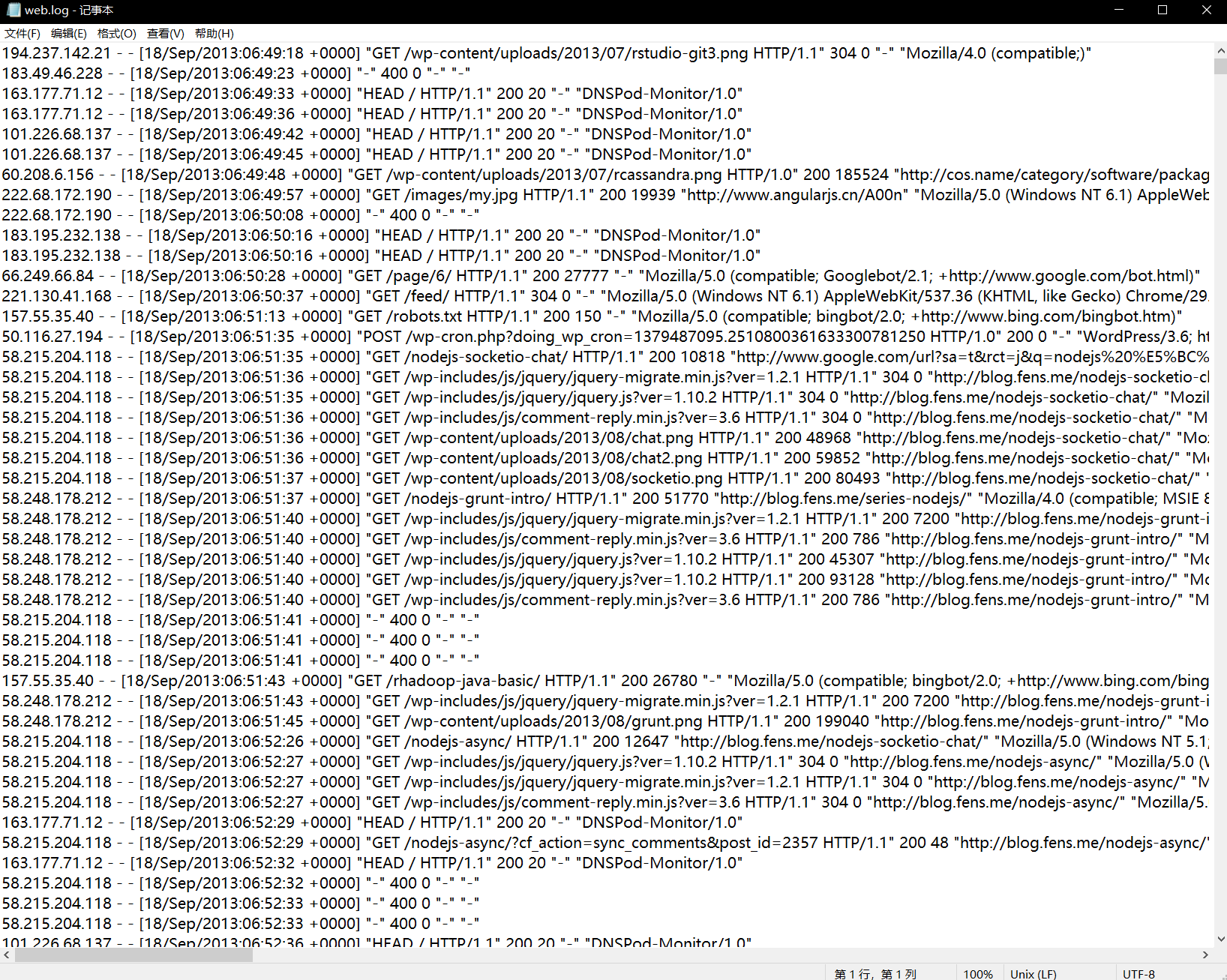
期望输出数据:每行字段长度都大于11
需求分析
需要在Map阶段对输入的数据根据规则进行过滤清洗。
实现代码
编写WebLogMapper类
package com.ranan.mapreduce.etl;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author ranan
* @create 2021-09-03 10:39
*/
class WebLogMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.获取一行
String line = value.toString();
//2.ETL 符合条件就写出到上下文,不符合条件就直接判断下一行
boolean result = parseLog(line,context);
if (!result){
return;
}
//3.写出
context.write(value,NullWritable.get());
}
private boolean parseLog(String line, Context context) {
String[] fields = line.split(" ");
if(fields.length >11){
return true;
}
return false;
}
}
编写WebLogDriver类
package com.ranan.mapreduce.etl;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author ranan
* @create 2021-09-03 10:47
*/
public class WebLogDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WebLogDriver.class);
job.setMapperClass(WebLogMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
//通过命令行控制,方便上次打包到集群运行
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
打包到集群运行
压缩
概念
压缩的优点:以减少磁盘IO、减少磁盘存储空间。
压缩的缺点:增加CPU开销。
压缩原则
1.运算密集型的Job,少用压缩
2.IO密集型的Job,多用压缩
MR支持的压缩编码
压缩算法对比
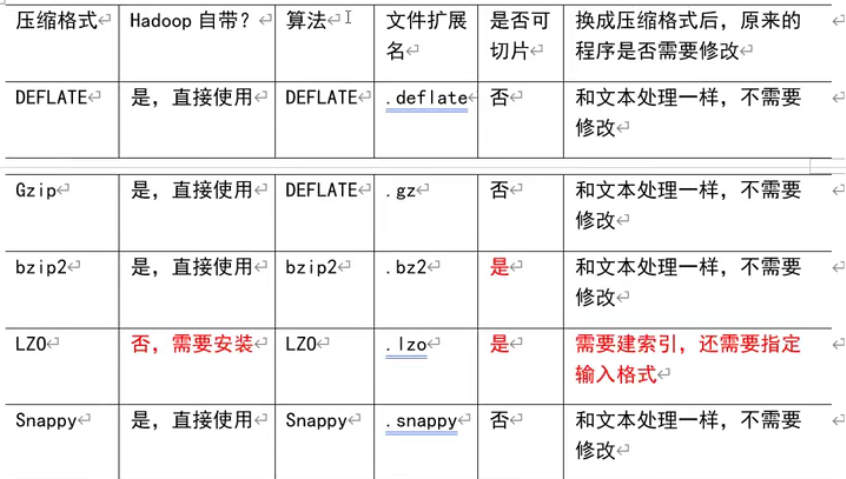
压缩性能比较
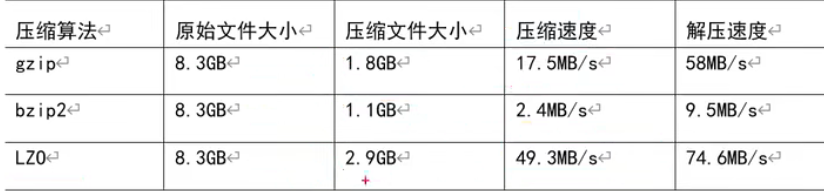
压缩方式选择
压缩方式选择器时需要考虑:压缩/解压缩速度、压缩后的大小、压缩后是否可以支持切片。
| 类型 | 优点 | 缺点 |
|---|---|---|
| Gzip | 压缩率比较高 | 不支持切片;压缩/解压速度一般 |
| Bzip2 | 压缩率高;支持切片 | 压缩/解压速度慢 |
| Lzo | 压缩/解压速度比较块;支持切片 | 压缩率一般;支持切片需要额外创建索引 |
| Snappy | 压缩/解压速度块 | 不支持切片;压缩率一般 |
压缩位置选择
压缩可以再MapReduce作用的任意阶段启用。

压缩参数配置
1.为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器。
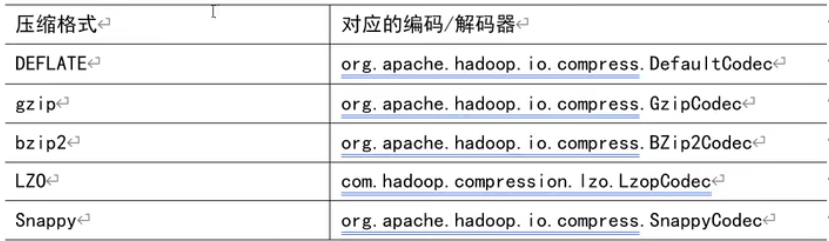
2.要在Hadoop中启用压缩,可以配置如下参数
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs(在core-site.xml中配置) | 无,这个需要在命令行输入hadoopchecknative查看 | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress(在mapred-site.xml中配置) | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 企业多使用LZO或Snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置) | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
hadoop checknative 查看默认支持的压缩方式
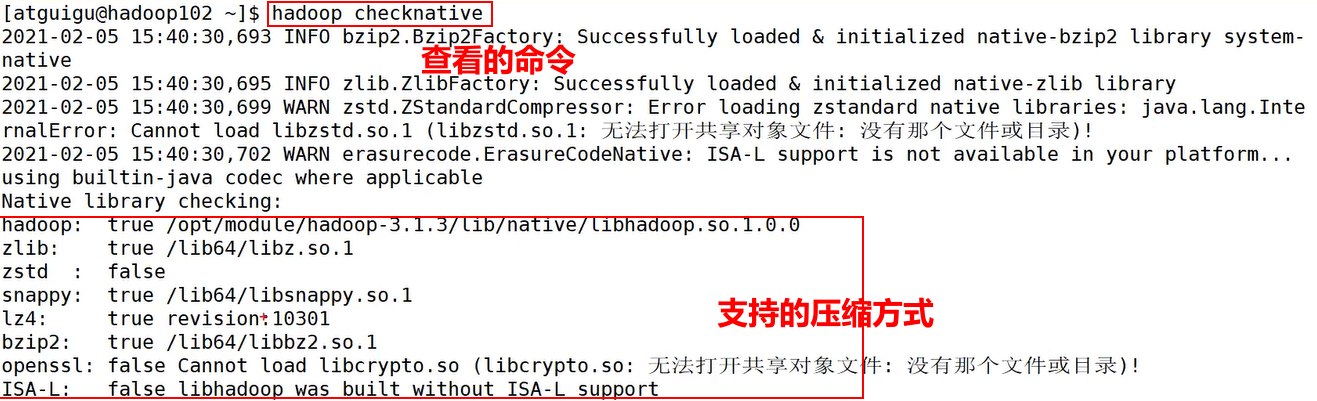
注意:snappy和hadoop的版本需要配对才能适用。
压缩案例实操
Map输出端采用压缩
即使MapReduce的输入输出文件都是未压缩的文件,仍然可以对Map任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到Reduce节点,对其压缩可以提高很多性能,这些工作只要设置两个属性即可,我们来看下代码怎么设置。
Driver类
这里用WordCount案例,其余部分保持不变,只修改Driver类。
Map输出压缩文件,Reduce端解压,最终输出的文件格式不变。
//本机Hadoop版本支持的压缩格式有BZip2Codec、DefaultCodec
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException,ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//开启map端输出压缩
conf.setBoolean("mapreduce.map.output.compress", true);
//设置map端输出压缩方式
conf.setClass("mapreduce.map.output.compress.codec",BZip2Codec.class,CompressionCodec.class);
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WoradCountMapper.class);job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
Reduce输出端采用压缩
Driver类
//设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
//设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
//FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
//FileOutputFormat.setOutputCompressorClass(job,DefaultCodec.class);
MapReduce08 数据清洗(ETL)和压缩的更多相关文章
- 【电商日志项目之四】数据清洗-ETL
环境 hadoop-2.6.5 首先要知道为什么要做数据清洗?通过各个渠道收集到的数据并不能直接用于下一步的分析,所以需要对这些数据进行缺失值清洗.格式内容清洗.逻辑错误清洗.非需求数据清洗.关联性验 ...
- 建模前的数据清洗/ETL(python)
1. 读取数据 data= open('e:/java_ws/scalademo/data/sample_naive_bayes_data.txt' , 'r') 2. 把数据随机分割为trainin ...
- 日志数据如何同步到MaxCompute
摘要:日常工作中,企业需要将通过ECS.容器.移动端.开源软件.网站服务.JS等接入的实时日志数据进行应用开发.包括对日志实时查询与分析.采集与消费.数据清洗与流计算.数据仓库对接等场景.本次分享主要 ...
- Hawk 2. 软件界面介绍
2. 软件界面介绍 1. 基本组件 Hawk采用类似Visual Studio和Eclipse的Dock风格,所有的组件都可以悬停和切换.包括以下核心组件: 左上角区域:主要工作区,任务管理. 下方: ...
- Hawk 1.1 快速入门(链家二手房)
链家的同学请原谅我,但你们的网站做的真是不错. 1. 设计网页采集器 我们以爬取链家二手房为例,介绍网页采集器的使用.首先双击图标,加载采集器: 在最上方的地址栏中,输入要采集的目标网址,本次是htt ...
- 【重磅开源】Hawk-数据抓取工具:简明教程
Hawk-数据抓取工具:简明教程 标签(空格分隔): Hawk Hawk: Advanced Crawler& ETL tool written in C#/WPF 1.软件介绍 HAWK是一 ...
- 【开源】Hawk-数据抓取工具:简明教程
1.软件介绍 HAWK是一种数据采集和清洗工具,依据GPL协议开源,能够灵活,有效地采集来自网页,数据库,文件, 并通过可视化地拖拽, 快速地进行生成,过滤,转换等操作.其功能最适合的领域,是爬虫和数 ...
- Hawk-数据抓取工具
Hawk-数据抓取工具:简明教程 Hawk: Advanced Crawler& ETL tool written in C#/WPF 1.软件介绍 HAWK是一种数据采集和清洗工具,依据 ...
- 【转】Spark实现行列转换pivot和unpivot
背景 做过数据清洗ETL工作的都知道,行列转换是一个常见的数据整理需求.在不同的编程语言中有不同的实现方法,比如SQL中使用case+group,或者Power BI的M语言中用拖放组件实现.今天正好 ...
随机推荐
- spring cloud Alibaba --sentinel组件的使用
sentinel组件 对于sentinel的前置知识这里就不多说了: 直接上代码: Release v1.8.1 · alibaba/Sentinel · GitHub 下载地址 springclo ...
- 百亿级小文件存储,JuiceFS 在自动驾驶行业的最佳实践
自动驾驶是最近几年的热门领域,专注于自动驾驶技术的创业公司.新造车企业.传统车厂都在这个领域投入了大量的资源,推动着 L4.L5 级别自动驾驶体验能尽早进入我们的日常生活. 自动驾驶技术实现的核心环节 ...
- swoole、swoft环境配置
一.服务器环境 1.lnmp wget http://soft.vpser.net/lnmp/lnmp1.5.tar.gz -cO lnmp1.5.tar.gz && tar zxf ...
- “TCP:三次握手”分析——以一个简单的“服务器”和“客户端”为例
linux&C这两天学到了网络编程这一章,自己写了一个小的"服务器"和"客户端"程序,目的在于简单理解tcp/ip模型,以及要搭建一台简单服务器,服务器 ...
- 『学了就忘』Linux基础命令 — 30、find命令详细说明
目录 1.find命令的基本信息 2.find命令基本使用 3.按照文件大小搜索 4.按照修改时间搜索 5.按照权限搜索 6.按照所有者和所属组搜索 7.按照文件类型搜索 8.逻辑运算符 (1)-a: ...
- PTA 列车调度 (25分)
PTA 列车调度 (25分) [程序实现] #include<bits/stdc++.h> using namespace std; int main(){ int num,n; cin& ...
- LeetCode 114. 二叉树展开为链表 C++
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode ...
- Java学习(十五)
下棋又被暴打 所以心态有点爆炸,学完习又去打云顶,忘记写博客了... 所以今天也有点水了,这下棋真是搞崩我心态了. Java学了函数重载 大概的要点在这 还有Web的学习,否定伪类. 如 p:not( ...
- 【死磕 NIO】— 深入分析Buffer
大家好,我是大明哥,今天我们来看看 Buffer. 上面几篇文章详细介绍了 IO 相关的一些基本概念,如阻塞.非阻塞.同步.异步的区别,Reactor 模式.Proactor 模式.以下是这几篇文章的 ...
- Python 中的反转字符串:reversed()、切片等
摘要:以相反的顺序反转和处理字符串可能是编程中的一项常见任务.Python 提供了一组工具和技术,可以帮助您快速有效地执行字符串反转. 本文分享自华为云社区<Python 中的反转字符串:rev ...