Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理
Scrapy框架架构图
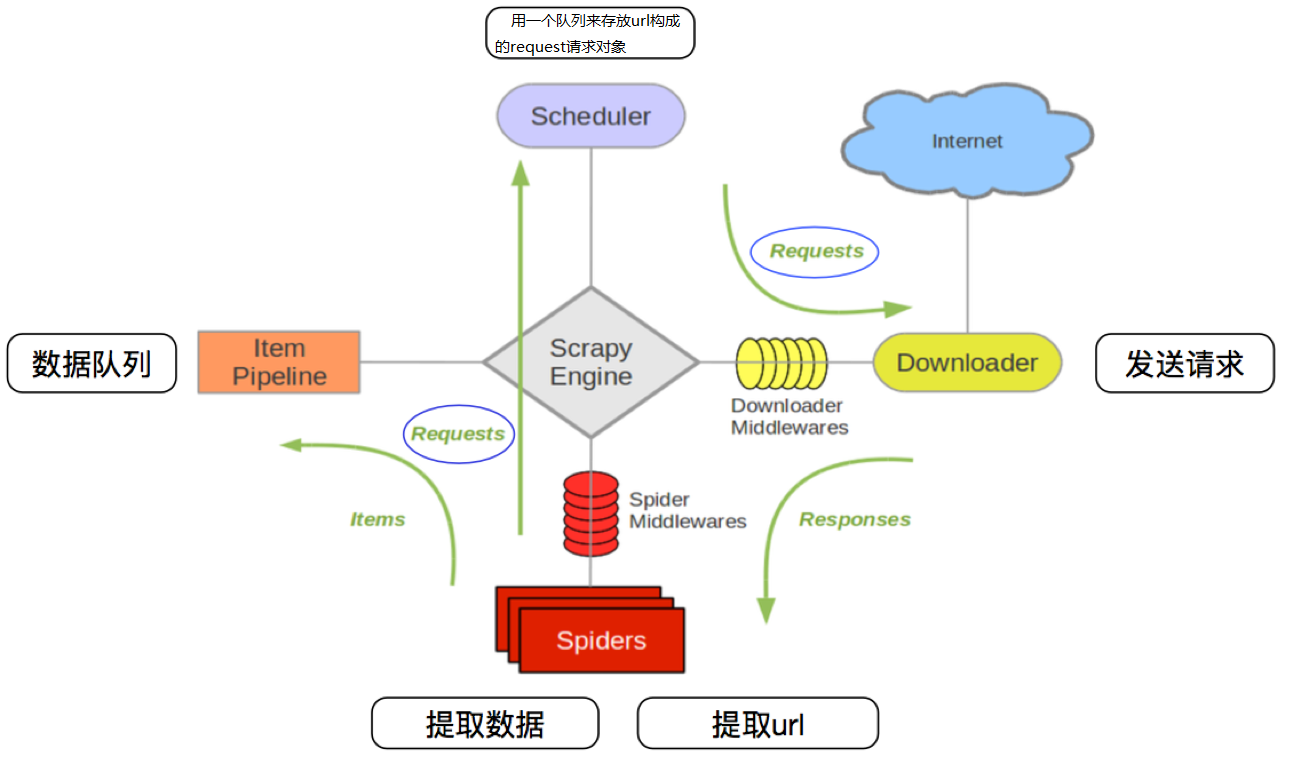
Scrapy框架主要由六大组件组成,分别为:
调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwares),管道(Item Pipeline)和Scrapy引擎(Scrapy Engine)
Scarpy框架模块功能
1. Schedule(调度器):调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引
2. Downloader(下载器):下载器负责获取页面数据并提供给引擎,而后提供给spider
3. Spiders(爬虫):Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站
4. Item Pipeline(管道):Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存储到数据库中)
5. Scrapy Engine(引擎):引擎负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发事
6. Downloader Middwares(下载中间件):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能
7. Spiders Middwares(爬虫中间件):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能
Scrapy工作流程
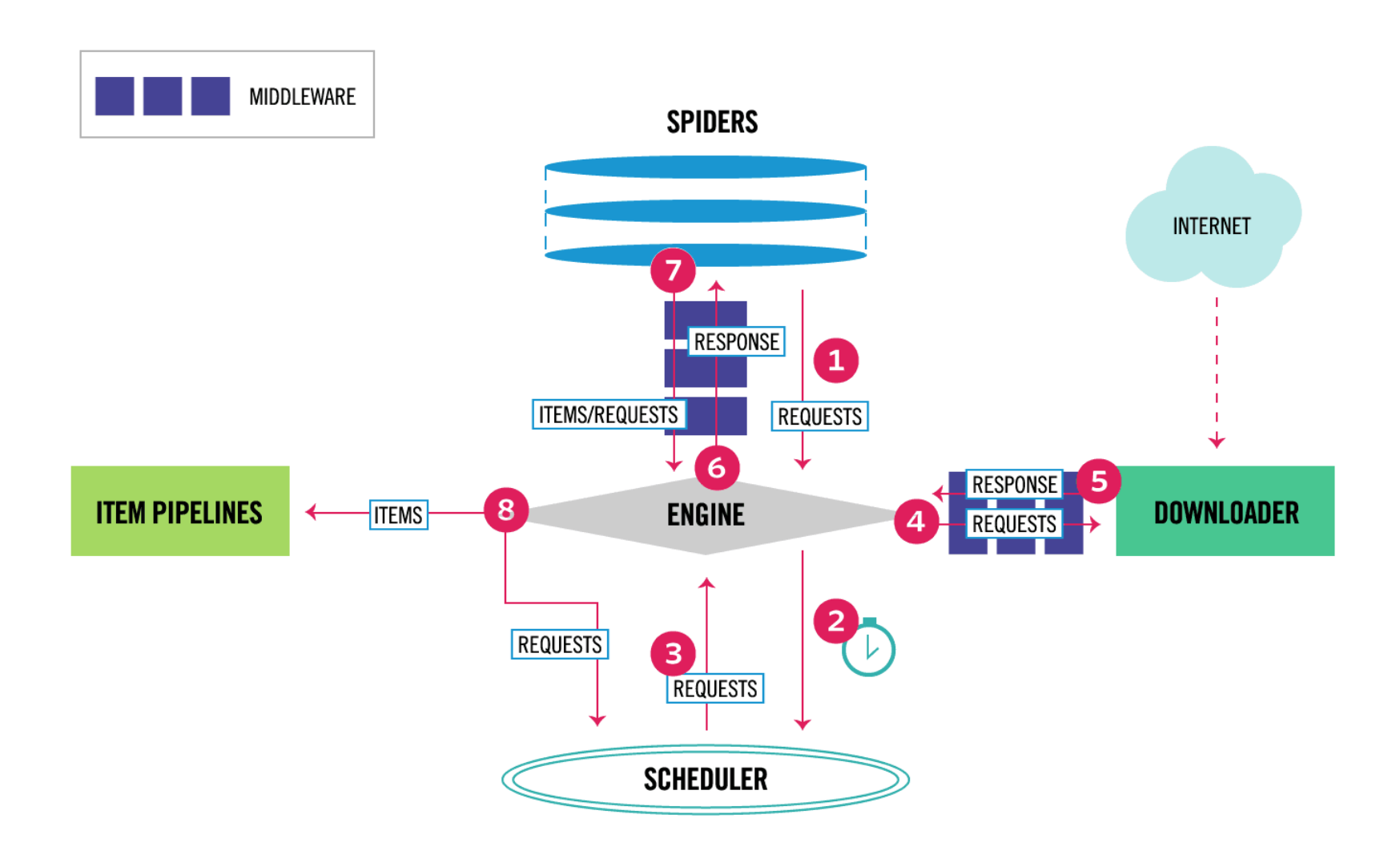
1. 当爬虫(Spider)要爬取某URL地址的页面时,使用该URL初始化Request对象提交给引擎(Scrapy Engine),并设置回调函数。 Spider中初始的Request是通过调用start_requests() 来获取的。start_requests() 读取start_urls 中的URL,并以parse为回调函数生成Request 。
2. Request对象进入调度器(Scheduler)按某种算法进行排队,之后的每个时刻调度器将其出列,送往下载器。
3. 下载器(Downloader)根据Request对象中的URL地址发送一次HTTP请求到网络服务器把资源下载下来,并封装成应答包(Response)。
4. 应答包Response对象最终会被递送给爬虫(Spider)的页面解析函数进行处理。
5. 若是解析出实体(Item),则交给实体管道(Item Pipeline)进行进一步的处理。由Spider返回的Item将被存到数据库(由某些Item Pipeline处理)或使用Feed exports存入到文件中。
6. 若是解析出的是链接(URL),则把URL交给调度器(Scheduler)等待抓取。以上就是Scrapy框架的运行流程,也就是它的工作原理。Request和Response对象是血液,Item是代谢产物。
Python爬虫-Scrapy框架的工作原理的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- python爬虫----scrapy框架简介和基础应用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
随机推荐
- fiddler 手机抓包(含https) 完整流程
第一部分:下载并安装fiddler 一.使用任一浏览器搜索[fiddler下载安装],并下载fiddler 安装包. 二.fiddler安装包下载成功后,将下载的fiddler压缩包解压到自定义文件夹 ...
- 小程序使用 Promise.all 完成文件异步上传
小程序使用 Promise.all 完成文件异步上传 extends [微信小程序开发技巧总结(二) -- 文件的选取.移动.上传和下载 - Kindear - 博客园 (cnblogs.com)] ...
- kubectl cp 从k8s pod 中 拷贝 文件到本地
请查看官方的说明 kubectl cp --help 官方说使用cp , pod里需要有tar命令 从k8s pod 中 拷贝 文件到本地 这是我使用的命令 kubectl exec redis-6c ...
- kubernetes集群证书更新
kubeadm 默认证书为一年,一年过期后,会导致api service不可用,使用过程中会出现:x509: certificate has expired or is not yet valid. ...
- 【Java集合】JDK1.7和1.8 HashMap有什么区别
JDK1.7和1.8 HashMap区别: 1.数组+链表改成了数组+链表或红黑树: 2.表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节 ...
- 【SpringBoot】Springboot1.5.9整合WebSocket
一.WebSocket介绍 1.WebSocket是什么? WebSocket是协议,是HTML5开始提供的基于TCP(传输层)的一种新的网络协议, 它实现了浏览器与服务器全双工(full-duple ...
- DVWA之Insecure Captcha
Insecure CAPTCHA Insecure CAPTCHA,意思是不安全的验证码,CAPTCHA是Completely Automated Public Turing Test to Tell ...
- SVCHOST启动服务实战
本文转载自:https://blog.csdn.net/huanglong8/article/details/70666987 转载出处: https://sanwen8.cn/p/2cenbHs.h ...
- C#-WiFi共享
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- Docker简单流程