brk 和 sbrk 区别
转自:https://www.cnblogs.com/chengxuyuancc/p/3566710.html
brk和sbrk的定义,在man手册中定义了这两个函数:
1 #include <unistd.h>
2 int brk(void *addr);
3 void *sbrk(intptr_t increment);
手册上说brk和sbrk会改变program break的位置,program break被定义为程序data segment的结束位置。感觉这句话不是很好理解,从下面程序地址空间的分布来看,data segment后面还有bss segment,显然和手册说的不太一样。一种可能的解释就是手册中的data segment和下图中的data segment不是一个意思,手册中的data segment应该包含了下图中的data segment、bss segment和heap,所以program break指的就是下图中heap的结束地址。
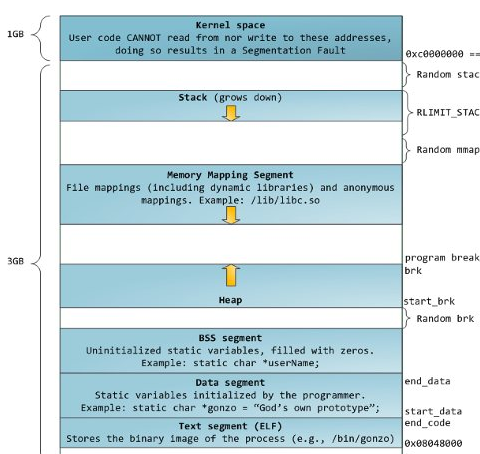
有了前面program break的概念后,我们来看下brk和sbrk的作用。brk通过传递的addr来重新设置program break,成功则返回0,否则返回-1。而sbrk用来增加heap,增加的大小通过参数increment决定,返回增加大小前的heap的program break,如果increment为0则返回program break。
从上面的图可以看出heap的起始地址并不是bss segment的结束地址,而是随机分配的,下面我们用一个程序来验证下:

1 #include <stdio.h>
2 #include <unistd.h>
3
4 int bss_end;
5
6 int main(void)
7 {
8 void *tret;
9
10 printf("bss end: %p\n", (char *)(&bss_end) + 4);
11 tret = sbrk(0);
12 if (tret != (void *)-1)
13 printf ("heap start: %p\n", tret);
14 return 0;
15 }
运行的结果为:
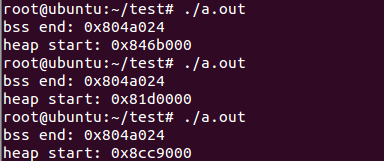
从上面运行结果可以知道bss和heap是不相邻的,并且同一个程序bss的结束地址是固定的,而heap的起始地址在每次运行的时候都会改变。你可能会说sbkr(0)返回的是heap的结束地址,怎么上面确把它当做起始地址呢?由于程序开始运行时heap的大小是为0,所以起始地址和结束地址是一样的,不信我们可以用下面的程序验证下。
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <stdlib.h>
4
5 int bss_end;
6
7 int main(void)
8 {
9 void *tret;
10 char *pmem;
11
12 printf("bss end: %p\n", (char *)(&bss_end) + 4);
13 tret = sbrk(0);
14 if (tret != (void *)-1)
15 printf ("heap1 start: %p\n", tret);
16
17 if (brk((char *)tret - 1) == -1)
18 printf("brk error\n");
19
20 tret = sbrk(0);
21 if (tret != (void *)-1)
22 printf ("heap2 start: %p\n", tret);
23
24 pmem = (char *)malloc(32);
25 if (pmem == NULL) {
26 perror("malloc");
27 exit (EXIT_FAILURE);
28 }
29 printf ("pmem:%p\n", pmem);
30
31 tret = sbrk(0);
32 if (tret != (void *)-1)
33 printf ("heap1 end: %p\n", tret);
34
35 if (brk((char *)tret - 10) == -1)
36 printf("brk error\n");
37
38 tret = sbrk(0);
39 if (tret != (void *)-1)
40 printf ("heap2 end: %p\n", tret);
41 return 0;
42 }
运行结果为:
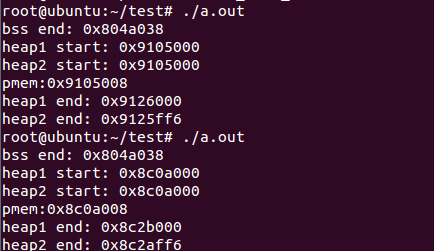
程序开始的时候打印出来heap的结束地址,并用这个地址减1来重新设置heap的结束地址,结果两次的结束地址居然是一样的,那说明这个结束地址就是heap的起始地址,再减小这个起始地址是不允许的,不过brk也不会报错。然后调用malloc获取内存,并打印出该内存的起始地址pmem,可以发现pmem与heap的起始地址相差8个字节,为什么会有8个字节没有?这8个字节应该是用来管理heap空间的(不深究)。最后再次获得heap的结束地址,并用这个地址减10来重新设置heap的结束地址,这下地址设置成功了。
堆的管理
上面的函数我们其实很少使用,大部分我们使用的是malloc和free函数来分配和释放内存。这样能够提高程序的性能,不是每次分配内存都调用brk或sbrk,而是重用前面空闲的内存空间。brk和sbrk分配的堆空间类似于缓冲池,每次malloc从缓冲池获得内存,如果缓冲池不够了,再调用brk或sbrk扩充缓冲池,直到达到缓冲池大小的上限,free则将应用程序使用的内存空间归还给缓冲池。
如果缓冲池需要扩充时,一次扩充多少呢?先运行下面的程序看看:
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <stdlib.h>
4
5 int main(void)
6 {
7 void *tret;
8 char *pmem;
9
10 tret = sbrk(0);
11 if (tret != (void *)-1)
12 printf ("heap start: %p\n", tret);
13
14 pmem = (char *)malloc(64); //分配内存
15 if (pmem == NULL) {
16 perror("malloc");
17 exit (EXIT_FAILURE);
18 }
19 printf ("pmem:%p\n", pmem);
20 tret = sbrk(0);
21 if (tret != (void *)-1)
22 printf ("heap size on each load: %p\n", (char *)tret - pmem);
23 free(pmem)
24 return 0;
25 }
运行结果如下:

从结果可以看出调用malloc(64)后缓冲池大小从0变成了0x20ff8,将上面的malloc(64)改成malloc(1)结果也是一样,只要malloc分配的内存数量不超过0x20ff8,缓冲池都是默认扩充0x20ff8大小。值得注意的是如果malloc一次分配的内存超过了0x20ff8,malloc不再从堆中分配空间,而是使用mmap()这个系统调用从映射区寻找可用的内存空间。
参考
http://blog.csdn.net/sgbfblog/article/details/7772153
brk 和 sbrk 区别的更多相关文章
- Linux中brk()系统调用,sbrk(),mmap(),malloc(),calloc()的异同【转】
转自:http://blog.csdn.net/kobbee9/article/details/7397010 brk和sbrk主要的工作是实现虚拟内存到内存的映射.在GNUC中,内存分配是这样的: ...
- 理解brk和sbrk
brk和sbrk的定义 在man手册中定义了这两个函数: #include <unistd.h> int brk(void *addr); void *sbrk(intptr_t incr ...
- Unix系统编程()brk,sbrk
在堆上分配内存 进程可以通过增加堆的大小来分配内存,所谓堆是一段长度可变的连续虚拟内存,始于进程的未初始化数据段末尾,随着内存的分配和释放而增减.通常将堆的当前内存边界称为"program ...
- brk(), sbrk() 用法详解
brk() , sbrk() 的声明如下: #include <unistd.h> int brk(void *addr); void *sbrk(intptr_t increment); ...
- brk(), sbrk() 用法详解【转】
转自:http://blog.csdn.net/sgbfblog/article/details/7772153 贴上原文地址,好不容易找到了:brk(), sbrk() -- 改变数据段长度 brk ...
- 系统调用与内存管理(sbrk、brk、mmap、munmap)(转)
一.系统调用(System Call):在Linux中,4G内存可分为两部分——内核空间1G(3~4G)与用户空间3G(0~3G),我们通常写的C代码都是在对用户空间即0~3G的内存进行操作.而且,用 ...
- Linux内存分配小结--malloc、brk、mmap【转】
转自:https://blog.csdn.net/gfgdsg/article/details/42709943 http://blog.163.com/xychenbaihu@yeah/blog/s ...
- brk和mmap(转)
进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap: 1.brk是将数据段的(.data)的最高地址指针_edata往高地址推 2.mmap是虚拟地址空间找一个空闲的虚拟内存 如果mal ...
- C/C++ Learning
目录 1. C/C++中的关键字2. C/C++中的标识符3. 编译选项MD(d).MT(d)编译选项的区别4. C++类模板.函数模板5. C++修饰符6. 调用约定7. 错误处理8. 环境表 9. ...
随机推荐
- day19.进程通信与线程1
1 进程Queue介绍 1 进程间数据隔离,两个进程进行通信,借助于Queue 2 进程间通信:IPC -借助于Queue实现进程间通信 -借助于文件 -借助于数据库 -借助于消息队列:rabbitm ...
- 2021 DevOpsDays 东京站完美收官 | CODING 专家受邀分享最新技术资讯
DevOpsDays 是一个全球知名的系列技术会议品牌,内容涵盖了软件开发.自动化.测试.安全.组织文化以及 IT 运营的社区会议等.DevOpsDays 由 DevOps 之父 Patrick De ...
- Dropping Balls UVA - 679
A number of K balls are dropped one by one from the root of a fully binary tree structure FBT. Eac ...
- Ducci Sequence UVA - 1594
A Ducci sequence is a sequence of n-tuples of integers. Given an n-tuple of integers (a1,a2,···,an ...
- 二. 简单初步认识SpringCloud
(一)微服务的实现方式很多,但是最火的莫过于Spring Cloud了.为什么? 后台硬:作为Spring家族的一员,有整个Spring全家桶靠山,背景十分强大. 技术强:Spring作为Java领域 ...
- 04- cookie与缓存技术
什么是cookie 定义:Cookies是一种能够让网站服务器把少量数据储存到客户端的硬盘或内存,或是从客户端的硬盘读取数据的一种技术.Cookies是当你浏览某网站时,由Web服务器置于你硬盘上的一 ...
- 【SpringBoot】SpringBoot集成jasypt数据库密码加密
一.为什么要使用jasypt库? 目前springboot单体应用项目中,甚至没有使用外部配置中心的多服务的微服务架构的项目,开发/测试/生产环境中的密码往往是明文配置在yml或properties文 ...
- 针对中国政府机构的准APT攻击样本Power Shell的ShellCode分析
本文链接网址:http://blog.csdn.net/qq1084283172/article/details/45690529 一.事件回放 网络管理员在服务器上通过网络监控软件检测到,有程序在不 ...
- Python的套接字、IPv4和简单的客户端/服务器编程
#!/usr/bin/env python # -*- coding: utf-8 -*- import socket from binascii import hexlify import sys ...
- POJ1722二维spfa+优先队列优化
题意: 给你一个有向图,然后求从起点到终点的最短,但是还有一个限制,就是总花费不能超过k,也就是说每条边上有两个权值,一个是长度,一个是花费,求满足花费的最短长度. 思路: 一开 ...