MySQL实战优化之InnoDB整体架构
一、InnoDB 更新数据得整体架构
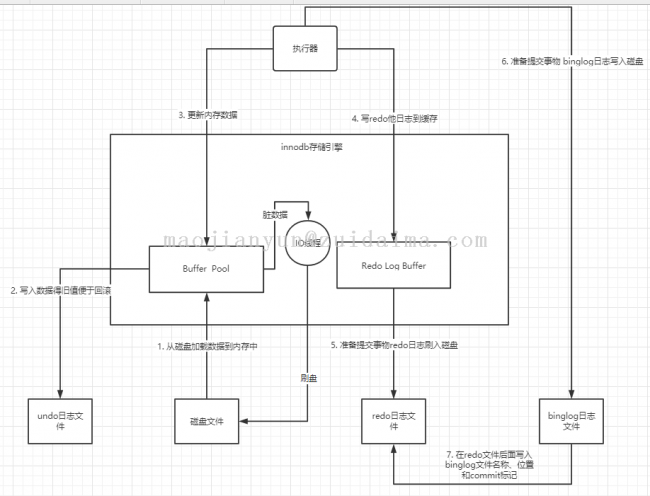
每个组件的作用说明:
用一条更新数据来说明每个主键得作用:
update student set name = 'zhangsan' where id = 10
1. innodb得重要内存接口:缓冲池(Buffer Pool)
innodb存储引擎中有一个重要得放在内存中得组件,就是缓冲池(Buffer Pool),这里面会缓存很多得数据,以便于以后查询数据得时候,如果在内存缓冲中有数据,就可以直接从内存返回不需要查询磁盘加载到内存缓冲中。
如果InnoDB存储引擎需要执行一条更新语句得时候,比如上面那条数 id = 10 这条数据时候,首先会在缓冲中是否存在 id = 10 这条数据,如果不存在就直接从磁盘中把该条数据加载到缓冲里来,而且会对这条数据加独占锁。
2. undo 日志文件:保证更新后的数据可以回滚
假设 id = 10 这行数据的name原来是 zhangsan, 现在需要更新为 lisi,那么此时需要先把更新的原来的值 name = 'zhangsan' 和 id = 10 这些信息,写入到undo日志文件中,如果在后面的操作出现异常,需要做回滚数据就会从undo日志文件中加载回滚。
3. 更新Buffer Pool中的缓冲数据
当我们把要更新的那行数据从磁盘文件加载到缓冲池,同时对该行数据枷锁后把更新前的旧值写入到undo日志文件之后,旧可以正式开始更新这行记录了,先更新缓冲池中的记录,此时这行数据是脏数据。因为磁盘上的依旧是 name 的值是zhangsan,内存中的已经是lisi所以说是脏数据。
4. Redo Log buffer:防止Mysql服务宕机后,保证数据不被丢失。
在buffer pool 中修改了数据后,我们必须把对内存所作的修改写入到一个Redo Log Buffer的内存缓冲区中,这个缓冲区是用于存放redo日志的。所谓的redo日志,就是记录下来对数据做了什么修改,比如对 id = 10 这行记录修改了name字段的值为lisi,这就是一条日志。
在提交事物的时候会将redo日志写入到磁盘中(顺序写入),有一下集中方式写入:
innodb_flush_log_at_trx_commit = 1:不写入磁盘
innodb_flush_log_at_trx_commit = 2:提交事务的时候刷盘
innodb_flush_log_at_trx_commit = 3:写入系统的os再定时刷入磁盘
一般使用的是第二种。
5. binglong日志
binglog日志是mysql server 服务的日志,叫做归档日志,他里面记录的是逻辑行的日志,类似于 对 srtudent 表中的 id = 10 这行数据做了更新操作,更新后的值是什么。
在提交事务的时候需要binglog日志写入到磁盘中,写入的策略如下:
sync_binglog = 0:提交事务时写入系统缓冲在定时刷入磁盘
sync_binglog = 1:提交事务时写入磁盘。
总结innodb存储引擎做一次跟新的架构原理:
大家通过一次更新数据的流程,就可以清晰地看到,InnoDB存储引擎主要就是包含了一些buffer pool redo log buffer等内存里的缓存数据,同时还包含了一些undo日志文件,redo日志文件等东西,同时mysqlserver自己还有binlog日志文件
在你执行更新的时候,每条SQL语句,都会对应修改buffer pool里的缓存数据、写undo日志、写redo log buffer几个步骤
但是当你提交事务的时候,一定会把redolog刷入磁盘,binloq刷入磁盘,完成redolog中的事务commit标记;最后后台的1O线程会随机的把buffer pool里的脏数据刷入磁盘里去
面试题:
1. 执行更新操作的时候,为什么不精细修改磁盘上的数据?
2. 如果保证msyql服务宕机后数据更新后的数据不丢失?
MySQL实战优化之InnoDB整体架构的更多相关文章
- mysql实战优化之七:数据库侧配置优化
对于功能,我们可能知道必须改进什么:但对于性能问题,有时我们可能无从下手.其实,任何计算机应用系统最终队可以归结为: cpu消耗 内存使用 对磁盘,网络或其他I/O设备的输入/输出(I/O)操作. 但 ...
- (1.3)学习笔记之mysql体系结构(C/S整体架构、内存结构、物理存储结构、逻辑结构)
目录 1.学习笔记之mysql体系结构(C/S架构) 2.mysql整体架构 3.存储引擎 4.sql语句处理--SQL层(内存层) 5.服务器内存结构 6.mysql如何使用磁盘空间 7.mysql ...
- mysql实战优化之一:sql优化
1.选取最适用的字段属性 MySQL 可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得 ...
- mysql实战优化之八:关联查询优化
1. 多表连接类型 1. 笛卡尔积(交叉连接) 在MySQL中可以为CROSS JOIN或者省略CROSS即JOIN,或者使用',' 如: 由于其返回的结果为被连接的两个数据表的乘积,因此当有WHE ...
- MySQL配置文件优化(Innodb)
Innodb配置文件参数调优 ——MySQL建议采用MySQL 5.6 InnoDB存储引擎 1.内存利用方面: innodb_buffer_pool_size ☆☆☆☆☆ Innodb优化首要参数. ...
- mysql实战优化之三:表优化
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈.所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问. 如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理 ...
- mysql实战优化之六:Order by优化 sql优化、索引优化
在MySQL中的ORDER BY有两种排序实现方式: 1.利用有序索引获取有序数据 2.文件排序 在使用explain分析查询的时候,利用有序索引获取有序数据显示Using index.而文件排序显示 ...
- mysql实战优化之二:limit优化(大表翻页查询时) sql优化
mysql的表test中有20105119行数据.建立索引:data_status,place_cargo_status 场景1: SELECT id, resource_id, resource_t ...
- mysql实战优化之四:mysql索引优化
0. 使用SQL提示 用户可以使用use index.ignore index.force index等SQL提示来进行选择SQL的执行计划. 1.支持多种过滤条件 2.避免多个范围条件 应尽量避免在 ...
随机推荐
- 在Jupyter Notebook添加代码自动补全功能
在使用Jupyter notebook时发现没有代码补全功能,于是在网上查找了一些资料,最后总结了以下内容. 1 安装显示目录功能: pip install jupyter_contrib_nbext ...
- HTML基本概念及基本标签
HTML基本概念及基本语法 1.HTML的基本概念 1.1 B/S.C/S基本概念 B/S(Browser/Server):指的是浏览器端与服务器端工作模式,优点相对节省本地存储空间,不足是需要占用 ...
- javascript 标签切换
* index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&q ...
- php-抽象工厂
目标:创建有依赖关系的实例;(套餐) <?php //抽象类 食物 interface IAllayFood { function Allay(); } interface IDrinkFood ...
- python学习笔记(十三)-python对Excel进行读写修改操作
日常工作中会遇到Excel的读写问题.我们可以使用xlwt 模块将数据写入Excel表格,使用xlrd 模块从Excel读取数据,使用xlutils模块和xlrd模块结合对Excel数据进行修改.下面 ...
- 鸿蒙内核源码分析(静态链接篇) | 完整小项目看透静态链接过程 | 百篇博客分析OpenHarmony源码 | v54.01
百篇博客系列篇.本篇为: v54.xx 鸿蒙内核源码分析(静态链接篇) | 完整小项目看透静态链接过程 | 51.c.h.o 下图是一个可执行文件编译,链接的过程. 本篇将通过一个完整的小工程来阐述E ...
- 鸿蒙内核源码分析(时钟任务篇) | 触发调度谁的贡献最大 | 百篇博客分析OpenHarmony源码 | v3.05
百篇博客系列篇.本篇为: v03.xx 鸿蒙内核源码分析(时钟任务篇) | 触发调度谁的贡献最大 | 51.c.h .o 任务管理相关篇为: v03.xx 鸿蒙内核源码分析(时钟任务篇) | 触发调度 ...
- P6640-[BJOI2020]封印【SAM,二分】
正题 题目链接:https://www.luogu.com.cn/problem/P6640 题目大意 给出两个字符串\(s,t\).\(q\)次给出\(l,r\)询问\(s_{l\sim r}\)与 ...
- 实践node.js构建vue项目
一.首先安装下载node.js 1.Node.js 官方网站下载:https://nodejs.org/en/,自行选择合适自己的下载安装即可 2.验证安装 打开cmd,输入node –v和 npm ...
- nvidia jetson xavier 风扇开机自启动
作者声明 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 原文链接:https://www.cnblogs.com/phoenixash/p/15 ...