pipeline是什么?
一.pipeline是什么?
pipeline是部署流水线(Deployment pipeline),指从软件版本控制库到用户手中这一过程的自动化表现形式。
Jenkins 1.x只能通过界面手动配置来配置描述过程,让Jenkins完成任务,例如选择自由风格的项目,通过选项等操作进行配置,让jenkins可以下载代码、编译构建、然后部署到远程服务器上。

而Jenkins 2.x终于支持pipeline as code了,可以通过代码来描述部署流水线,还是同样的功能,部分操作通过代码配置运行后,也会在界面里显示出来。
Pipeline 简而言之,就是一套运行于Jenkins上的工作流框架,将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排与可视化。

pipeline的功能由pipeline插件提供,有的jenkins会自带,若没有则需要安装。
使用代码而不是UI的意义在于:
- 更好的版本化:将pipeline提交到版本库中进行版本控制
- 更好地协作:pipeline的每次修改对所有人都是可见的。除此之外,还可以对pipeline进行代码审查
- 更好的重用性:手动操作没法重用,但是代码可以重用
二.jenkinsfile是什么
Jenkinsfile就是一个文本文件,里面记录着逻辑,在执行jenkins job的时候,会读取这个文件按照上面的描述来进行各种操作。像Dockerfile之于Docker,Playbook之于Ansible。
Jenkinsfile有2种方式,可以直接在web配置中进行编写,这样只适合临时项目调试或简短的内容。
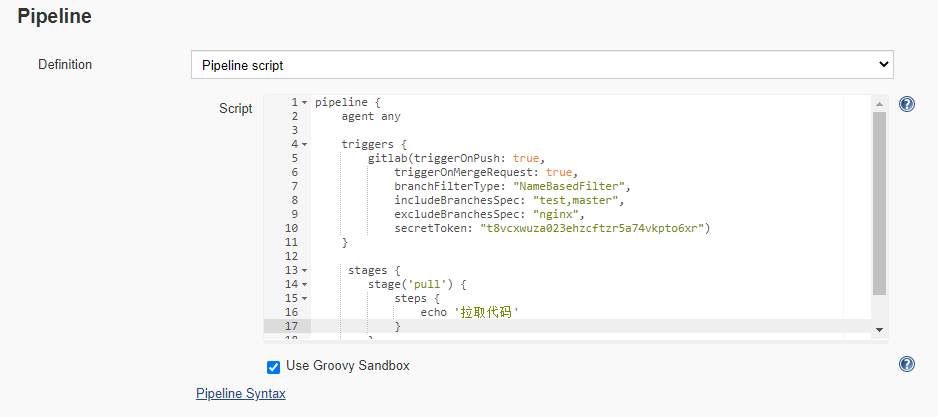
更多的是将pipeline的脚本在远程仓库上进行管理,这里配置远程仓库地址,让job每次执行的时候拉取这个项目,然后执行其中的某个文件。
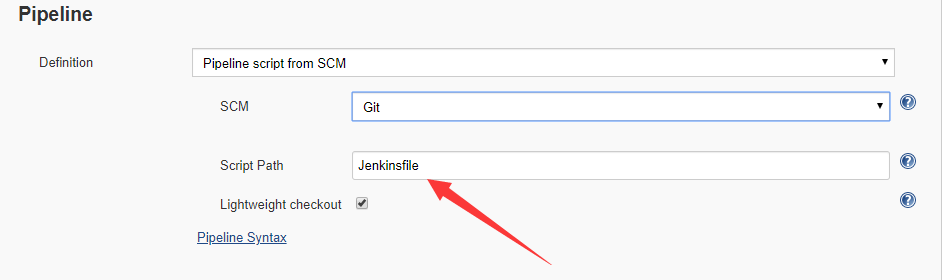
可以将脚本放到一个仓库集中管理,也可以放到每个项目中,和代码在一起进行维护,具体方式可以根据公司情况来安排。
三.pipeline语法选择
Jenkins pipeline有2种语法:脚本式(Scripted)语法和声明式(Declar-ative)语法。pipeline插件从2.5版本开始,才同时支持两种格式的语法,推荐使用声明式语法,它的使用人群更广泛,也更好表达维护。
Jenkins团队在一开始实现Jenkins pipeline时,Groovy语言被选择作为基础来实现pipeline。所以,在写pipeline脚本时,就是在写groovy脚本。但区别是,pipeline是在上面封装了一层,需要用固定格式,jenkins才可以识别。
pipeline {
agent any
stages {
stage('pull') {
steps {
git branch: 'master', credentialsId: 'jenkins', url: 'http://代码'
echo '开始拉取代码'
}
}
}
}
按照格式编写,在其中可以加入groovy的脚本,例如循环、判断、添加变量等等。这样的好处是降低了学习成本,例如上面的下载代码的git指令,用groovy单纯实现就如下方式。
"git clone http://代码".execute().text
那如果根据不同分支拉取、配置秘钥等操作,这里还要再增加切换的操作,要单独学习groovy相关的知识。
四.脚本式和声明式
脚本式语法比较灵活,编写清晰简单,groovy的语法可以直接使用套用,例如直接定义个变量。
node () {
def branch = 'test'
stage 'pull'
sh " echo 拉取代码"
stage 'build'
sh " echo 构建代码"
}
声明式的语法在内容多的时候会更清晰
pipeline {
agent any
stages {
stage('pull') {
steps {
echo '拉取代码'
}
}
stage('build') {
steps {
echo '构建代码'
}
}
}
}
对比2个例子,可以发现声明式好像才是复杂的那个。但其实在后续使用中,可以发现脚本式会比较凌乱,就像没用函数的感觉,没有一个标准和结构。脚本式和声明式只是语法上有些区别,对于方法和功能大多都是一样支持的。
五.插件与pipeline
pipeline基本结构决定的是pipeline整体流程,stage代表每个阶段,但实际具体做操作的是pipeline中的每一个步骤。步骤是pipeline中已经不能再拆分的最小操作。像echo执行echo指令,sh执行shell命令。
那是不是说,Jenkins pipeline内置了所有可能需要用到的步骤呢?显然没有必要,因为很多步骤可能永远不会用到。
就像自由Jenkins的插件,安装各种插件后,可以在自由风格的项目里,看到多出来的选项,进行配置。pipeline也是如此,安装某些插件后,就可以在pipeline中用代码调用插件了。
哪些插件适配了Jenkins pipelien,官方有列表方便检索,步骤具体说明可以查看官方步骤参考文档
pipeline是什么?的更多相关文章
- redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value 就是具体的customerid集合, ...
- Building the Testing Pipeline
This essay is a part of my knowledge sharing session slides which are shared for development and qua ...
- Scrapy:为spider指定pipeline
当一个Scrapy项目中有多个spider去爬取多个网站时,往往需要多个pipeline,这时就需要为每个spider指定其对应的pipeline. [通过程序来运行spider],可以通过修改配置s ...
- 图解Netty之Pipeline、channel、Context之间的数据流向。
声明:本文为原创博文,禁止转载. 以下所绘制图形均基于Netty4.0.28版本. 一.connect(outbound类型事件) 当用户调用channel的connect时,会发起一个 ...
- 初识pipeline
1.pipeline的产生 从一个现象说起,有一家咖啡吧生意特别好,每天来的客人络绎不绝,客人A来到柜台,客人B紧随其后,客人C排在客人B后面,客人D排在客人C后面,客人E排在客人D后面,一直排到店面 ...
- MongoDB 聚合管道(Aggregation Pipeline)
管道概念 POSIX多线程的使用方式中, 有一种很重要的方式-----流水线(亦称为"管道")方式,"数据元素"流串行地被一组线程按顺序执行.它的使用架构可参考 ...
- SSIS Data Flow 的 Execution Tree 和 Data Pipeline
一,Execution Tree 执行树是数据流组件(转换和适配器)基于同步关系所建立的逻辑分组,每一个分组都是一个执行树的开始和结束,也可以将执行树理解为一个缓冲区的开始和结束,即缓冲区的整个生命周 ...
- Kafka到Hdfs的数据Pipeline整理
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 找时间总结整理了下数据从Kafka到Hdfs的一些pipeline,如下 1> Kafka ...
- SQL Queries from Transactional Plugin Pipeline
Sometimes the LINQ, Query Expressions or Fetch just doesn't give you the ability to quickly query yo ...
- One EEG preprocessing pipeline - EEG-fMRI paradigm
The preprocessing pipeline of EEG data from EEG-fMRI paradigm differs from that of regular EEG data, ...
随机推荐
- ELK 7.4.2 单机安装配置
Java环境准备 JDK下载 https://www.oracle.com/technetwork/java/javase/overview/index.html [root@manager ~]# ...
- [hdu6134]Battlestation Operational
1 #include<bits/stdc++.h> 2 using namespace std; 3 #define mod 1000000007 4 #define N 1000005 ...
- [luogu5344]逛森林
由于没有删边操作,可以先建出整棵森林,之后再用并查集判断是否连通,若连通必然与最后的森林相同 但如果用树链剖分+线段树的形式来优化建图,更具体如下: 建立两颗线段树,左边从儿子连向父亲,右边从父亲连向 ...
- AOP实现方式二
applicationContext.xml <!--方法二 自定义类--> <bean id="diyPointCut" class="com.sha ...
- k8s-Pod污点与容忍
目录 Pod污点与容忍 大白话先解释一下污点与容忍 为什么要用污点和容忍? 官方解释 Taints参数 标记污点 容忍污点 取消所有节点污点 Pod污点与容忍 大白话先解释一下污点与容忍 污点:被打上 ...
- spring中使用@value注入static静态变量
@Value("${meeting.private_key}")public static String PRIVATE_KEY;发现没有数据,null 分析 Spring是不能直 ...
- 洛谷 P5527 - [Ynoi2012] NOIP2016 人生巅峰(抽屉原理+bitset 优化背包)
洛谷题面传送门 一道挺有意思的题,想到了某一步就很简单,想不到就很毒瘤( 首先看到这样的设问我们显然可以想到背包,具体来说题目等价于对于每个满足 \(i\in[l,r]\) 的 \(a_i\) 赋上一 ...
- R包 tidyverse 分列
代码: 1 library(tidyverse) 2 separate(data = df,col=chr_pos,into=c("chr","pos"),se ...
- Excel-数据分列的多种方法实现
2.数据->分列 (数据格式统一的精准分列)<=> 手动快捷键ctrl+E+等待 ("模糊模仿""分列)<=> 用函数实现(精准分列) 用函 ...
- 系列好文 | Kubernetes 弃用 Docker,我们该何去何从?
作者 | 张攀(豫哲) 来源 | 尔达 Erda 公众号 导读:Erda 作为一站式云原生 PaaS 平台,现已面向广大开发者完成 70w+ 核心代码全部开源!**在 Erda 开源的同时,我们计划编 ...