初识pipeline
1、pipeline的产生
从一个现象说起,有一家咖啡吧生意特别好,每天来的客人络绎不绝,客人A来到柜台,客人B紧随其后,客人C排在客人B后面,客人D排在客人C后面,客人E排在客人D后面,一直排到店面门外。老板和三个员工首先为客人A准备食物:员工甲拿了一个干净的盘子,然后员工乙在盘子里装上薯条,员工丙再在盘子里放上豌豆,老板最后配上一杯饮料,完成对客人A的服务,送走客人A,下一位客人B开始被服务。然后员工甲又拿了一个干净的盘子,员工乙又装薯条,员工丙又放豌豆,老板又配上了一杯饮料,送走客人B,客人C开始被服务。一直重复下去。

从效率方面观察这个现象,当服务客人A时,在员工甲拿了一个盘子后,员工甲一直处于空闲状态,直到送走客人A,客人B被服务。老板自然而然的就会想到如果每个人都不停的干活,就可以服务更多的客人,赚到更多的钱。老板通过不停的尝试想出了一个办法。以客户A,B为例阐述这个方法:员工甲为客户A准备好了盘子后,在员工乙开始为客户A装薯条的同时,员工甲开始为客户B准备托盘。这样员工甲就可以不停的进行生产。整个过程如下图,客户们围着咖啡吧台排队,因为有四个生产者,一个老板加三个员工,所以可以同时服务四个客户。我们将目光转向老板,单位时间从他那里出去的客户数提高了将近四倍,也就是说效率提高将近四倍。

pipeline的概念可以从这里抽象出来:将一件需要重复做的事情(这里指为客户准备一份精美的食物)切割成各个不同的阶段(这里是四个阶段:盘子,薯条,豌豆,饮料),每一个阶段由独立的单元负责(四个生产者分别负责不同的环节)。所有待执行的对象依次进入作业队列(这里是所有的客户排好队依次进入服务,除了开始和结尾的一段时间,任意时刻,四个客户被同时服务)。对应到CPU中,每一条指令的执行过程可以切割成:fetch instruction、decode it、find operand、perform action、store result 5个阶段。
2、将pipeline应用到CPU的计算单元中
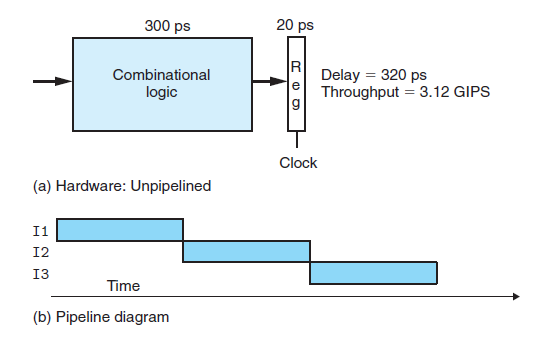
在未将pipeline应用到CPU之前,假如一个计算单元耗时300ps,将结果写入到寄存器耗时20ps,那么一条指令的执行时间为320ps。吞吐量定义为单位时间内执行的指令的条数,一般其单位为GIPS(giga-instruction per second),那么其吞吐量为3.12 GIPS,也就是说每秒执行3.12 giga条指令,1 giga 个= 10^9 个。
下面将pipeline应用到CPU,看计算单元的吞吐量会提高多少。我们将上图的组合逻辑单元切割成三个小的组合逻辑单元,每个组合逻辑单元耗时100ps,另外为了使前后组合逻辑单元的执行不相互影响,需要在每一对的小单元中间插入一个寄存器(对于这一点的理解,看完下面关于使用pipeline的CPU的运行过程就可以理解)如下图所示:
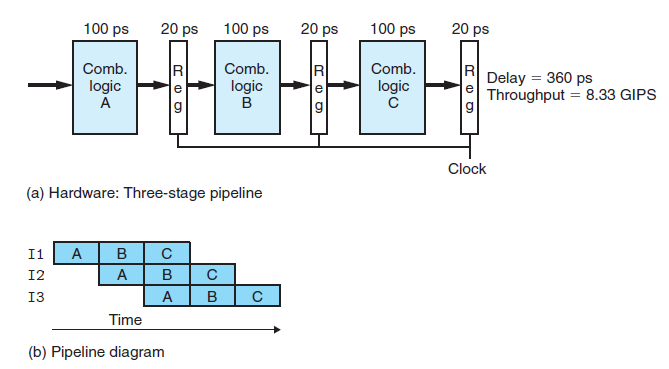
运行原理:首先这里非常值得指出的是,这里对寄存器的模型表示有些不细腻,因为从上图中并不能看出每个寄存器由输入,状态,和输出三个小单元组成。对于I1,I2,I3三条指令,当时钟迎来第一个上升沿时,I1首先进入组合逻辑A(如果这里不理解时钟,暂且忽略,下面会讲解),经过100ps后将结果花20ps写入到第一个寄存器的输入;当时钟迎来第二个上升沿时,更新第一个寄存器的状态和输出,即把I1指令经过组合逻辑A 后的结果更新到第一个寄存器以作为组合逻辑单元B的输入。与此同时,I2进入组合逻辑单元A,并在100ps后将结果花20ps写入到第一个寄存器的输入,这里注意,第一个寄存器的状态和输出并没有发生变化。这种机制保证了前后指令的互不干扰性。当时钟第三个上升沿来到时,I1进入逻辑单元C,I2进入逻辑单元B,I3开始进入逻辑单元A。
下面我们来计算使用pipeline的计算单元的吞吐量,由于每个阶段都需要100ps+20ps=120ps的时间,我们可以选用使得系统吞吐量最大的周期为120ps的时钟1/120*1000=8.3 GIPS,即每秒钟执行8.3 giga条指令相比于未使用pipeline的3.12 GIPS,提高了2.67倍,大家可能有疑问为什么不是3倍,因为我们为了让前后指令互不影响插入了两个寄存器,所以达不到最大极限3。
上面两幅图中的两幅b图是专门用来表示pipeline中各个时刻各个指令所处状态的pipeline diagram。
3、决定计算单元速度的是pipeline而不是系统时钟的频率
我们以第2部分为背景来阐述这个问题,三个阶段,每一阶段耗时120 ps,如果时钟周期高于120ps,那么将会出现寄存器值由于没有来得及更新导致的指令执行混乱的情况。对于更一般的情况,比如从左向右,三个计算单元的执行时间是(120+20)+(80+20)+(100+20)=360,那么时钟周期必须大于最大的单个组合逻辑单元的执行时间,否则就会出现阶段执行不完整的情况,即140ps,所以说决定计算单元速度的是pipeline,更精确的说是pipeline中的最大的组合逻辑单元的执行时间。对于如何将计算单元切割成更小的执行时间几乎相同的阶段,对硬件设计者来说,是一个挑战。
4、delay slot
在上面的讨论中我们都假设连续的指令间并没有依赖关系,现在引入指令间的依赖关系。依赖关系可以分为两种:data dependency, control dependency。
对于data dependency,我们用下面的指令序列作为例子
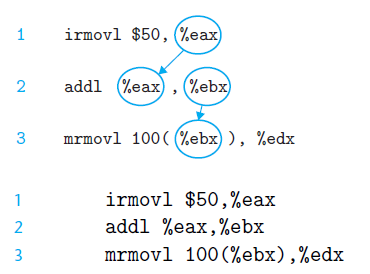
图中的小圆圈加箭头表示了这种依赖关系,比如第二条指令的执行需要用到第一条指令的结果,所以第二条指令必须推迟进入pipeline的时间,称为load/store delay slot,以获得eax更新后的值,2条与第3条的数据依赖关系同理。
对于control dependency,我们用下面的指令序列作为例子

第3条指令为跳转指令,第4条指令是否执行依赖于第三条指令的结果,即是否跳转,所以第四条指令必须延迟进入pipeline的时间,称为branch delay slot。
5、 参考资料
《see mips run》
《computer system: a programmer's perspective》p391-p400
初识pipeline的更多相关文章
- 【redis】pipeline - 管道模型
redis-pipeline 2020-02-10: 因为我把github相关的wiki删了,所以导致破图...待解决.(讲真github-wiki跟project是2个url,真的不好用) 因为用的 ...
- 初识ASP.NET CORE:一、HTTP pipeline
完整的http请求在asp.net framework中的处理流程: Asp.Net HttpRequest--> HTTP.exe--> inetinfo.exe(w3wp.exe)-& ...
- python自动化开发-[第二十四天]-高性能相关与初识scrapy
今日内容概要 1.高性能相关 2.scrapy初识 上节回顾: 1. Http协议 Http协议:GET / http1.1/r/n...../r/r/r/na=1 TCP协议:sendall(&qu ...
- Scrapy: 初识Scrapy
1.初识Scrapy Scrapy是为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或者存储历史数据等一系列的程序中. 2.选择一个网站 当需要从某个网站获取信息时, ...
- 01:初识Redis
付磊和张益军两位大咖写的葵花宝典(Redis开发和运维)学习笔记. 一.初识Redis 1.redis简介 Redis是一种基于键值对(key-value)的NoSQL数据库,与很多键值对数据库不同的 ...
- ? 初识Webx 3
初识webx 2: http://www.cnblogs.com/lddbupt/p/5552351.html Webx Turbine建立在Webx Framework的基础上,实现了页面渲染.布局 ...
- ? 初识Webx 2
初识Webx 1: http://www.cnblogs.com/lddbupt/p/5547189.html Webx Framework负责完成一系列基础性的任务. 比如系统初始化和响应请求. 系 ...
- 1.初识Redis
作者 微信:tangy8080 电子邮箱:914661180@qq.com 更新时间:2019-08-14 20:35:36 星期三 欢迎您订阅和分享我的订阅号,订阅号内会不定期分享一些我自己学习过程 ...
- 初识——HTTP3
目录 初识--HTTP3 HTTP HTTP1.0和HTTP1.1的主要区别 HTTP2 HTTP3 相关链接 初识--HTTP3 想了解HTTP3??那我们就得先知道为啥会出现HTTP3,因此我们需 ...
随机推荐
- VNC connect:Connection refused(10061)
在Windows机器上使用VNC Viewer访问Linux服务器,有时候会遇到"connect:Connection refused(10061)"这个错误,导致这个错误出现的原 ...
- Oracle 哈希连接原理
<基于Oracle的sql优化>里关于哈希连接的原理介绍如下: 哈希连接(HASH JOIN)是一种两个表在做表连接时主要依靠哈希运算来得到连接结果集的表连接方法. 在Oracle 7.3 ...
- 如何配置远程mysql服务器
如何配置远程mysql服务器 分配用户权限 可以先看一下目前的用户权限状况: use mysql; select host,user,password from user; 然后分配新的权限给某一用户 ...
- sql语句返回值的问题
由于执行sql语句的时候执行成功或者失败会返回执行的影响函数,用list是因为查询的结果可能为null也可能set后放到集合里去: 所以返回值类型用int
- Android--sharepreference总结
SharedPreferences类,它是一个轻量级的存储类,特别适合用于保存软件配置参数. SharedPreferences保存数据,其背后是用xml文件存放数据,文件存放在/data/data/ ...
- TCP/IP协议(二)tcp/ip基础知识
今天凌晨时候看书,突然想到一个问题:怎样做到持续学习?然后得出这样一个结论:放弃不必要的社交,控制欲望,克服懒惰... 然后又有了新的问题:学习效率时高时低,状态不好怎么解决?这也是我最近在思考的问题 ...
- [LeetCode] Missing Number 丢失的数字
Given an array containing n distinct numbers taken from 0, 1, 2, ..., n, find the one that is missin ...
- spring定时器,定时器一次执行两次的问题
Spring 定时器 方法一:注解形式 配置文件头加上如下: xmlns:task="http://www.springframework.org/schema/task" htt ...
- 点击div 跳转并通过URL传参
点击div前要先给div绑定要传的参数: //给panel绑定自定义属性,方便在跳转时传带参数,键/值对排列 panel.attr("user_age",user_age); pa ...
- Redux原理(一):Store实现分析
写在前面 写React也有段时间了,一直也是用Redux管理数据流,最近正好有时间分析下源码,一方面希望对Redux有一些理论上的认识:另一方面也学习下框架编程的思维方式. Redux如何管理stat ...