Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍
Scrapy目前已经可以很好的在python3上运行
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列),Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。
Scrapy data flow(流程图)
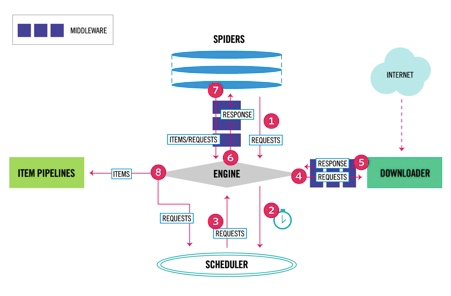
Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎ENGINE获得初始请求开始抓取。
2、爬虫引擎ENGINE开始请求调度程序SCHEDULER,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器DOWNLOADER,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎ENGINE。
6、爬虫引擎ENGINE将下载器DOWNLOADER的响应通过中间件MIDDLEWARES返回给爬虫SPIDERS进行处理。
7、爬虫SPIDERS处理响应,并通过中间件MIDDLEWARES返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器SCHEDULER,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
各个组件介绍
爬虫引擎(ENGINE)
爬虫引擎负责控制各个组件之间的数据流,当某些操作触发事件后都是通过engine来处理。
调度器(SCHEDULER)
调度接收来engine的请求并将请求放入队列中,并通过事件返回给engine。
下载器(DOWNLOADER)
通过engine请求下载网络数据并将结果响应给engine。
Spider
Spider发出请求,并处理engine返回给它下载器响应数据,以items和规则内的数据请求(urls)返回给engine。
管道项目(item pipeline)
负责处理engine返回spider解析后的数据,并且将数据持久化,例如将数据存入数据库或者文件。
下载中间件
下载中间件是engine和下载器交互组件,以钩子(插件)的形式存在,可以代替接收请求、处理数据的下载以及将结果响应给engine。
spider中间件
spider中间件是engine和spider之间的交互组件,以钩子(插件)的形式存在,可以代替处理response以及返回给engine items及新的请求集。
如何创建Scrapy项目
创建Scrapy项目
创建scrapy项目的命令是scrapy startproject 项目名,创建一个爬虫
进入到项目目录scrapy genspider 爬虫名字 爬虫的域名,例子如下:
zhaofandeMBP:python_project zhaofan$ scrapy startproject test1
New Scrapy project 'test1', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/zhaofan/Documents/python_project/test1 You can start your first spider with:
cd test1
scrapy genspider example example.com
zhaofandeMBP:python_project zhaofan$
zhaofandeMBP:test1 zhaofan$ scrapy genspider shSpider hshfy.sh.cn
Created spider 'shSpider' using template 'basic' in module:
test1.spiders.shSpider
scrapy项目结构
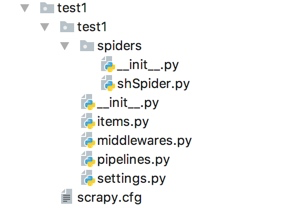
items.py 负责数据模型的建立,类似于实体类。
middlewares.py 自己定义的中间件。
pipelines.py 负责对spider返回数据的处理。
settings.py 负责对整个爬虫的配置。
spiders目录 负责存放继承自scrapy的爬虫类。
scrapy.cfg scrapy基础配置
Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理的更多相关文章
- Python之爬虫从入门到放弃(十三) Scrapy框架整体的了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python之爬虫(十四) Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- Python爬虫从入门到放弃(二十一)之 Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrap ...
- python爬虫从入门到放弃(二)之爬虫的原理
在上文中我们说了:爬虫就是请求网站并提取数据的自动化程序.其中请求,提取,自动化是爬虫的关键!下面我们分析爬虫的基本流程 爬虫的基本流程 发起请求通过HTTP库向目标站点发起请求,也就是发送一个Req ...
- Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- python爬虫从入门到放弃前奏之学习方法
首谈方法 最近在整理爬虫系列的博客,但是当整理几篇之后,发现一个问题,不管学习任何内容,其实方法是最重要的,按照我之前写的博客内容,其实学起来还是很点枯燥不能解决传统学习过程中的几个问题: 这个是普通 ...
随机推荐
- Java经典编程题50道之八
求s=a+aa+aaa+aaaa+aa...a的值,其中a是一个数字.例如2+22+222+2222+22222(此时共有5个数相加),几个数相加由键盘控制. public class Example ...
- 点评阿里JAVA手册之异常日志(异常处理 日志规约 )
下载原版阿里JAVA开发手册 [阿里巴巴Java开发手册v1.2.0] 本文主要是对照阿里开发手册,注释自己在工作中运用情况. 本文内容:异常处理 日志规约 本文难度系数为一星(★) 本文为第三篇 ...
- OpenGL判断一个点是否可见
关于OpenGL中判断一个点是否可见,可以分成两种情况讨论:点在2D空间中和3D空间中的时候.并且"在2D空间中"可以看作"在3D空间中"的特殊情况. 温馨提示 ...
- Redis大幅性能提升之Batch批量读写
Redis大幅性能提升之Batch批量读写 提示:本文针对的是StackExchange.Redis 一.问题呈现 前段时间在开发的时候,遇到了redis批量读的问题,由于在StackExchange ...
- Java阶段性测试--第二三大题参考代码
第二大题: 1.打印出所有的 "水仙花数 ",所谓 "水仙花数 "是指一个三位数,其各位数字立方和等于它本身 package Test1; //1.打印出所有的 ...
- cs6安装
[按下面步骤操作 无需序列号] ·打上补丁 永远无需序列号 (现在网上没什么能用的序列号) ·1双击CS软件安装,选择试用 ·2创建ID 输入自己邮箱和密码,姓名可以随意输入 ·3安装完成后 运行一次 ...
- Scrapy中使用Django的Model访问数据库
Scrapy中使用Django的Model进行数据库访问 当已存在Django项目的时候,直接引入Django的Model来使用比较简单 # 使用以下语句添加Django项目的目录到path impo ...
- Azure 基础:Table storage
Azure Storage 是微软 Azure 云提供的云端存储解决方案,当前支持的存储类型有 Blob.Queue.File 和 Table.其中的 Table 就是本文的主角 Azure Tabl ...
- 关于javascript闭包理解
闭包(closure)是Javascript语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现. 一:关于变量的作用域 Javascript语言的特殊之处,就在于函数内部可以直接读取全局变量. ...
- java.util.concurrent.ExecutionException: org.apache.catalina.LifecycleExcept问题解决方案
在部署Dynamic Web Project时,如果正确配置web.xml或者标注时,仍然出现以上异常的话,可以尝试以下内容讲解的方法: 首先,双击eclipse中的servers,位置如下图&quo ...