Python之爬虫(十四) Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍
Scrapy目前已经可以很好的在python3上运行
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列),Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。
Scrapy data flow(流程图)
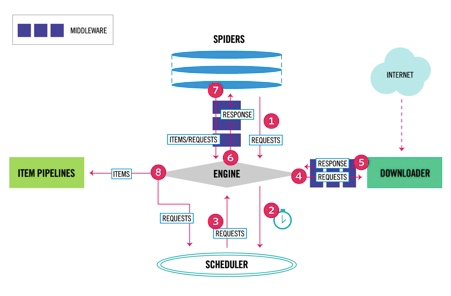
Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎ENGINE获得初始请求开始抓取。
2、爬虫引擎ENGINE开始请求调度程序SCHEDULER,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器DOWNLOADER,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎ENGINE。
6、爬虫引擎ENGINE将下载器DOWNLOADER的响应通过中间件MIDDLEWARES返回给爬虫SPIDERS进行处理。
7、爬虫SPIDERS处理响应,并通过中间件MIDDLEWARES返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器SCHEDULER,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
各个组件介绍
爬虫引擎(ENGINE)
爬虫引擎负责控制各个组件之间的数据流,当某些操作触发事件后都是通过engine来处理。
调度器(SCHEDULER)
调度接收来engine的请求并将请求放入队列中,并通过事件返回给engine。
下载器(DOWNLOADER)
通过engine请求下载网络数据并将结果响应给engine。
Spider
Spider发出请求,并处理engine返回给它下载器响应数据,以items和规则内的数据请求(urls)返回给engine。
管道项目(item pipeline)
负责处理engine返回spider解析后的数据,并且将数据持久化,例如将数据存入数据库或者文件。
下载中间件
下载中间件是engine和下载器交互组件,以钩子(插件)的形式存在,可以代替接收请求、处理数据的下载以及将结果响应给engine。
spider中间件
spider中间件是engine和spider之间的交互组件,以钩子(插件)的形式存在,可以代替处理response以及返回给engine items及新的请求集。
如何创建Scrapy项目
创建Scrapy项目
创建scrapy项目的命令是scrapy startproject 项目名,创建一个爬虫
进入到项目目录scrapy genspider 爬虫名字 爬虫的域名,例子如下:
zhaofandeMBP:python_project zhaofan$ scrapy startproject test1
New Scrapy project 'test1', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/zhaofan/Documents/python_project/test1 You can start your first spider with:
cd test1
scrapy genspider example example.com
zhaofandeMBP:python_project zhaofan$
zhaofandeMBP:test1 zhaofan$ scrapy genspider shSpider hshfy.sh.cn
Created spider 'shSpider' using template 'basic' in module:
test1.spiders.shSpider
scrapy项目结构
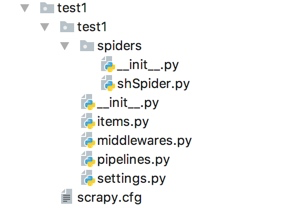
items.py 负责数据模型的建立,类似于实体类。
middlewares.py 自己定义的中间件。
pipelines.py 负责对spider返回数据的处理。
settings.py 负责对整个爬虫的配置。
spiders目录 负责存放继承自scrapy的爬虫类。
scrapy.cfg scrapy基础配置
Python之爬虫(十四) Scrapy框架的架构和原理的更多相关文章
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- PYTHON网络爬虫与信息提取[scrapy框架应用](单元十、十一)
scrapy 常用命令 startproject 创建一个新的工程 scrapy startproject <name>[dir] genspider 创建一个爬虫 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection) Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数 ...
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
随机推荐
- Linux中tomcat的部署
红帽7如何配置tomcat 1.下载tomcat9.0和java-1.8 tomcat的下载地址: https://tomcat.apache.org/ java1.8是radhat7自带: [roo ...
- python模拟网站登陆-滑动验证码
普通滑动验证 以http://admin.emaotai.cn/login.aspx为例这类验证码只需要我们将滑块拖动指定位置,处理起来比较简单.拖动之前需要先将滚动条滚动到指定元素位置. impor ...
- isinstance用法
''' 作用:来判断一个对象是否是一个已知的类型. 其第一个参数(object)为对象,第二个参数(type)为类型名(int...)或类型名的一个列表((int,list,float)是一个列表). ...
- Python实现梯度法(最速上升(下降)法)寻找函数极大(极小)值
首先简介梯度法的原理.首先一个实值函数$R^{n} \rightarrow R$的梯度方向是函数值上升最快的方向.梯度的反方向显然是函数值下降的最快方向,这就是机器学习里梯度下降法的基本原理.但是运筹 ...
- 容器技术之Docker-swarm
前文我聊到了docker machine的简单使用和基本原理的说明,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13160915.html:今天我们来聊一聊d ...
- opencv c++访问某一区域
int main(){ cv::Mat m1(,, CV_8UC1); for(int i=;i<m1.rows;++i) for(int j=;j<m1.cols;++j) m1.at& ...
- Python Selenium百度搜索翻页查找文字
#!/usr/bin/python # -*- coding: utf- -*- from selenium import webdriver import time # browser = webd ...
- Day10-微信小程序实战-交友小程序-自定义callPhone 和copyText组件
---为了方便用户可以拨打电话和复制微信号(下面就要实现这样的两个功能) 注意:在小程序中是没办法直接的添加用户的微信的,所以就只能是复制微信号 (这种东西的话可以直接去做,也可以做成组件,做出组件的 ...
- 线程间配合:Condition、Semaphore、CountDownLatch、CyclicBarrier
1 重入锁的好搭档:Condition条件 如果大家理解了Object.wait()和Object.notify()方法的话,那么就能很容易理解Condition接口了.它和wait()和notify ...
- MySQL 合并查询,以map或对象的形式返回
转载 CSDN博主「小林子林子」 -> https://blog.csdn.net/qq_26106607/article/details/84961254 原始SQL-> 目的-> ...