大数据开发 | MapReduce介绍
| 1. MapReduce 介绍 |
1.1MapReduce的作用
假设有一个计算文件中单词个数的需求,文件比较多也比较大,在单击运行的时候机器的内存受限,磁盘受限,运算能力受限,而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度,因此这个工作可能完成不了。针对以上这个案例,MapReduce在这里能起到什么作用呢,引入MapReduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理。
可见在程序由单机版扩成分布式时,会引入大量的复杂工作。为了提高开发效率,可以将分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。而MapReduce就是这样一个分布式程序的通用框架。
1.2MapReduce架构图
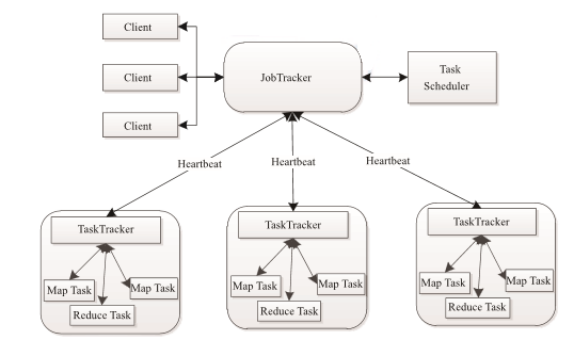
MapReduce 也采用了 Master/Slave(M/S)架构。它主要由以下几个组件组成 :Client、JobTracker、 TaskTracker 和 Task。下面分别对这几个组件进行介绍。
(1)Client
用户编写的MapReduce程序通过Client提交到JobTracker端;同时用户可通过Client提供的一些接口查看作业运行状态。在Hadoop内部用“作业” (Job)表示MapReduce程序。一个 MapReduce程序可对应若干个作业,而每个作业会被分解成若干个Map/Reduce任务(Task)。
(2)JobTracker
JobTracker 主要负责资源监控和作业调度。JobTracker 监控所有 TaskTracker 与作业Job的健康状况,一旦发现失败情况后,其会将相应的任务转移到其他节点;同时,JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop 中,任务调度器是一个可插拔的模块,用户可以根据自己的需要设计相应的调度器。
(3)TaskTracker
TaskTracker会周期性地通过Heartbeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死 任务等)。TaskTracker 使用“slot”等量划分本节点上的资源量。 “slot”代表计算资源(CPU、 内存等)。一个 Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot分为Map slot和Reduce slot 两种,分别供Map Task和Reduce Task使用。TaskTracker通过slot数目(可配置参数)限定Task的并发度。
(4)Task
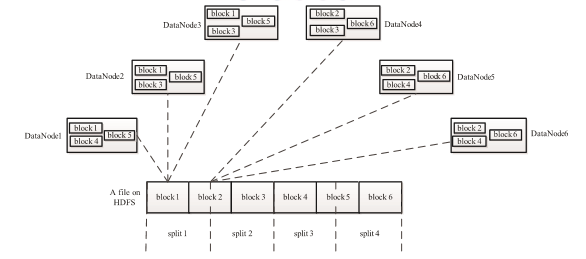
Task 分为 Map Task 和 Reduce Task 两种,均由TaskTracker启动。从上一小节中我们知道,HDFS以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。 split 与 block 的对应关系如下图所示。split 是一个逻辑概念,它只包含一些元数据信息,比如 数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。但需要注意的是,split的多少决定了Map Task的数目,因为每个split会交由一个Map Task处理。
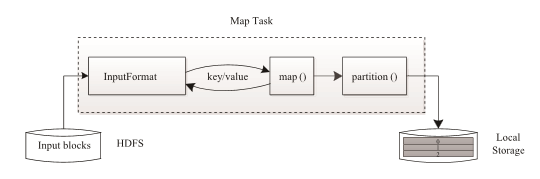
Map Task 执行过程如下图所示。由该图可知,Map Task 先将对应的split 迭代解析成一 个个 key/value 对,依次调用用户自定义的map() 函数进行处理,最终将临时结果存放到本地磁盘上,其中临时数据被分成若干个partition(分片),每个partition 将被一个Reduce Task处理。
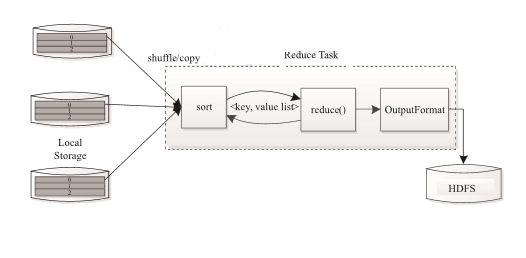
Reduce Task 执行过程如下图所示。该过程分为三个阶段:
①从远程节点上读取Map Task 中间结果(称为“Shuffle阶段”);
②按照key对key/value 对进行排序(称为“Sort阶段”);
③依次读取 <key, value list>,调用用户自定义的 reduce() 函数处理,并将最终结果存到HDFS上(称为“Reduce 阶段”)。
MapReduce是一种并行编程模式,利用这种模式软件开发者可以轻松地编写出分布式并行程序。在Hadoop的体系结构中,MapReduce是一个简单易用的软件框架,基于它可以将任务分发到由上千台商用机器组成的集群上,并以一种可靠容错的方式并行处理大量的数据集,实现Hadoop的并行任务处理功能。MapReduce框架是由一个单独运行在主节点的JobTrack和运行在每个集群从节点的TaskTrack共同组成的。
主节点负责调度构成一个作业的所有任务,这些任务分布在不同的节点上。主节点监控它们的执行情况,并且重新执行之前失败的任务;
从节点仅负责由主节点指派的任务。
当一个Job任务被提交时,JobTrack接收到提交作业和其配置信息之后,就会配置信息等发给从节点,同时调度任务并监控TaskTrack的执行。
1.3MapReduce程序运行演示
Hadoop的发布包中内置了一个hadoop-mapreduce-example-2.6.5.jar,这个jar包中有各种MR示例程序,可以通过以下步骤运行:
启动hdfs,yarn,然后在集群中的任意一台服务器上启动执行程序(比如运行wordcount):
hadoop jar hadoop-mapreduce-example-2.6.5.jar wordcount /wordcount/data /wordcount/out
| 2.MapReduce 编程 |
2.1编程规范
1) 用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
2) Mapper的输入数据是KV对的形式(KV的类型可自定义)
3) Mapper的输出数据是KV对的形式(KV的类型可自定义)
4) Mapper中的业务逻辑写在map()方法中
5) map()方法(maptask进程)对每一个<K,V>调用一次
6) Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
7) Reducer的业务逻辑写在reduce()方法中
8) Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法
9) 用户自定义的Mapper和Reducer都要继承各自的父类
10) 整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
2.2wordcount 示例编写
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
(1)定义一个mapper类
//首先要定义四个泛型的类型
//keyin: LongWritable valuein: Text
//keyout: Text valueout:IntWritable public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//map方法的生命周期: 框架每传一行数据就被调用一次
//key : 这一行的起始点在文件中的偏移量
//value: 这一行的内容
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
(2)定义一个reducer类
//生命周期:框架每传递进来一个kv 组,reduce方法被调用一次
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历这一组kv的所有v,累加到count中
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
(3)定义一个主类,用来描述job并提交job
public class WordCountRunner {
//把业务逻辑相关的信息(哪个是mapper,哪个是reducer,要处理的数据在哪里,输出的结果放哪里……)描述成一个job对象
//把这个描述好的job提交给集群去运行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
//指定我这个job所在的jar包
// wcjob.setJar("/home/hadoop/wordcount.jar");
wcjob.setJarByClass(WordCountRunner.class);
wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
//设置我们的业务逻辑Mapper类的输出key和value的数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//设置我们的业务逻辑Reducer类的输出key和value的数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class);
//指定要处理的数据所在的位置
FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt");
//指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/"));
//向yarn集群提交这个job
boolean res = wcjob.waitForCompletion(true);
System.exit(res?0:1);
}
2.3集群运行模式
1) 将mapreduce程序提交给yarn集群resourcemanager,分发到很多的节点上并发执行
2) 处理的数据和输出结果应该位于hdfs文件系统
3) 提交集群的实现步骤:
将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动hadoop jar wordcount.jar cn.bigdata.mrsimple.WordCountDriver inputpath outputpath
出处:http://www.cnblogs.com/jerehedu/
版权声明:本文版权归烟台杰瑞教育科技有限公司和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
技术咨询:

大数据开发 | MapReduce介绍的更多相关文章
- FusionInsight大数据开发---MapReduce与YARN应用开发
MapReduce MapReduce的基本定义及过程 搭建开发环境 代码实例及运行程序 MapReduce开发接口介绍 1. MapReduce的基本定义及过程 MapReduce是面向大数据并行处 ...
- 大数据开发实战:MapReduce内部原理实践
下面结合具体的例子详述MapReduce的工作原理和过程. 以统计一个大文件中各个单词的出现次数为例来讲述,假设本文用到输入文件有以下两个: 文件1: big data offline data on ...
- 大数据技术 - MapReduce的Combiner介绍
本章来简单介绍下 Hadoop MapReduce 中的 Combiner.Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘I ...
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
- 大数据开发实战:Stream SQL实时开发二
1.介绍 本节主要利用Stream SQL进行实时开发实战,回顾Beam的API和Hadoop MapReduce的API,会发现Google将实际业务对数据的各种操作进行了抽象,多变的数据需求抽象为 ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
- 2019春招——Vivo大数据开发工程师面经
Vvio总共就一轮技术面+一轮HR面,技术面总体而言,比较宽泛,比较看中基础,面试的全程没有涉及简历上的东西(都准备好跟他扯项目了,感觉是抽取的题库...)具体内容如下: 1.熟悉Hadoop哪些组件 ...
- 大数据开发实战:Stream SQL实时开发三
4.聚合操作 4.1.group by 操作 group by操作是实际业务场景(如实时报表.实时大屏等)中使用最为频繁的操作.通常实时聚合的主要源头数据流不会包含丰富的上下文信息,而是经常需要实时关 ...
- 大数据开发实战:Stream SQL实时开发一
1.流计算SQL原理和架构 流计算SQL通常是一个类SQL的声明式语言,主要用于对流式数据(Streams)的持续性查询,目的是在常见流计算平台和框架(如Storm.Spark Streaming.F ...
随机推荐
- 开源分享 Unity3d客户端与C#分布式服务端游戏框架
很久之前,在博客园写了一篇文章,<分布式网游server的一些想法语言和平台的选择>,当时就有了用C#做网游服务端的想法.写了个Unity3d客户端分布式服务端框架,最近发布了1.0版本, ...
- 关于时间对象Date()
今天使用XCUI开发过程中发现另一个诡异的问题,就是年月日初始化之后默认时分秒的问题. 问题发生在重构交互日志页面的时候,原来的老页面是这样的: 进入了交互日志页面之后,默认会初始化时间为今天的凌晨到 ...
- Oracle数据库只读事务和无事务的区别
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt382 Oracle默认情况下(没有事务) 保证了SQL语句级别的读一致性,即 ...
- Day-9: 面对对象高级编程
数据封装.继承和多态只是面向对象编程中最基础的3个概念. 下面整理面向对象高级编程的更为强大的技巧. 使用__slots__:Python属于动态语言,可以允许已创建好的类动态地绑定任何属性和方法.但 ...
- Spark 贝叶斯分类算法
一.贝叶斯定理数学基础 我们都知道条件概率的数学公式形式为 即B发生的条件下A发生的概率等于A和B同时发生的概率除以B发生的概率. 根据此公式变换,得到贝叶斯公式: 即贝叶斯定律是关于随机事件A和B ...
- [js高手之路]Vue2.0基于vue-cli+webpack Vuex用法详解
在这之前,我已经分享过组件与组件的通信机制以及父子组件之间的通信机制,而我们的vuex就是为了解决组件通信问题的 vuex是什么东东呢? 组件通信的本质其实就是在组件之间传递数据或组件的状态(这里将数 ...
- JQuery 相关用法和操作
01-JQuery 基础语法: 1.使用JQuery必须先导入JQuery.x.x.xjs文件. 2.JQuery中的选择器: $(选择器).函数() ① $是JQuery的缩写,既可以使用JQuer ...
- 201521123060 《Java程序设计》第6周学习总结
1. 本周学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图,对面向对象思想进行一个总结. 2. 书面作业 1.clone方法 1.1 Object对 ...
- Eclipse rap 富客户端开发总结(7) : 如何修改rap的样式
1. Rap样式原理 Rap的界面样式目前是以css来配置的,程序启动后加载相应的css配置文件再对组件进行样式设置,界面上的所有组件 Label button composit等的样式最开始都是通 ...
- wampserver启动不起来的原因?
如果没怎么动wamp的配置文件就发现wampserver启动不起来了,那么可能你碰到了iis服务器. 原因是apache的端口占用的是80,而iis的端口占用也是80所以造成了不能启动wampserv ...