Spark 贝叶斯分类算法
一、贝叶斯定理数学基础
我们都知道条件概率的数学公式形式为
 即B发生的条件下A发生的概率等于A和B同时发生的概率除以B发生的概率。
即B发生的条件下A发生的概率等于A和B同时发生的概率除以B发生的概率。
根据此公式变换,得到贝叶斯公式: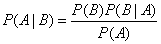 即贝叶斯定律是关于随机事件A和B的条件概率(或边缘概率)的一则定律。通常,事件A在事件B发生的条件溪的概率,与事件B在事件A的条件下的概率是不一样的,而贝叶斯定律就是描述二者之间的关系的。
即贝叶斯定律是关于随机事件A和B的条件概率(或边缘概率)的一则定律。通常,事件A在事件B发生的条件溪的概率,与事件B在事件A的条件下的概率是不一样的,而贝叶斯定律就是描述二者之间的关系的。
更进一步将贝叶斯公式进行推广,假设事件A发生的概率是由一系列的因素(A1,A2,A3,...An)决定的,则事件A的全概率公式为:
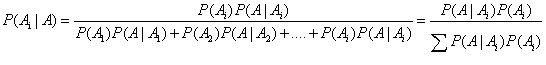
二、朴素贝叶斯分类
朴素贝叶斯分类是一种十分简单的分类算法,其思想基础是:对于给定的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项就属于哪个类别。
假设V=(v1,v2,v3....vn)是一个待分项,而vn为V的每个特征向量;
B=(b1,b2,b3...bn)是一个分类集合,bn为每个具体的分类;
如果需要测试某个Vn归属于B集合中的哪个具体分类,则需要计算P(bn|V),即在V发生的条件下,归属于b1,b2,b3,....bn中哪个可能性最大。即:
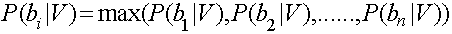
因此,这个问题转换成求每个待分项分配到集合中具体分类的概率是多少。而这个·具体概率的求法可以使用贝叶斯定律。
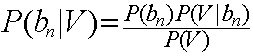
经过变换得出:
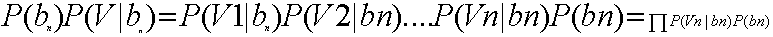
三、MLlib对应的API
1、贝叶斯分类伴生对象NativeBayes,原型:
object NaiveBayes extends scala.AnyRef with scala.Serializable {
def train(input : org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint]) : org.apache.spark.mllib.classification.NaiveBayesModel = { /* compiled code */ }
def train(input : org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint], lambda : scala.Double) : org.apache.spark.mllib.classification.NaiveBayesModel = { /* compiled code */ }
}
其主要定义了训练贝叶斯分类模型的train方法,其中input为训练样本,lambda为平滑因子参数。
2、train方法,其是NativeBayes对象的静态方法,根据设置的朴素贝叶斯分类参数新建朴素贝叶斯分类类,并执行run方法进行训练。
3、朴素贝叶斯分类类NaiveBayes,原型:
class NaiveBayes private (private var lambda : scala.Double) extends scala.AnyRef with scala.Serializable with org.apache.spark.Logging {
def this() = { /* compiled code */ }
def setLambda(lambda : scala.Double) : org.apache.spark.mllib.classification.NaiveBayes = { /* compiled code */ }
def run(data : org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint]) : org.apache.spark.mllib.classification.NaiveBayesModel = { /* compiled code */ }
}
4、run方法,该方法主要计算先验概率和条件概率。首先对所有样本数据进行聚合,以label为key,聚合同一个label的特征features,得到所有label的统计(label,features之和),然后根据label统计数据,再计算p(i),和theta(i)(j),最后,根据类别标签列表、类别先验概率、各类别下的每个特征的条件概率生成贝叶斯模型。
先验概率并取对数p(i)=log(p(yi))=log((i类别的次数+平滑因子)/(总次数+类别数*平滑因子)))
各个特征属性的条件概率,并取对数
theta(i)(j)=log(p(ai|yi))=log(sumTermFreqs(j)+平滑因子)-thetaLogDenom
其中,theta(i)(j)是类别i下特征j的概率,sumTermFreqs(j)是特征j出现的次数,thetaLogDenom一般分2种情况,如下:
1.多项式模型
thetaLogDenom=log(sumTermFreqs.values.sum+ numFeatures* lambda)
其中,sumTermFreqs.values.sum类别i的总数,numFeatures特征数量,lambda平滑因子
2.伯努利模型
thetaLogDenom=log(n+2.0*lambda)
5、aggregated:对所有样本进行聚合统计,统计没个类别下的每个特征值之和及次数。
6、pi表示各类别·的·先验概率取自然对数的值
7、theta表示各个特征在各个类别中的条件概率值
8、predict:根据模型的先验概率、条件概率,计算样本属于每个类别的概率,取最大项作为样本的类别
9、贝叶斯分类模型NaiveBayesModel包含参数:类别标签列表(labels)、类别先验概率(pi)、各个特征在各个类别中的条件概率(theta)。
四、使用示例
1、样本数据:
0,1 0 0
0,2 0 0
1,0 1 0
1,0 2 0
2,0 0 1
2,0 0 2
import org.apache.spark.mllib.classification.NaiveBayes
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.{SparkConf, SparkContext} object Bayes {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("BayesDemo").setMaster("local")
val sc=new SparkContext(conf)
//读取样本数据,此处使用自带的处理数据方式·
val data=MLUtils.loadLabeledPoints(sc,"d://bayes.txt")
//训练贝叶斯模型
val model=NaiveBayes.train(data,1.0)
//model.labels.foreach(println)
//model.pi.foreach(println)
val test=Vectors.dense(0,0,100)
val res=model.predict(test)
println(res)//输出结果为2.0
}
}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.classification.NaiveBayes
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.{SparkConf, SparkContext}
object Bayes {
def main(args: Array[String]): Unit = {
//创建spark对象
val conf=new SparkConf().setAppName("BayesDemo").setMaster("local")
val sc=new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
//读取样本数据
val data=sc.textFile("d://bayes.txt")//读取数据
val demo=data.map{ line=>//处理数据
val parts=line.split(',')//分割数据·
LabeledPoint(parts(0).toDouble,//标签数据转换
Vectors.dense(parts(1).split(' ').map(_.toDouble)))//向量数据转换
}
//将样本数据分为训练样本和测试样本
val sp=demo.randomSplit(Array(0.6,0.4),seed = 11L)//对数据进行分配
val train=sp(0)//训练数据
val testing=sp(1)//测试数据
//建立贝叶斯分类模型,并进行训练
val model=NaiveBayes.train(train,lambda = 1.0)
//对测试样本进行测试
val pre=testing.map(p=>(model.predict(p.features),p.label))//验证模型
val prin=pre.take(20)
println("prediction"+"\t"+"label")
for(i<- 0 to prin.length-1){
println(prin(i)._1+"\t"+prin(i)._2)
}
val accuracy=1.0 *pre.filter(x=>x._1==x._2).count()//计算准确度
println(accuracy)
}
}
Spark 贝叶斯分类算法的更多相关文章
- 从决策树学习谈到贝叶斯分类算法、EM、HMM --别人的,拷来看看
从决策树学习谈到贝叶斯分类算法.EM.HMM 引言 最近在面试中,除了基础 & 算法 & 项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法(当然,这完全 ...
- 从决策树学习谈到贝叶斯分类算法、EM、HMM
从决策树学习谈到贝叶斯分类算法.EM.HMM (Machine Learning & Recommend Search交流新群:172114338) 引言 log ...
- 朴素贝叶斯分类算法介绍及python代码实现案例
朴素贝叶斯分类算法 1.朴素贝叶斯分类算法原理 1.1.概述 贝叶斯分类算法是一大类分类算法的总称 贝叶斯分类算法以样本可能属于某类的概率来作为分类依据 朴素贝叶斯分类算法是贝叶斯分类算法中最简单的一 ...
- 数据分析与挖掘 - R语言:贝叶斯分类算法(案例一)
一个简单的例子!环境:CentOS6.5Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 名词解释: 先验概率:由以往的数据分析得到的概率, 叫做先验概率. 后验概率:而在 ...
- scikit-learn学习之贝叶斯分类算法
版权声明:<—— 用心写好你的每一篇文章,转载请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================= ...
- 《机器学习实战》基于朴素贝叶斯分类算法构建文本分类器的Python实现
============================================================================================ <机器学 ...
- 朴素贝叶斯分类算法-----java
1.贝叶斯分类的基础--贝叶斯定理 已知某条件概率.怎样得到两个事件交换后的概率,也就是在已知P(A|B)的情况下怎样求得P(B|A). 这里先解释什么是条件概率: 表示事件B已经发生的前提下,事件A ...
- spark 线性回归算法(scala)
构建Maven项目,托管jar包 数据格式 //0.fp_nid,1.nsr_id,2.gf_id,2.hydm,3.djzclx_dm,4.kydjrq,5.xgrq,6.je,7.se,8.jsh ...
- 利用朴素贝叶斯分类算法对搜狐新闻进行分类(python)
数据来源 https://www.sogou.com/labs/resource/cs.php介绍:来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL ...
随机推荐
- 阿里消息队列中间件 RocketMQ源码解析:Message发送&接收
- 最短路之Floyd算法
1.介绍 floyd算法只有五行代码,代码简单,三个for循环就可以解决问题,所以它的时间复杂度为O(n^3),可以求多源最短路问题. 2.思想: Floyd算法的基本思想如下:从任意节点A到任意节点 ...
- 用户体验 | 寻找成套的 App SDK 服务
前言 对于开发者来说,三方 SDK 这个词已经是一个不需要任何解释的词语了,然而我想面对琳琅满目的 SDK 产品,大家都会纠结如何选择.那么选择一个 SDK 需要注意哪些问题呢? SDK 的 稳定易用 ...
- Python [目录]
[第一篇] Python 发展历史 [第二篇] Python 优缺点 [第三篇] Python 应用场景 [第四篇] Python Hello World程序 [第五篇] Python 基础知识 [第 ...
- 解决百度BMR的spark集群开启slaves结点的问题
前言 最近一直忙于和小伙伴倒腾着关于人工智能的比赛,一直都没有时间停下来更新更新我的博客.不过在这一个过程中,遇到了一些问题,我还是记录了下来,等到现在比较空闲了,于是一一整理出来写成博客.希望对于大 ...
- 对接第三方平台JAVA接口问题推送和解决
前言 本节所讲为实际项目中与第三方对接出现的问题最后还是靠老大解决了问题以此作为备忘录,本篇分为三小节,一小节解析Java加密接口数据,二小节解析XML文件需注意问题,最后一节则是请求Java Soa ...
- php中自动加载类_autoload()和spl_autoload_register()实例详解
一._autoload 自动加载类:当我们实例化一个未定义的类时,就会触此函数.到了php7.1以后版本不支持此函数好像抛弃了 新建一个类文件名字自己随便去:news类在auto.php文件里面去实例 ...
- sqlte3 的约束
约束是在表的数据列上强制执行的规则.这些是用来限制可以插入到表中的数据类型.这确保了数据库中数据的准确性和可靠性. 约束可以是列级或表级.列级约束仅适用于列,表级约束被应用到整个表. 以下是在 SQL ...
- 手工释放linux内存——/proc/sys/vm/drop_caches
--手工释放linux内存——/proc/sys/vm/drop_caches 总有很多朋友对于Linux的内存管理有疑问,之前一篇日志似乎也没能清除大家的疑虑.而在新版核心中,似乎对这个问题提供了新 ...
- centos 7.2 配置Nginx
1.添加资源 添加CentOS 7 Nginx yum资源库,打开终端,使用以下命令(没有换行): rpm -Uvh http://nginx.org/packages/centos/7/noarch ...