4.kafka生产者---向Kafka中写入数据(转)
转: https://www.cnblogs.com/sodawoods-blogs/p/8969513.html
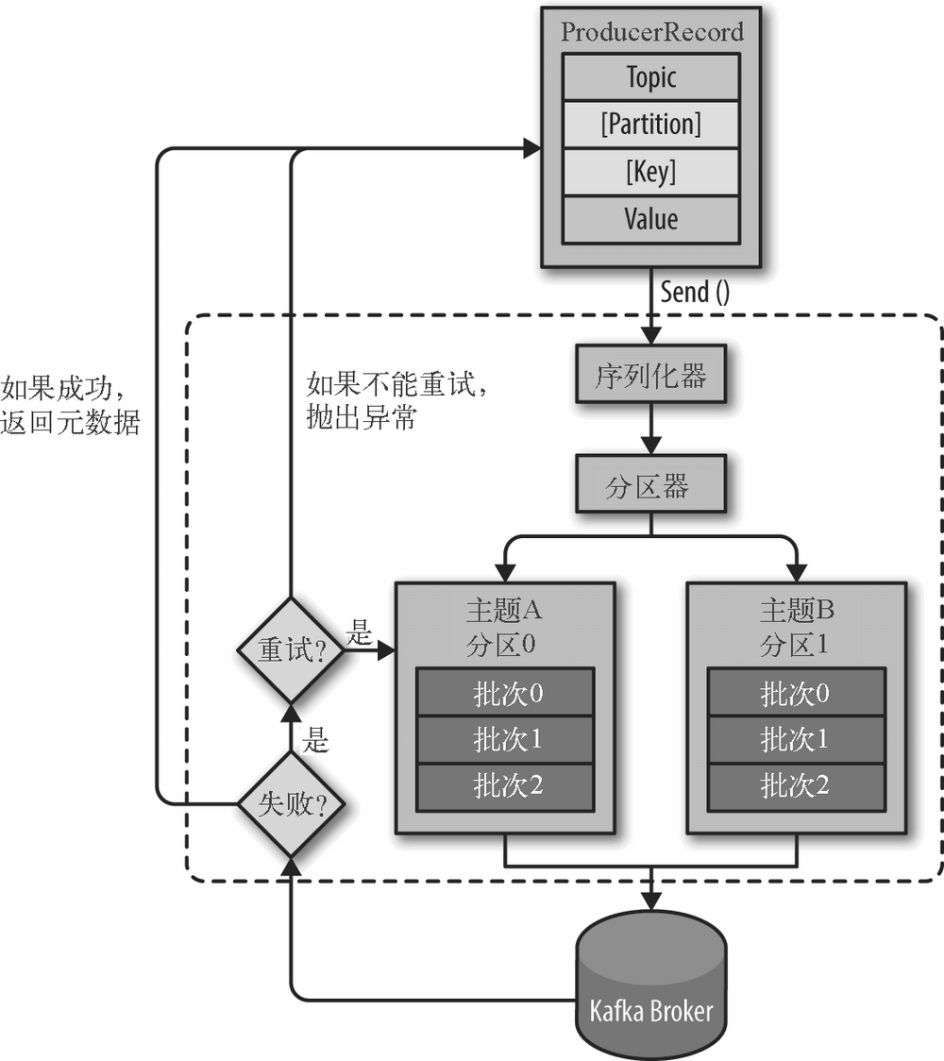
(1)生产者概览
(1)不同的应用场景对消息有不同的需求,即是否允许消息丢失、重复、延迟以及吞吐量的要求。不同场景对Kafka生产者的API使用和配置会有直接的影响。
例子1:信用卡事务处理系统,不允许消息的重复和丢失,延迟最大500ms,对吞吐量要求较高。
例子2:保存网站的点击信息,允许少量的消息丢失和重复,延迟可以稍高(用户点击链接可以马上加载出页面即可),吞吐量取决于用户使用网站的频度。
(2)Kafka发送消息的主要步骤
消息格式:每个消息是一个ProducerRecord对象,必须指定消息所属的Topic和消息值Value,此外还可以指定消息所属的Partition以及消息的Key。
1:序列化ProducerRecord
2:如果ProducerRecord中指定了Partition,则Partitioner不做任何事情;否则,Partitioner根据消息的key得到一个Partition。这是生产者就知道向哪个Topic下的哪个Partition发送这条消息。
3:消息被添加到相应的batch中,独立的线程将这些batch发送到Broker上
4:broker收到消息会返回一个响应。如果消息成功写入Kafka,则返回RecordMetaData对象,该对象包含了Topic信息、Patition信息、消息在Partition中的Offset信息;若失败,返回一个错误
(3)Kafka的顺序保证。Kafka保证同一个partition中的消息是有序的,即如果生产者按照一定的顺序发送消息,broker就会按照这个顺序把他们写入partition,消费者也会按照相同的顺序读取他们。
例子:向账户中先存100再取出来 和 先取100再存进去是完全不同的,因此这样的场景对顺序很敏感。
如果某些场景要求消息是有序的,那么不建议把retries设置成0,。可以把max.in.flight.requests.per.connection设置成1,会严重影响生产者的吞吐量,但是可以保证严格有序。
(2)创建Kafka生产者
要往Kafka中写入消息,需要先创建一个Producer,并设置一些属性。
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "broker1:port1, broker2:port2");
kafkaProps.put("key.serializer", "org.apache.kafka.common.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.StringSerializer");
producer = new KafkaProducer<String, String>(kafkaProps);
Kafka的生产者有如下三个必选的属性:
(1)bootstrap.servers,指定broker的地址清单
(2)key.serializer必须是一个实现org.apache.kafka.common.serialization.Serializer接口的类,将key序列化成字节数组。注意:key.serializer必须被设置,即使消息中没有指定key。
(3)value.serializer,将value序列化成字节数组
(3)发送消息到Kafka
(1)同步发送消息
ProducerRecord<String, String> record = new ProducerRecord<>("CustomCountry", "Precision Products", "France");//Topic Key Value
try{
Future future = producer.send(record);
future.get();//不关心是否发送成功,则不需要这行。
} catch(Exception e) {
e.printStackTrace();//连接错误、No Leader错误都可以通过重试解决;消息太大这类错误kafkaProducer不会进行任何重试,直接抛出异常
}
(2)异步发送消息
ProducerRecord<String, String> record = new ProducerRecord<>("CustomCountry", "Precision Products", "France");//Topic Key Value
producer.send(record, new DemoProducerCallback());//发送消息时,传递一个回调对象,该回调对象必须实现org.apahce.kafka.clients.producer.Callback接口
private class DemoProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {//如果Kafka返回一个错误,onCompletion方法抛出一个non null异常。
e.printStackTrace();//对异常进行一些处理,这里只是简单打印出来
}
}
}
(4)生产者的配置
(1)acks指定必须要有多少个partition副本收到消息,生产者才会认为消息的写入是成功的。
acks=0,生产者不需要等待服务器的响应,以网络能支持的最大速度发送消息,吞吐量高,但是如果broker没有收到消息,生产者是不知道的
acks=1,leader partition收到消息,生产者就会收到一个来自服务器的成功响应
acks=all,所有的partition都收到消息,生产者才会收到一个服务器的成功响应
(2)buffer.memory,设置生产者内缓存区域的大小,生产者用它缓冲要发送到服务器的消息。
(3)compression.type,默认情况下,消息发送时不会被压缩,该参数可以设置成snappy、gzip或lz4对发送给broker的消息进行压缩
(4)retries,生产者从服务器收到临时性错误时,生产者重发消息的次数
(5)batch.size,发送到同一个partition的消息会被先存储在batch中,该参数指定一个batch可以使用的内存大小,单位是byte。不一定需要等到batch被填满才能发送
(6)linger.ms,生产者在发送消息前等待linger.ms,从而等待更多的消息加入到batch中。如果batch被填满或者linger.ms达到上限,就把batch中的消息发送出去
(7)max.in.flight.requests.per.connection,生产者在收到服务器响应之前可以发送的消息个数
(5)序列化器
在创建ProducerRecord时,必须指定序列化器,推荐使用序列化框架Avro、Thrift、ProtoBuf等,不推荐自己创建序列化器。
在使用 Avro 之前,需要先定义模式(schema),模式通常使用 JSON 来编写。
(1)创建一个类代表客户,作为消息的value
class Custom {
private int customID;
private String customerName;
public Custom(int customID, String customerName) {
super();
this.customID = customID;
this.customerName = customerName;
}
public int getCustomID() {
return customID;
}
public String getCustomerName() {
return customerName;
}
}
(2)定义schema
{
"namespace": "customerManagement.avro",
"type": "record",
"name": "Customer",
"fields":[
{
"name": "id", "type": "string"
},
{
"name": "name", "type": "string"
},
]
}
(3)生成Avro对象发送到Kafka
Properties props = new Properties();
props.put("bootstrap", "loacalhost:9092");
props.put("key.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer");
props.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer");
props.put("schema.registry.url", schemaUrl);//schema.registry.url指向射麻的存储位置
String topic = "CustomerContacts";
Producer<String, Customer> produer = new KafkaProducer<String, Customer>(props); //不断生成消息并发送
while (true) {
Customer customer = CustomerGenerator.getNext();
ProducerRecord<String, Customer> record = new ProducerRecord<>(topic, customer.getId(), customer);
producer.send(record);//将customer作为消息的值发送出去,KafkaAvroSerializer会处理剩下的事情
}
(6)Partition
ProducerRecord可以只包含Topic和消息的value,key默认是null,但是大多数应用程序会用到key,key的两个作用:
(1)作为消息的附加信息
(2)决定消息该被写到Topic的哪个partition,拥有相同key的消息会被写到同一个partition。
如果key为空,kafka使用默认的partitioner,使用RoundRobin算法将消息均衡地分布在各个partition上;
如果key不为空,kafka使用自己实现的hash方法对key进行散列,相同的key被映射到相同的partition中。只有在不改变partition数量的前提下,key和partition的映射才能保持不变。
kafka也支持用户实现自己的partitioner,用户自己定义的paritioner需要实现Partitioner接口。
4.kafka生产者---向Kafka中写入数据(转)的更多相关文章
- ambari 修改kafka日志目录后,写入数据无法消费
## 起因:ambari 修改kafka日志目录后,写入数据无法消费 - 使用下面的客户端消费命令可以消费到数据 ./kafka-console-consumer.sh --zookeeper 192 ...
- 向post请求中写入数据,最终保存在了HttpWebRequest.Params中
一.向post请求中写入数据,最终保存在了HttpWebRequest.Params中: 1)如果存入的是IDictionary类型的字符串变量,如:“username=administrator”, ...
- PHP连接sqlserver的两种方法,向sqlserver2000中写入数据,中文乱码
项目环境是php5.3.28 项目用的ThinkPHP3.2.3 已经mysql5.5数据库,要和另一个项目对接,需要连接sqlsever2000数据库进行一些操作. 第一种用php自带扩展连接数据 ...
- 通过I2C总线向EEPROM中写入数据,记录开机次数
没买板子之前,用protues画过电路图,实现了通过i2c总线向EEPROM中写入和读出数据. 今天,在自己买的板子上面写关于i2c总线的程序,有个地方忘了延时,调程序的时候很蛋疼.下面说说我对I2c ...
- 【转】从QDataStream向QByteArray中写入数据时的注意点(QT)
最近发现从QDataStream向QByteArray中写入数据常常是写不进去的,通过查看QT的源码: QDataStream &operator>>(QDataStream &a ...
- POI往word模板中写入数据
转: POI往word模板中写入数据 2018年03月24日 16:00:22 乄阿斗同學 阅读数:2977 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn ...
- Verilog利用$fdisplay命令往文件中写入数据
最近在做的事情是,用FPGA生成一些满足特定分布的序列.因此为了验证我生成的序列是否拥有预期的性质,我需要将生成的数据提取出来并且放到MATLAB中做数据分析. 但是网上的程序很乱,表示看不懂==其实 ...
- 复制excel表,往excel表中写入数据
import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;import jav ...
- POI向Excel中写入数据及追加数据
import org.apache.poi.xssf.usermodel.XSSFCell; import org.apache.poi.xssf.usermodel.XSSFRow; import ...
- 计算机二级-C语言-程序填空题-190117记录-对文件的处理,复制两个文件,往新文件中写入数据。
//给定程序的功能是,调用函数fun将指定源文件中的内容赋值到指定目标文件中,复制成功时函数返回1,失败时返回0,把复制的内容输出到终端屏幕.主函数中源文件名放在变量sfname中,目标文件名放在变量 ...
随机推荐
- 基于python的App UI自动化环境搭建
Android端Ui 自动化环境搭建 一,安装JDK.SDK 二,添加环境变量 Widows:1.系统变量→新建 JAVA_HOME 变量E:\Java\jdk1.7.0 jdk安装目录 2.系统变量 ...
- 使用Docker-Compose编排发布.Net Core+Redis应用两个镜像到Docker
对于刚刚完成的Alipay支的Demo, 我想要把它部署到Docker中去, 下面我来演示相关步骤. 创建配置文件 配置文件的重中之重是Dockerfile, 他的内容如下: # 第一部分是编译并发布 ...
- LeetCode 665. 非递减数列(Non-decreasing Array)
665. 非递减数列 665. Non-decreasing Array 题目描述 给定一个长度为 n 的整数数组,你的任务是判断在最多改变 1 个元素的情况下,该数组能否变成一个非递减数列. 我们是 ...
- torch.Tensor和numpy.ndarray
1. torch.Tensor和numpy.ndarray相互转换 import torch import numpy as np # <class 'numpy.ndarray'> np ...
- SPA中使用jwt
什么是jwt? JSON Web Token (JWT),它是目前最流行的跨域身份验证解决方案 JWT的工作原理 1. 是在服务器身份验证之后,将生成一个JSON对象并将其发送回用户,示例如下:{&q ...
- Spring Boot集成Junit测试
添加依赖: 在测试类上添加注解:
- Ubuntu Server Swap 分区设置
方案一:仅在内存耗尽的情况下才使用 swap 分区 # 首先进入 sudo 模式 sysctl vm.swappiness=0 # 临时生效 echo "vm.swappiness = 0& ...
- Mysql union和union all用法
1: 什么时候用union和union all ? 我们经常会碰到这样的应用,两个表的数据按照一定的查询条件查询出来以后,需要将结果合并到一起显示出来,这个时候 就需要用到union和union ...
- 【css】文本效果
一.字体属性 在css字体样式中常见的字体属性有以下几种 p{ font-size: 50px; /*字体大小*/ line-height: 30px; /*行高*/ font-family: 幼圆, ...
- c#使用GDI进行简单的绘图
https://www.2cto.com/database/201805/749421.html https://zhidao.baidu.com/question/107832895.html pr ...