大数据之路week06--day07(完全分布式Hadoop的搭建)
前提工作:
克隆2台虚拟机完成后:新的2台虚拟机,请务必依次修改3台虚拟机的ip地址和主机名称【建议三台主机名称依次叫做:master、node1、node2 】 上一篇博客
(三台虚拟机都要开机)
Hadoop2.6.0 的压缩包,这里我提供百度云,没有的可以进行下载
链接:https://pan.baidu.com/s/1euN5AwSHHP-mqz4U_6ldEQ
提取码:jh1m
1、设置主机名与ip的映射,修改配置文件命令:vi /etc/hosts
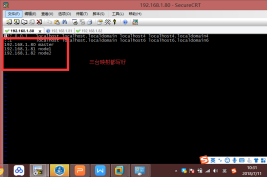
2、将hosts文件拷贝到node1和node2节点
命令:
scp /etc/hosts node1:/etc/hosts
scp /etc/hosts node2:/etc/hosts
3、上述修改完成后,请依次重启三台虚拟机:重启命令:reboot
4、关闭防火墙(三台都要操作),使用命令:service iptables stop
5、关闭防火墙的自动启动(三台都要操作),使用命令:chkconfig iptables off
6、设置ssh免密码登录(只在Master 这台主机操作)
主节点执行命令 ssh-keygen -t rsa 产生密钥 一直回车
执行命令
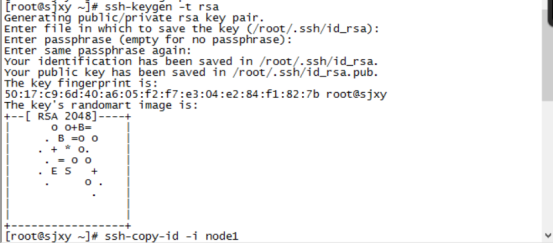
7、将密钥拷贝到其他两个子节点,命令如下:
ssh-copy-id -i node1
ssh-copy-id -i node2
实现免密码登录到子节点。
8、实现主节点master本地免密码登录
首先进入到/root 命令:cd /root
再进入进入到 ./.ssh目录下
命令:cd ./.ssh/

9、然后将公钥写入本地执行命令:
cat ./id_rsa.pub >> ./authorized_keys
如图

--------------------------------------------------------------------------以下操作都在master上进行-----------------------------------------------------------------------------------------------------------------------
10、将hadoop的jar包先上传到虚拟机/usr/local/soft目录下,主节点。可以使用xshell拖拽

11、解压。tar -zxvf hadoop-2.6.0.tar.gz 解压完后会出现 hadoop-2.6.0的目录

12、修改master中hadoop的一个配置文件/usr/local/soft/etc/hadoop/slaves
删除原来的所有内容,修改为如下(你的节点名称)
node1
node2

13、修改hadoop的几个组件的配置文件 进入cd /usr/local/soft/hadoop-2.6.0/etc/hadoop 目录下(请一定要注意配置文件内容的格式,可以直接复制过去黏贴。不要随意改 !!!!!!!!)
* 修改hadoop-env.sh文件
加上一句:
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171 (自己的jdk路径)

14、修改 core-site.xml
将下面的配置参数加入进去修改成对应自己的
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value> //这里的master是我的主机名
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.6.0/tmp</value> //你的Hadoop路径
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
15、修改 hdfs-site.xml 将dfs.replication设置为1 (因为我这里就只有一个主节点和两个子节点)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
16、修改文件yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value> //你的主机名
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
17、(将mapred-site.xml.template 复制一份为 mapred-site.xml
命令:cp mapred-site.xml.template mapred-site.xml) 然后修改 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value> //我的主节点名字叫master
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value> //我的主节点名字叫master
</property>
</configuration>
18、将hadoop的安装目录分别拷贝到其他子节点
scp -r /usr/local/soft/hadoop-2.6.0 node1:/usr/local/soft/
scp -r /usr/local/soft/hadoop-2.6.0 node2:/usr/local/soft/
19、启动hadoop
首先看下hadoop-2.6.0目录下有没有tmp文件夹。
如果没有 执行一次格式化命令:
cd /usr/local/soft/hadoop-2.6.0目录下
执行命令:
./bin/hdfs namenode -format
会生成tmp文件。
20、/usr/local/soft/hadoop-2.6.0目录下
启动执行:./sbin/start-all.sh
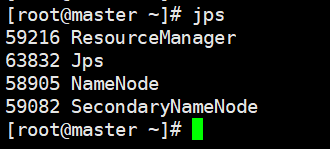
21、启动完成后通过jps命令查看验证进程:jps
主节点进程为下面几个(下面是进程名称,不是命令):
Namenode
secondarnamenode
resourcemanager
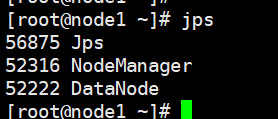
22、子节点进程 (在node1和node2上分别输入命令:jps)
datanode
nodenodemanager
23、验证hdfs:
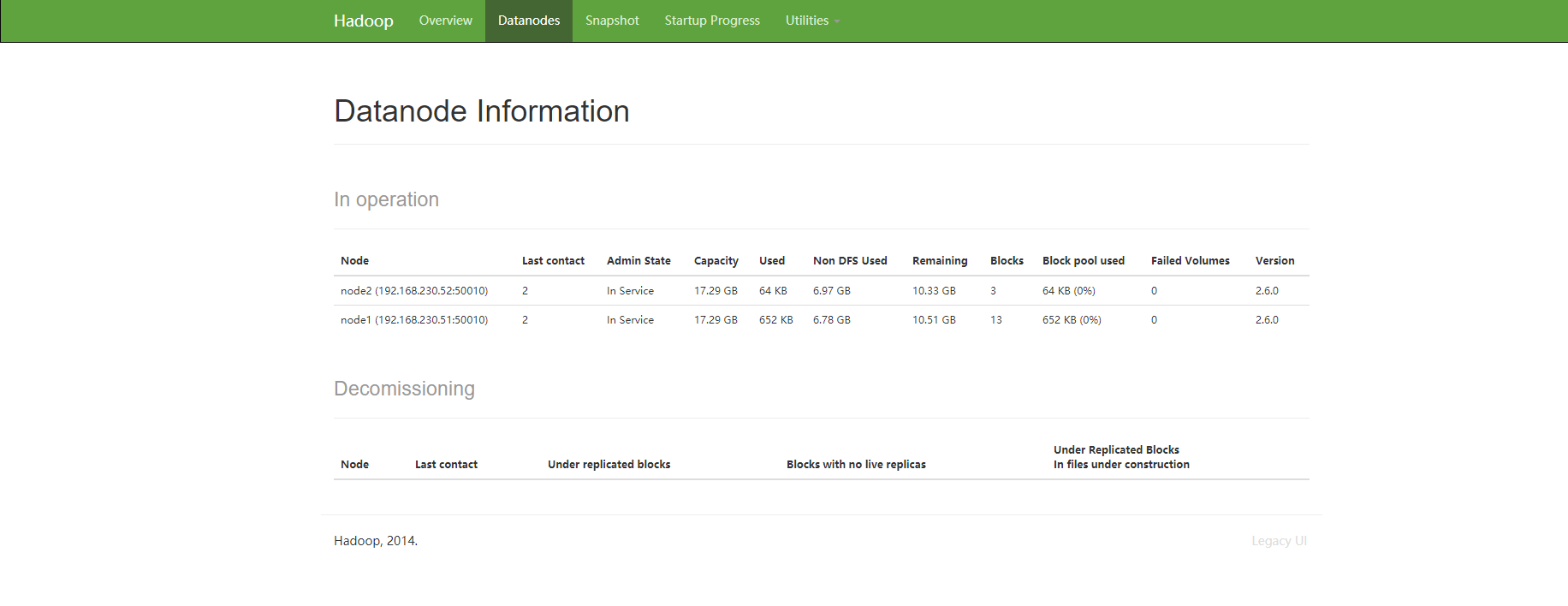
可以windows电脑登录浏览器(强烈建议chrome浏览器)
地址:192.168.1.80:50070 (ip地址是master的地址)
看到下面页面证明 hdfs装好了
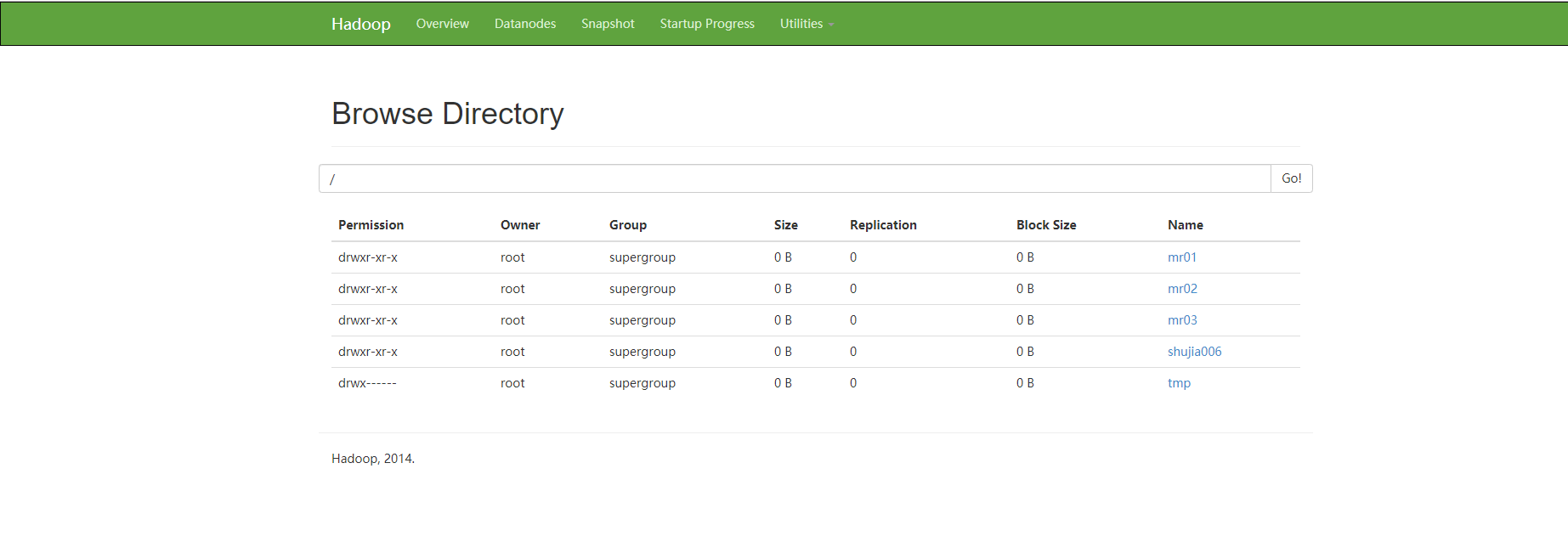
下图是我已经创建了一个hdfs上的目录,刚装好的hadoop应该是空的什么都没有
******* 如果第一次启动失败了,请重新检查配置文件或者哪里步骤少了。
再次重启的时候
1需要手动将每个节点的tmp目录删除:
rm -rf /usr/local/soft/hadoop-2.6.0/tmp
然后执行将namenode格式化
2在主节点执行命令:
./bin/hdfs namenode -format

如果在put文件的过程中出现了_COPYING_ could only be replicated to 0 nodes instead of minReplication (=1).
的报错
1 格式化重来
2 如果不行,看下时间,防火墙
3 修改 hosts文件,把里面那两条删了
大数据之路week06--day07(完全分布式Hadoop的搭建)的更多相关文章
- 大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)
什么是Hive? 我来一个短而精悍的总结(面试常问) 1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark). 2:hive可以使用类sql方言,对存储在hdfs上的数据进 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- 胖子哥的大数据之路(6)- NoSQL生态圈全景介绍
引言: NoSQL高级培训课程的基础理论篇的部分课件,是从一本英文原著中做的摘选,中文部分参考自互联网.给大家分享. 正文: The NoSQL Ecosystem 目录 The NoSQL Eco ...
- 大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃. MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几 ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- 大数据之路week04--day06(I/O流阶段一 之异常)
从这节开始,进入对I/O流的系统学习,I/O流在往后大数据的学习道路上尤为重要!!!极为重要,必须要提起重视,它与集合,多线程,网络编程,可以说在往后学习或者是工作上,起到一个基石的作用,没了地基,房 ...
- C#码农的大数据之路 - 使用C#编写MR作业
系列目录 写在前面 从Hadoop出现至今,大数据几乎就是Java平台专属一般.虽然Hadoop或Spark也提供了接口可以与其他语言一起使用,但作为基于JVM运行的框架,Java系语言有着天生优势. ...
- 胖子哥的大数据之路(11)-我看Intel&&Cloudera的合作
一.引言 5月8日,作为受邀嘉宾,参加了Intel与Cloudera在北京中国大饭店新闻发布会,两家公司宣布战略合作,该消息成为继Intel宣布放弃大数据平台之后的另外一个热点新闻.对于Intel的放 ...
- 胖子哥的大数据之路(10)- 基于Hive构建数据仓库实例
一.引言 基于Hive+Hadoop模式构建数据仓库,是大数据时代的一个不错的选择,本文以郑商所每日交易行情数据为案例,探讨数据Hive数据导入的操作实例. 二.源数据-每日行情数据 三.建表脚本 C ...
随机推荐
- 使用Maven为SpringBoot项目打包
一.maven通过命令行打jar包 进入项目目录,执行如下命令: mvn -Dmaven.test.skip -U clean package 发现报如下错误: [ERROR] Failed to e ...
- Django 操作已经存在的数据库
反向操作数据库 何为反向操作.即是数据库在项目之前已经存在,不需要新建表,操作已经存在的表 # 进入站点目录下执行 python manage.py inspectdb #可以看到settings中连 ...
- 任务调度之Quartz.Net基础
最近公司要求将之前的系统设计文档补上,于是大家就都被分配了不同的任务,紧锣密鼓的写起了文档来.发现之前项目中使用了Quartz.Net来做一些定时任务的调度,比如定时的删除未支付的订单,定时检查支付状 ...
- win10 linux Ubuntu 18.04更换国内源
安装了win10的linux bash 版本为ubuntu 18.04 首先查询自己的linux版本信息 cat /etc/issue 然后对系统的镜像源文件进行备份,再修改镜像源文件/etc/a ...
- [Xamarin] - 连接 Mac Agent 显示 "couldn't connect to xxxx, please try again" 之解决
背景 在 VS 2017 的 Xamarin 项目中,配置 Mac Agent 连接到本地虚拟机中的 MacOS 失败. 1. MacOS 已启用远程登陆.2. SSH 可以登陆成功.3. 防火墙已关 ...
- as报错 Multiple root tags Unexpected tokens 这个都是编译器识别问题
从网上复制了个代码,直接复制上,结果一篇红线提示Unexpected tokens 通过去掉空格,还是无法根治,别的地方复制的就没有问题. 通过查看复制的网页源码 可以看到里边<> 这个符 ...
- 题解 Luogu P1099 【树网的核】
这题是真的水啊... ------------ 昨天模拟赛考了这题,很多人都是O($n^3$)水过,但我认为,要做就做的足够好(其实是我根本没想到O($n^3$)的做法),然后就开始想O(n)的解法. ...
- Pycharm(Eclipse)常用快捷键
在File_Settings_Keymap中可以设置: 确定快捷键模式为Eclipse 看方法的源码:ctrl+鼠标左键 回退之前代码:alt+左键 前进之前代码:alt+右键 调换相邻两行代码位置: ...
- PB笔记之调用数据窗口时的过滤条件添加方式
在PB查询数据窗口的数据时 通常可以有两种方式 一是在数据窗口事先写好查询条件,然后用retrieve()函数通过参数传递给数据窗口 这种方式适合查询条件较为简单,条件数较少的数据窗口 二是使用Set ...
- Luogu5400 CTS2019随机立方体(容斥原理)
考虑容斥,计算至少有k个极大数的概率.不妨设这k个数对应的格子依次为(k,k,k)……(1,1,1).那么某一维坐标<=k的格子会对这些格子是否会成为极大数产生影响.先将这样的所有格子和一个数集 ...