Windows 下部署 hadoop spark环境
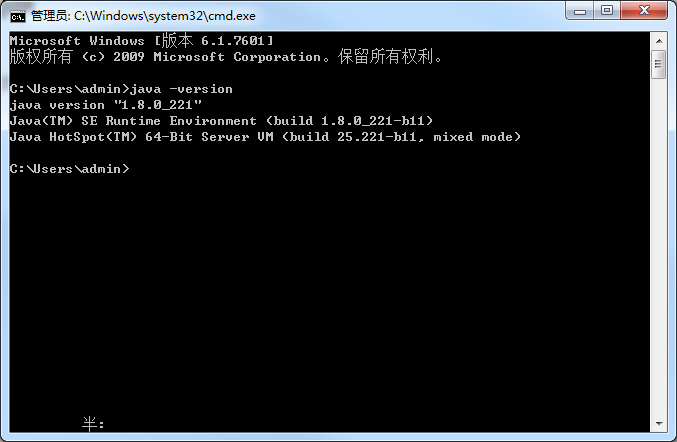
一、先在本地安装jdk
我这里安装的jdk1.8,具体的安装过程这里不作赘述
二、部署安装maven
下载maven安装包,并解压
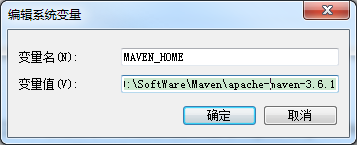
设置环境变量,MAVEN_HOME=D:\SoftWare\Maven\apache-maven-3.6.1
在path路径添加;%MAVEN_HOME%\bin
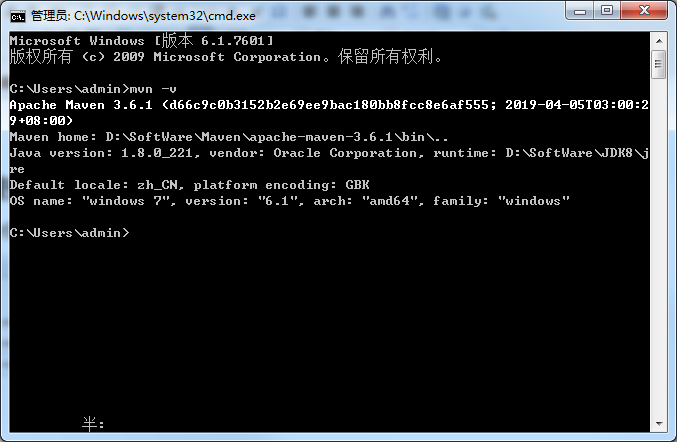
打开本地终端验证
三、安装hadoop
先下载hadoop压缩包 下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/
下载后解压到本地
配置环境变量
计算机 –>属性 –>高级系统设置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME
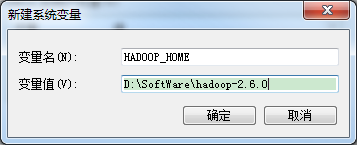
HADOOP_HOME=D:\SoftWare\hadoop-2.6.0
Path环境变量下配置【%HADOOP_HOME%\bin;】变量
打开终端验证一下hadoop是否安装成功

给hadoop添加插件,添加到hadoop/bin目录下

修改hadoop的配置文件,配置文件在路径D:\SoftWare\hadoop-2.6.0\etc\hadoop下
修改core-site.xml

<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property> <!--用来指定hadoop产生临时文件的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/SoftWare/hadoop-2.6.0/tmp/</value>
</property> <!--用于设置检查点备份日志的最长时间-->
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
</configuration>
修改hdfs-site.xml
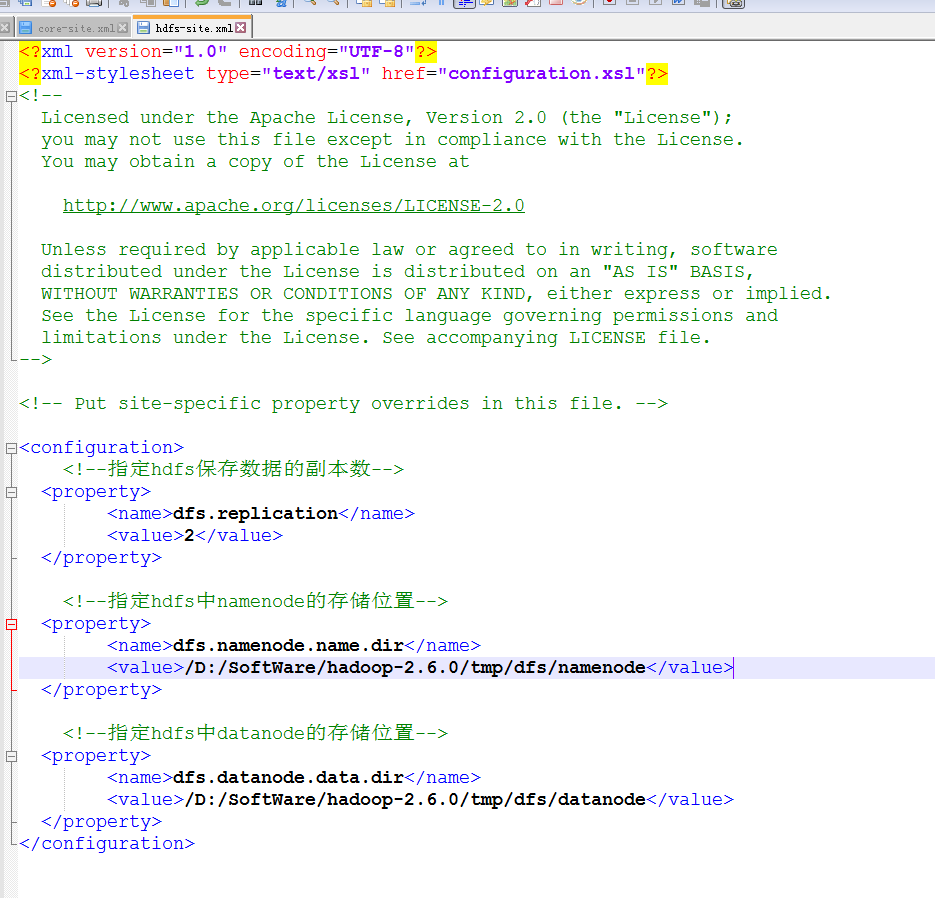
<configuration>
<!--指定hdfs保存数据的副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property> <!--指定hdfs中namenode的存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/SoftWare/hadoop-2.6.0/tmp/dfs/namenode</value>
</property> <!--指定hdfs中datanode的存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/SoftWare/hadoop-2.6.0/tmp/dfs/datanode</value>
</property>
</configuration>
修改mapred-site.xml
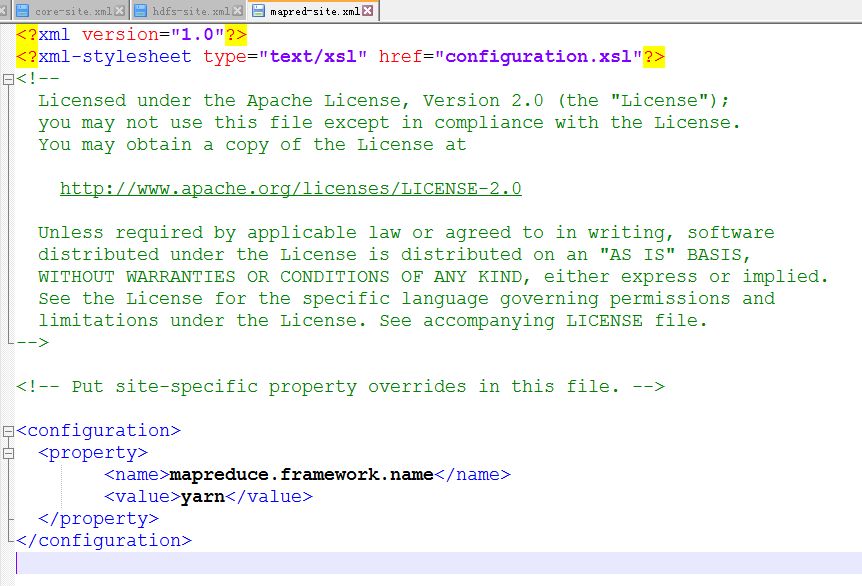
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
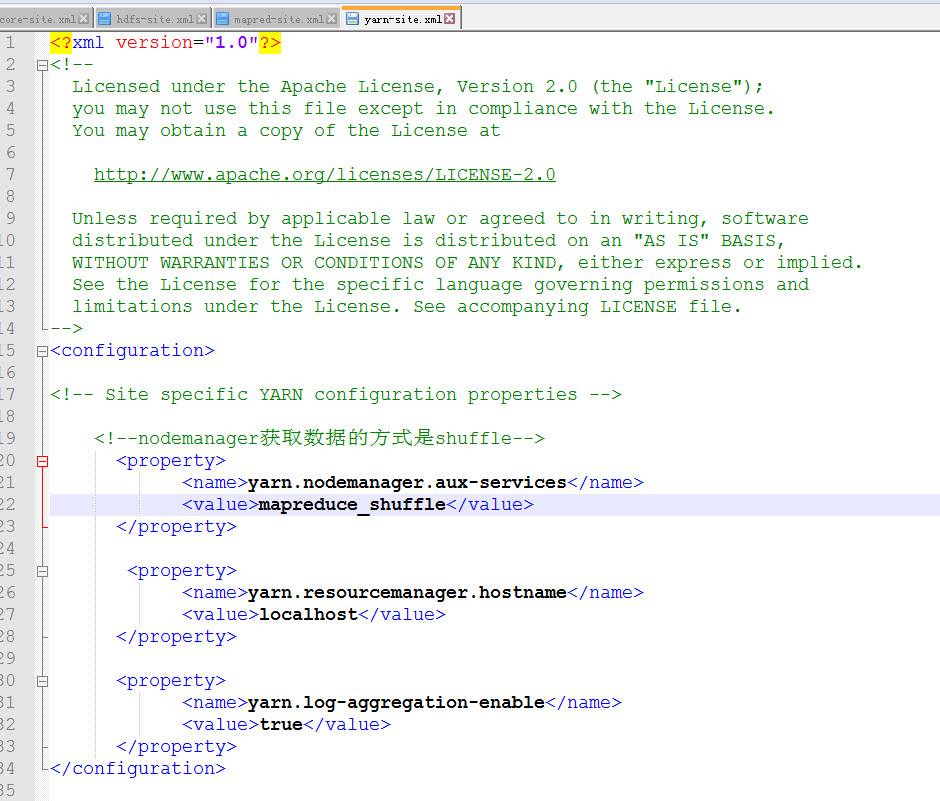
<configuration>
<!-- Site specific YARN configuration properties -->
<!--nodemanager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
格式化系统文件
hadoop/bin下执行 hdfs namenode -format

格式化完毕后启动hadoop,到hadoop/sbin下执行 start-dfs启动hadoop

这个时候会自动打开另外两个终端窗口,日志没有报错就行了,
打开浏览器访问 http://localhost:50070

启动yarn
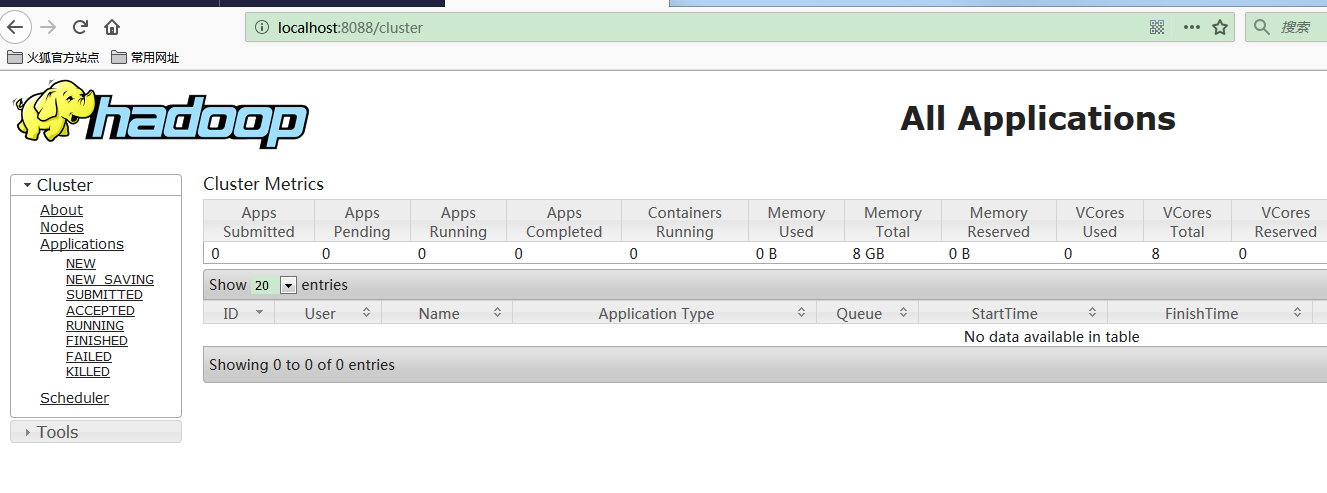
打开浏览器访问 http://localhost:8088
在hdfs创建文件夹

把本地的文本文件上传到hdfs


然后运行hadoop 提供的demo,计算单词数
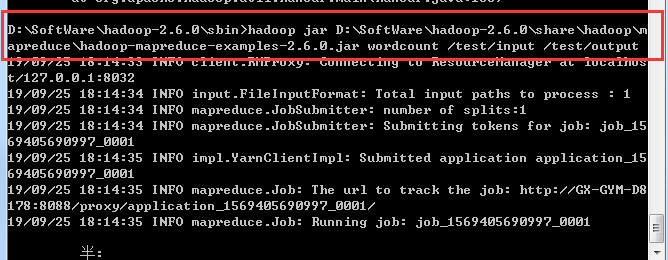

四、安装scala
下载scala的安装包到本地
双击
选择安装的路径
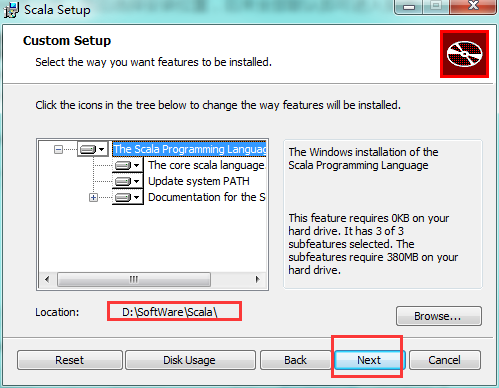

配置scala的环境变量
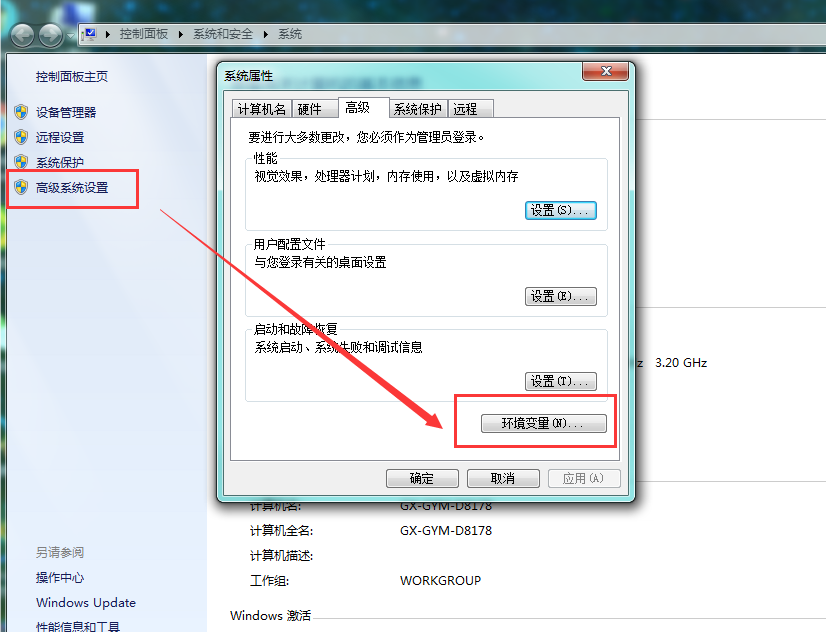
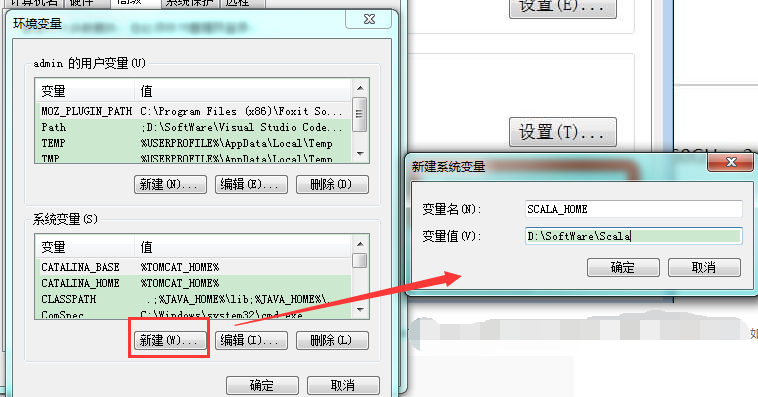
设置 Path 变量:找到系统变量下的"Path"如图,单击编辑。在"变量值"一栏的最前面添加如下的路径: %SCALA_HOME%\bin;%SCALA_HOME%\jre\bin;

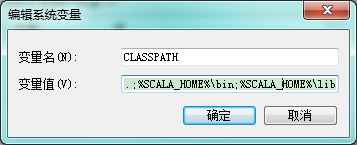
设置 Classpath 变量:找到找到系统变量下的"Classpath"如图,单击编辑,如没有,则单击"新建":
- "变量名":ClassPath
- "变量值":.;%SCALA_HOME%\bin;%SCALA_HOME%\lib\dt.jar;%SCALA_HOME%\lib\tools.jar.;
检查环境变量是否设置好了:调出"cmd"检查。单击 【开始】,在输入框中输入cmd,然后"回车",输入 scala,然后回车,如环境变量设置ok,你应该能看到这些信息

五、安装spark
下载安装包

解压到需要安装的路径下
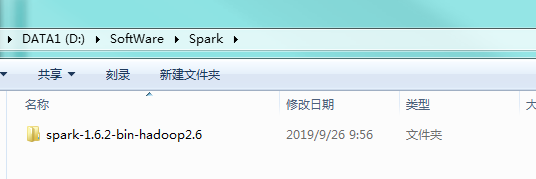
配置spark的环境变量
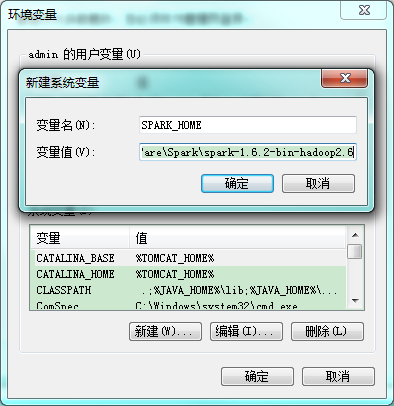
将spark的bin路径添加到path中
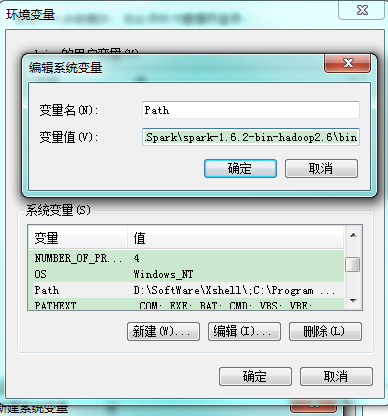
cmd输入spark-shell
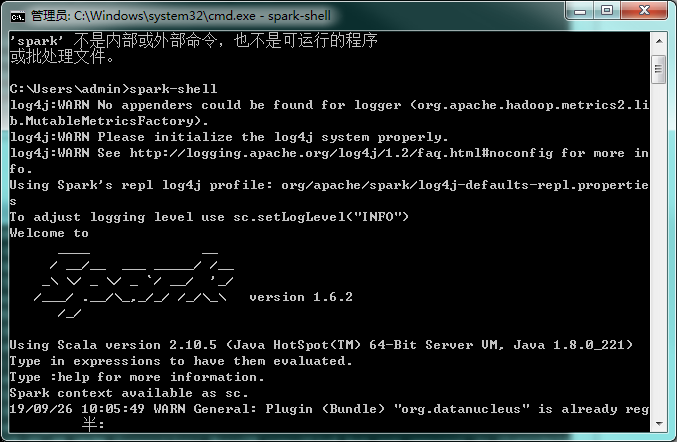
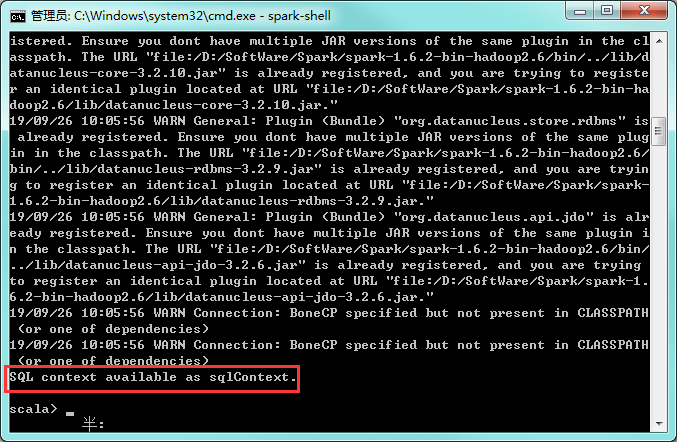
spark已经安装成功了!
六、在IDEA添加scala插件

Windows 下部署 hadoop spark环境的更多相关文章
- 在 Windows 下部署 Go 语言环境
http://bbs.chinaunix.net/thread-4088281-1-1.html 1. 首先下载官方二进制安装包:32 位选择 windows-386.msi64 位选择 window ...
- Windows下运行Hadoop
Windows下运行Hadoop,通常有两种方式:一种是用VM方式安装一个Linux操作系统,这样基本可以实现全Linux环境的Hadoop运行:另一种是通过Cygwin模拟Linux环境.后者的好处 ...
- Windows下ELK-5.4.3环境搭建
Windows下ELK-5.4.3环境搭建 一.概述 ELK官网 https://www.elastic.co ELK由Elasticsearch.Logstash和Kibana三部分组件组成: El ...
- Windows上搭建hadoop开发环境
前言 Windows下运行Hadoop,通常有两种方式:一种是用VM方式安装一个Linux操作系统,这样基本可以实现全Linux环境的Hadoop运行:另一种是通过Cygwin模拟Linux环境.后者 ...
- QT程序在windows下部署发布
转载:http://www.cnblogs.com/Fan_Fan/archive/2010/05/29/1746860.html QT程序在windows下部署发布 以下包括了部分网上收集的,以及q ...
- 【1】windows下IOS开发基础环境搭建
一.目的 本文的目的是windows下IOS开发基础环境搭建做了对应的介绍,大家可根据文档步骤进行mac环境部署: 二.安装虚拟机 下载虚拟机安装文件绿色版,点击如下文件安装 获取安装包: ...
- Windows下部署ElasticSearch5.0以下版本
Windows下部署ElasticSearch分ElasticSearch5.0以上版本(包括5.0)和ElasticSearch5.0以下版本两种情况,这两种安装方式有很大不同.今天首先说Elast ...
- Windows配置本地Hadoop运行环境
很多人喜欢用Windows本地开发Hadoop程序,这里是一个在Windows下配置Hadoop的教程. 首先去官网下载hadoop,这里需要下载一个工具winutils,这个工具是编译hadoop用 ...
- linux centos7 和 windows下 部署 .net core 2.0 web应用
centos7 下部署asp.net core 2.0应用 安装CentOS7 配置网络[可选] 安装.Net core2.0 创建测试Asp.net Core应用程序 正式部署项目 安装VMware ...
随机推荐
- luogu 1373 小a和uim之大逃离 dp
有取模操作,所以直接维护模意义下的差即可. Code: #include <bits/stdc++.h> #define M 16 #define N 801 #define ll lon ...
- 【csp模拟赛5】加减法--宽搜维护联通快
题目大意: 一开始想用并查集,发现很难维护联通块的代表元素,所以用了宽搜,开数组会炸,所以开一个优先队列维护,每扫完一个联通块,统计答案,清空优先队列,!!千万记住注意数组的大小!!! 代码: #in ...
- Django-cookie-sesson
一 会话跟踪 我们需要先了解一下什么是会话!可以把会话理解为客户端与服务器之间的一次会晤,在一次会晤中可能会包含多次请求和响应.例如你给10086打个电话,你就是客户端,而10086服务人员就是服务器 ...
- Python爬虫 Urllib库的基本使用
1.构造Requset 其实上面的urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入Url,Data等等的内容.比如上面的两行代码,我们可以这么改写 ...
- vue实战教程
转载自 https://www.cnblogs.com/sunsets/p/7760454.html
- spark 常用函数介绍(python)
以下是个人理解,一切以官网文档为准. http://spark.apache.org/docs/latest/api/python/pyspark.html 在开始之前,我先介绍一下,RDD是什么? ...
- 解决vue中使用laydate.js选择日期后再修改其他model时日期会被清空问题
首先描述一下问题,下图中均绑定v-model,例如先选择出生开始时间,然后当再选择地区或其他选项时该时间就会被清空 首先看一下我这边开始的默认值,开始我设置都为空 当我选择如下图的生日开始时间与结束时 ...
- ORACLE数据库黑/白名单
编辑sqlnet.ora文件 #开启ip限制功能tcp.validnode_checking=yes#允许访问数据库的IP地址列表,多个IP地址使用逗号分开tcp.invited_nodes=(10. ...
- pycharm中模块不能导入的问题
在pycharm中发现模块老是导入不成功 只能以这样的映射的方式 现在才知道: 模块的标志符可以由字母.数字.下划线组成,但是, 不能以数字开头,如果在给python文件起名时,以数字开头是无法在py ...
- 1.4 Go语言基础之流程控制
流程控制是每种编程语言控制逻辑走向和执行次序的重要部分,流程控制可以说是一门语言的"经脉". Go语言中最常用的流程控制有if和for,而switch和goto主要是为了简化代码. ...