Hadoop_21_MapReduce程序实现Join功能
1.1.hadoop的序列化格式
序列化和反序列化就是结构化对象和字节流之间的转换,主要用在内部进程的通讯和持久化存储方面

2.reduce端join算法实现
1.需求:
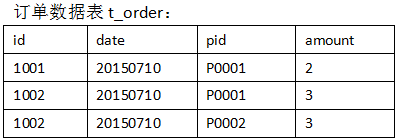
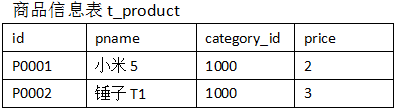
假如数据量巨大,两表的数据是以文件的形式存储在HDFS中,需要用mapreduce程序来实现以下SQL查询运算:
select a.id,a.date,b.name,b.category_id,b.price from t_order a join t_product b on a.pid = b.id
2.实现机制:
通过将关联的条件pid作为map输出的key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同
一个reducetask,在reduce中进行数据的串联
3.代码实现:
package cn.bigdata.mr.rjoin;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable; public class InfoBean implements Writable { private int order_id;
private String dateString;
private String p_id;
private int amount;
private String pname;
private int category_id;
private float price; // flag=0表示这个对象是封装订单表记录
// flag=1表示这个对象是封装产品信息记录
private String flag; public InfoBean() {
} public void set(int order_id, String dateString, String p_id, int amount, String pname, int category_id, float price, String flag) {
this.order_id = order_id;
this.dateString = dateString;
this.p_id = p_id;
this.amount = amount;
this.pname = pname;
this.category_id = category_id;
this.price = price;
this.flag = flag;
} public int getOrder_id() {
return order_id;
} public void setOrder_id(int order_id) {
this.order_id = order_id;
} public String getDateString() {
return dateString;
} public void setDateString(String dateString) {
this.dateString = dateString;
} public String getP_id() {
return p_id;
} public void setP_id(String p_id) {
this.p_id = p_id;
} public int getAmount() {
return amount;
} public void setAmount(int amount) {
this.amount = amount;
} public String getPname() {
return pname;
} public void setPname(String pname) {
this.pname = pname;
} public int getCategory_id() {
return category_id;
} public void setCategory_id(int category_id) {
this.category_id = category_id;
} public float getPrice() {
return price;
} public void setPrice(float price) {
this.price = price;
} public String getFlag() {
return flag;
} public void setFlag(String flag) {
this.flag = flag;
} /**
* private int order_id; private String dateString; private int p_id;
* private int amount; private String pname; private int category_id;
* private float price;
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeUTF(dateString);
out.writeUTF(p_id);
out.writeInt(amount);
out.writeUTF(pname);
out.writeInt(category_id);
out.writeFloat(price);
out.writeUTF(flag);
} @Override
public void readFields(DataInput in) throws IOException {
this.order_id = in.readInt();
this.dateString = in.readUTF();
this.p_id = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.category_id = in.readInt();
this.price = in.readFloat();
this.flag = in.readUTF(); } @Override
public String toString() {
return "order_id=" + order_id + ", dateString=" + dateString + ", p_id=" + p_id + ", amount=" + amount + ", pname=" + pname + ", category_id=" + category_id + ", price=" + price ;
}
}
package cn.bigdata.mr.rjoin;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 订单表和商品表合到一起
order.txt(订单id, 日期, 商品编号, 数量)
1001 20150710 P0001 2
1002 20150710 P0001 3
1002 20150710 P0002 3
1003 20150710 P0003 3
product.txt(商品编号, 商品名字, 价格, 数量)
P0001 小米5 1001 2
P0002 锤子T1 1000 3
P0003 锤子 1002 4
*/
public class RJoin { static class RJoinMapper extends Mapper<LongWritable, Text, Text, InfoBean> {
InfoBean bean = new InfoBean();
Text k = new Text(); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString(); FileSplit inputSplit = (FileSplit) context.getInputSplit();
String name = inputSplit.getPath().getName();
System.out.println("kkkkkkkkkkkkkkkkkkkkkk"+name);
// 通过文件名判断是哪种数据
String pid = "";
if (name.startsWith("order")) {
String[] fields = line.split(",");
// id date pid amount
pid = fields[];
bean.set(Integer.parseInt(fields[]), fields[], pid, Integer.parseInt(fields[]), "", , , ""); } else {
String[] fields = line.split(",");
// id pname category_id price
pid = fields[];
bean.set(, "", pid, , fields[], Integer.parseInt(fields[]), Float.parseFloat(fields[]), ""); }
k.set(pid);
context.write(k, bean);
}
} static class RJoinReducer extends Reducer<Text, InfoBean, InfoBean, NullWritable> { @Override
protected void reduce(Text pid, Iterable<InfoBean> beans, Context context) throws IOException, InterruptedException {
InfoBean pdBean = new InfoBean();
ArrayList<InfoBean> orderBeans = new ArrayList<InfoBean>(); for (InfoBean bean : beans) {
if ("".equals(bean.getFlag())) { //产品的
try {
BeanUtils.copyProperties(pdBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
} else {
InfoBean odbean = new InfoBean();
try {
BeanUtils.copyProperties(odbean, bean);
orderBeans.add(odbean);
} catch (Exception e) {
e.printStackTrace();
}
}
} // 拼接两类数据形成最终结果
for (InfoBean bean : orderBeans) { bean.setPname(pdBean.getPname());
bean.setCategory_id(pdBean.getCategory_id());
bean.setPrice(pdBean.getPrice()); context.write(bean, NullWritable.get());
}
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); conf.set("mapred.textoutputformat.separator", ","); Job job = Job.getInstance(conf); // 指定本程序的jar包所在的本地路径
// job.setJarByClass(RJoin.class);
// job.setJar("c:/join.jar"); job.setJarByClass(RJoin.class);
// 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(RJoinMapper.class);
job.setReducerClass(RJoinReducer.class); // 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(InfoBean.class); // 指定最终输出的数据的kv类型
job.setOutputKeyClass(InfoBean.class);
job.setOutputValueClass(NullWritable.class); // 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[]));
// 指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[])); // 将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/* job.submit(); */
boolean res = job.waitForCompletion(true);
System.exit(res ? : );
}
}
运行结果:
order_id=1002, dateString=20150710, p_id=P0001, amount=3, pname=sss, category_id=1001, price=2.0
order_id=1001, dateString=20150710, p_id=P0001, amount=2, pname=sss, category_id=1001, price=2.0
order_id=1002, dateString=20150710, p_id=P0002, amount=3, pname=111, category_id=1000, price=3.0
order_id=1003, dateString=20150710, p_id=P0003, amount=3, pname=www, category_id=1002, price=4.0
Hadoop_21_MapReduce程序实现Join功能的更多相关文章
- 为ASP.NET MVC应用程序使用高级功能
为ASP.NET MVC应用程序使用高级功能 这是微软官方教程Getting Started with Entity Framework 6 Code First using MVC 5 系列的翻译, ...
- 微信小程序开发-蓝牙功能开发
0. 前言 这两天刚好了解了一下微信小程序的蓝牙功能.主要用于配网功能.发现微信的小程序蓝牙API已经封装的很好了.编程起来很方便.什么蓝牙知识都不懂的情况下,不到两天就晚上数据的收发了,剩下的就是数 ...
- MySQL 的 join 功能弱爆了?
大家好,我是历小冰,今天我们来学习和吐槽一下 MySQL 的 Join 功能. 关于MySQL 的 join,大家一定了解过很多它的"轶事趣闻",比如两表 join 要小表驱动大表 ...
- Java基础-输入输出-3.编写BinIoDemo.java的Java应用程序,程序完成的功能是:完成1.doc文件的复制,复制以后的文件的名称为自己的学号姓名.doc。
3.编写BinIoDemo.java的Java应用程序,程序完成的功能是:完成1.doc文件的复制,复制以后的文件的名称为自己的学号姓名.doc. try { FileInputStream in = ...
- Java基础-输入输出-2.编写IoDemo.java的Java应用程序,程序完成的功能是:首先读取text.txt文件内容,再通过键盘输入文件的名称为iodemo.txt,把text.txt的内容存入iodemo.txt
2.编写IoDemo.java的Java应用程序,程序完成的功能是:首先读取text.txt文件内容,再通过键盘输入文件的名称为iodemo.txt,把text.txt的内容存入iodemo.txt ...
- JAVA基础-输入输出:1.编写TextRw.java的Java应用程序,程序完成的功能是:首先向TextRw.txt中写入自己的学号和姓名,读取TextRw.txt中信息并将其显示在屏幕上。
1.编写TextRw.java的Java应用程序,程序完成的功能是:首先向TextRw.txt中写入自己的学号和姓名,读取TextRw.txt中信息并将其显示在屏幕上. package Test03; ...
- 使用 python 实现 wc 命令程序的基本功能
这里使用了 python 的基本代码实现了 Linux 系统下 wc 命令程序的基本功能. #!/usr/bin/env python #encoding: utf-8 # Author: liwei ...
- 图像处理控件ImageGear for .NET教程如何为应用程序 添加DICOM功能(2)
在前面的一些关于图像处理控件ImageGear for .NET文章<图像处理控件ImageGear for .NET教程: 添加DICOM功能(1)>中讲解了如何对应用程序添加DICOM ...
- 系统设计 - IOS 程序插件及功能动态更新思路
所用框架及语言 IOS客户端-Wax(开发愤怒的小鸟的连接Lua 和 Objc的框架),Lua,Objc, 服务端-Java(用于返回插件页面) 由 于Lua脚本语言,不需要编译即可运行 ...
随机推荐
- CSS - clearfix清除浮动
首先,我们来解释一下为什么要使用 clearfix(清除浮动). 通常我们在写html+css的时候,如果一个父级元素内部的子元素是浮动的(float),那么常会发生父元素不能被子元素正常撑开的情况, ...
- Cache数据库新增用户并分配权限(Caché)
1.通过浏览器登录管理中心,Caché自带的客户端工具是网页的,访问地址: http://localhost:57772/csp/sys/UtilHome.csp 2.选择功能链接:系统管理- ...
- 解决mosh: Nothing received from server on UDP port 60001 环境: centos7.1
主要问题在于有的教程使用iptables命令来开启对应端口, 但是centos7.1中虽然iptables仍然存在, 但是没有默认安装相关服务, 而是使用firewalld来管理防火墙. 所以我开始以 ...
- java面试考点-HashTable/HashMap/ConcurrentHashMap
HashTable 内部数据结构是数组+链表,键值对不允许为null,线程安全,但是锁是整表锁,性能较差/效率低 HashMap 结构同HashTable,键值对允许为null,线程不安全, 默认初始 ...
- linux命令帮助 man bash
BASH(1) BASH(1) NAME bash - GNU Bourne-Again SHell (GNU 命令解释程序 “Bourne二世”) 概述(SYNOPSIS) bash [option ...
- php redis mysql apache 下载地址
Mysql:https://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.36-linux-glibc2.5-x86_64.tar.gz php:ht ...
- Velocity 数值格式化(NumberTool工具类):保留两位小数和格式化千分位、取整
Velocity 自带的工具类:NumberTool 实现数字格式化:保留两位小数和格式化千分位,以及取整. NumberTool 的 format(String format, Object obj ...
- 44.python排序算法(冒泡+选择)
一,冒泡排序: 是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个,如果他们的排序错误就把他们交换过来. 冒泡排序是稳定的(所谓稳定性就是两个相同的元素不会交换位置) 冒泡排序算法的运作如下 ...
- linux下jenkins的安装
构建伟大,无所不能 Jenkins是开源CI&CD软件领导者, 提供超过1000个插件来支持构建.部署.自动化, 满足任何项目的需要. 参考博客:https://www.cnblogs.com ...
- Philosopher’s Walk --DFS
题意: Philosopher’s Walk 图,告诉你step返回位置. 思路: 按四个块DFS #define IOS ios_base::sync_with_stdio(0); cin.tie( ...