[Paper Reading] Show and Tell: A Neural Image Caption Generator
论文链接:https://arxiv.org/pdf/1411.4555.pdf
代码链接:https://github.com/karpathy/neuraltalk & https://github.com/karpathy/neuraltalk2 & https://github.com/zsdonghao/Image-Captioning
主要贡献
在这篇文章中,作者借鉴了神经机器翻译(Neural Machine Translation)领域的方法,将“编码器-解码器(Encoder-Decoder)”模型引入了神经图像标注(Neural Image Captioning)领域,提出了一种端到端(end-to-end)的模型解决图像标注问题。下面展示了从论文中截取的两幅图片,第一幅图片是NIC模型的概述,第二幅图片描述了网络的细节。NIC网络采用卷积神经网络(CNN)作为编码器,长短期记忆网络(LSTM)作为解码器。
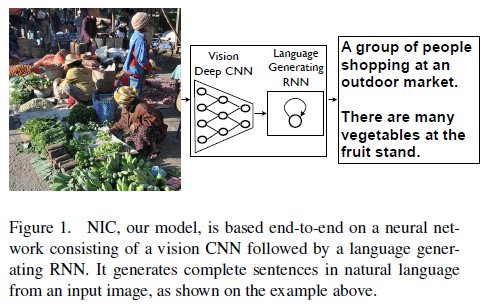

实验细节
- 在文章中,作者提出使用在图像分类任务(Image Classification Task)中预训练好的Inception v2作为编码器,将其最后一个隐藏层提取到的特征作为解码器隐藏层的初始状态。但是,在官方给出的源码neuraltalk中,作者使用了预训练好的VGG16作为了编码器,将Layer FC-4096提取到的特征作为了LSTM隐藏层的初始状态(详见neuraltalk/py_caffe_feat_extract.py line160)。在官方给出的源码neuraltalk2中,同样使用了VGG16作为编码器提取图像特征(详见neuraltalk2/train.lua line27)。在zsdonghao对该方法的TensorFlow实现中,使用了Inception v3作为编码器(详见zsdonghao/Image-Captioning/inception_v3(for TF 0.10).py)。
Hence, it is natural to use a CNN as an image “encoder”, by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences.
An “encoder” RNN reads the source sentence and transforms it into a rich fixed-length vector representation, which in turn in used as the initial hidden state of a “decoder” RNN that generates the target sentence.
- 在文章中,作者提出使用随机梯度下降(Stochastic Gradient Descent)训练网络。在官方给出的源码neuraltalk2中,作者给出了多种训练网络的优化器及其参数(rmsprop,adagrad,sgd……详见neuraltalk2/misc/optim_updates.lua)。zsdonghao/Image-Captioning使用SGD训练网络,初始学习率2.0,学习率衰减因子0.5,学习率下降后每一代的数量8.0。
It is a neural net which is fully trainable using stochastic gradient descent.
- 在文章中,作者提出按最大似然训练模型参数。在zsdonghao/Image-Captioning中,作者使用了tensorlayer.cost.cross_entropy_seq_with_mask()(详见zsdonghao/Image-Captioning/buildmodel.py line665)。
The model is trained to maximize the likelihood of the target description sentence given the training image.
- 在neuraltalk2中,LSTM层的输入(Embedding层的输出)向量维度和LSTM隐藏层的向量维度均设置为512。zsdonghao/Image-Captioning的设置相同。
- 在zsdonghao/Image-Captioning中,作者将vocabulary_size设置为12000。
版权声明:本文为博主原创文章,欢迎转载,转载请注明作者及原文出处!
[Paper Reading] Show and Tell: A Neural Image Caption Generator的更多相关文章
- Paper Reading - Show and Tell: A Neural Image Caption Generator ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1411.4555 Main Points: A generative model ( NIC, GoogLeNet ...
- Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )
Link of the Paper: https://arxiv.org/pdf/1502.03044.pdf Main Points: Encoder-Decoder Framework: Enco ...
- [Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
论文链接:https://arxiv.org/pdf/1502.03044.pdf 代码链接:https://github.com/kelvinxu/arctic-captions & htt ...
- [Paper Reading] Image Captioning using Deep Neural Architectures (arXiv: 1801.05568v1)
Main Contributions: A brief introduction about two different methods (retrieval based method and gen ...
- Paper Reading - Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge
Link of the Paper: https://arxiv.org/abs/1609.06647 A Correlative Paper: Show and Tell: A Neural Ima ...
- 论文:Show and Tell: A Neural Image Caption Generator-阅读总结
Show and Tell: A Neural Image Caption Generator-阅读总结 笔记不能简单的抄写文中的内容,得有自己的思考和理解. 一.基本信息 标题 作者 作者单位 发表 ...
- Paper Reading: Stereo DSO
开篇第一篇就写一个paper reading吧,用markdown+vim写东西切换中英文挺麻烦的,有些就偷懒都用英文写了. Stereo DSO: Large-Scale Direct Sparse ...
- Paper Reading - Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation ( CVPR 2015 )
Link of the Paper: https://ieeexplore.ieee.org/document/7298856/ A Correlative Paper: Learning a Rec ...
- Paper Reading - CNN+CNN: Convolutional Decoders for Image Captioning
Link of the Paper: https://arxiv.org/abs/1805.09019 Innovations: The authors propose a CNN + CNN fra ...
随机推荐
- python函数入参和返回值
以下内容参考自runoob网站,以总结python函数知识点,巩固基础知识,特此鸣谢! 原文地址:http://www.runoob.com/python3/python3-function.html ...
- Java8-Lambda-No.05
import java.util.HashMap; import java.util.function.BiConsumer; public class Lambda5 { //Pre-Defined ...
- C语言学习系列(四)C语言基本语法和数据类型
一.基本语法 C的令牌(Tokens) C 程序由各种令牌组成,令牌可以是关键字.标识符.常量.字符串值,或者是一个符号. 关键字(保留字) auto else long switch break e ...
- at/crontab
at yum -y install at systemctl start atd 增加任务 增加任务的第三行是 是ctrl+D 表示的是退出 第四行是系统提示任务执行的时间 任务查询 atq 任务删除 ...
- sz/rz
需要客户端的支持,CRT或者Xshell等 linux端默认是不支持的, 不用通过传输工具来传输文件 yum -y install lrzsz
- Java操作文件那点事
刚开始学Java时候,一直搞不懂Java里面的io关系,在网上找了很多大多都是给个结构图草草描述也看的不是很懂.而且没有结合到java7 的最新技术,所以自己结合API来整理一下,有错的话请指正,也希 ...
- [题解] [BZOJ4152] The Captain
题面 题解 将所有点根据
- jenkins的任务卡住
今天做jenkins任务的时候,发现一个启动后,一直卡住,在那转圈圈,其实这个时候,任务已经执行完了. 经过分析,因为这个任务是启动一个web服务,直接在机器上执行时,直接占用一个终端. 解决办法,放 ...
- Python实现进度条的效果
from itertools import cycle from time import sleep for frame in cycle(r'-\|/-\|/'): print('\r', fram ...
- 2018-2019-2 20165210《网络对抗技术》Exp9 Web安全基础
2018-2019-2 20165210<网络对抗技术>Exp9 Web安全基础 实验目的 本实践的目标理解常用网络攻击技术的基本原理. 实验内容 安装Webgoat SQL注入攻击 - ...