【生活现场】从打牌到map-reduce工作原理解析(转)
原文:http://www.sohu.com/a/287135829_818692

小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了。
对小史面试情况感兴趣的同学可以观看面试现场系列。

找到工作后的一小段时间是清闲的,小史把新租房收拾利索后,就开始找同学小赵,小李和小王来聚会了。
吃过午饭后,下午没事,四个人一起商量来打升级。打升级要两副扑克牌,小史就去找吕老师借牌去了。

【多几张牌】

吕老师给小史拿出一把牌。




【map-reduce】



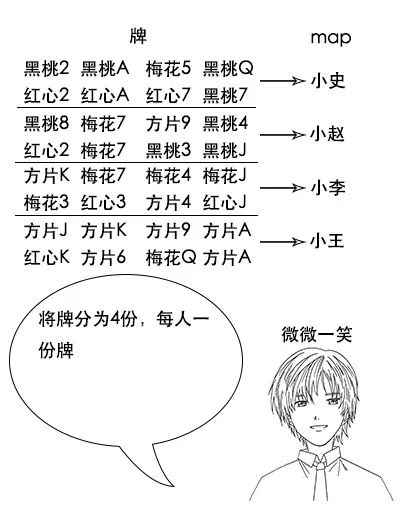













(注意,如果有两幅完整的牌,那么小赵手中的黑桃A一定不少于2张,因为其他人手中已经不可能有黑桃A了,图中的数据只是演示。)

【hadoop中的map-reduce】

吕老师:过程看上去很简单,但是要实现并不简单,要考虑很多异常情况,幸好开源项目hadoop已经帮我们实现了这个模型,我们用它很简单就能实现map-reduce。



吕老师:hadoop是一个分布式计算平台,我们只要开发map-reduce的作业(job),然后提交到hadoop平台,它就会帮我们跑这个map-reduce的作业啦。


map阶段:
publicstaticclassMyMapperextendsMapper<LongWritable, Text, Text, LongWritable> {
protectedvoidmap(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)throwsjava.io.IOException, InterruptedException {
String card = value.toString();
context.write( newText(card), newLongWritable( 1L));
};
}
(友情提示:可左右滑动)

吕老师:申明不用看,主要看map方法,它有三个参数,key、value和context,逻辑也很简单,其实就是用context.write往下游写了一个(card,1)的映射关系。
reduce阶段:
publicstaticclassMyReducerextendsReducer<Text, LongWritable, Text, LongWritable> {
protectedvoidreduce(Text key, java.lang.Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context)throwsjava.io.IOException, InterruptedException {
longcount = 0L;
for(LongWritable value : values) {
count += value.get();
}
context.write(key, newLongWritable(count));
};
}
(友情提示:可左右滑动)

吕老师:reduce也很简单,方法中三个参数,key、values和context,因为到了reduce阶段,一个key可能有多个value,所以这里传进来的是values,函数逻辑其实就是简单地将values累加,然后通过context.write输出。

小史:我明白了,hadoop其实把map-reduce的流程已经固定下来并且实现了,只留给我们自定义map和自定义reduce的接口,而这两部分恰好是和业务强相关的。

小史:也就是说业务方只需要告诉hadoop怎么进行map和怎么进行reduce,hadoop就能帮我们跑map-reduce的计算任务啦。
【分区函数】


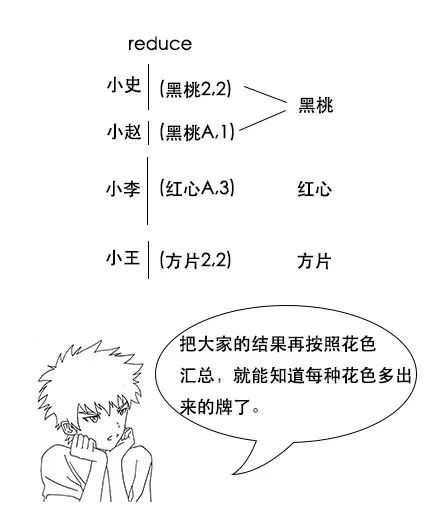



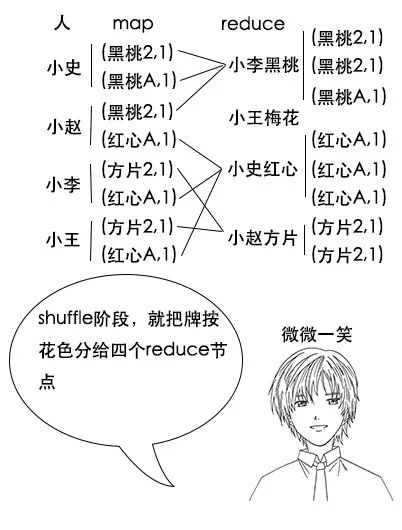

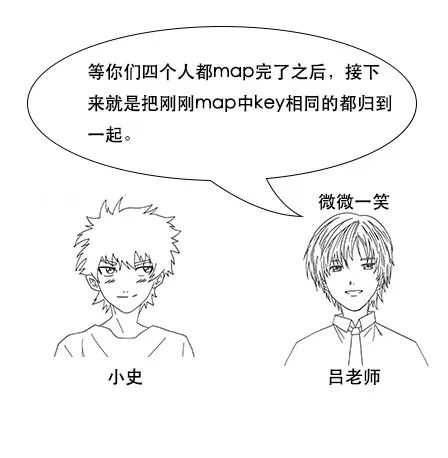
小史:我明白了,这样一来,最后reduce完成之后,我这边多出来的牌全是红心的,其他人多出来的牌也算是同一花色,就不用进行二次统计了,这真是个好办法。

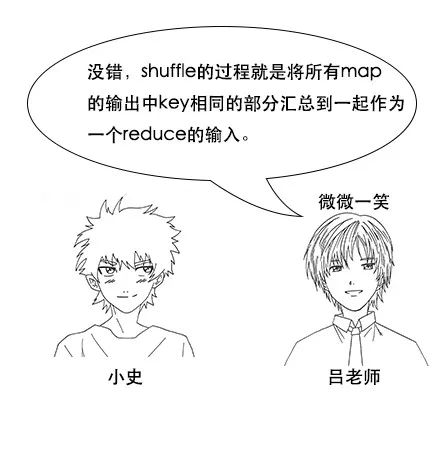
吕老师:没错,这就是分区函数的作用,在hadoop中,虽然shuffle阶段有默认规则,但是我们可以自定义分区函数来改变这个规则,让它更加适合我们的业务。
【合并函数】





吕老师:如果你不合并,那么传给shuffle阶段的就有两个数据,如果你预合并了,那么传给shuffle阶段的就只有一个数据,这样数据量减少了一半。





吕老师:hadoop当然考虑到了这个点,你可以自定义一个合并函数,hadoop在map阶段会调用它对本地数据进行预合并。

【hadoop帮我们做的事情】







吕老师:还有呀,刚才说的分布式系统中网络传输是有成本的,hadoop会帮我们把数据送到最近的节点,尽量减少网络传输。




吕老师:hadoop有两大重大贡献,一个是刚刚讲的map-reduce,另一个是分布式文件系统hdfs,hdfs可以说是分布式存储系统的基石。其实一般来说,map-reduce任务的输入,也就是那个很大的数据文件,一般都是存在hdfs上的。

【笔记】
小史在往回走的路上,在手机里记录下了这次的笔记。
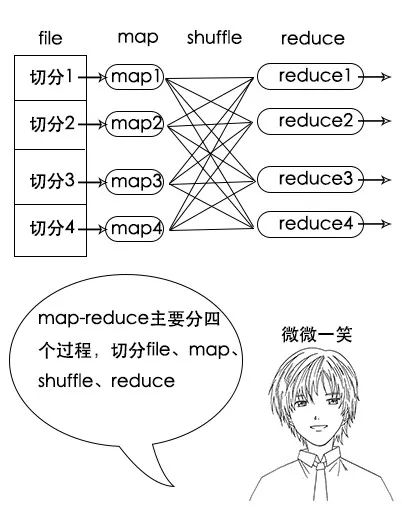
一、map-reduce的四个关键阶段:file切分、map阶段、shuffle阶段、reduce阶段。
二、hadoop帮我们做了大部分工作,我们只需自定义map和reduce阶段。
三、可以通过自定义分区函数和合并函数控制map-reduce过程的细节。
四、hadoop还有一个叫hdfs的牛逼东西,下次问问吕老师。
【回到房间】
生活现场是互联网侦察推出的现场系列中的另一个板块,旨在通过生活中的场景,来解释大数据微服务技术中的基本原理,希望对大家学习技术原理有所帮助。
【生活现场】从打牌到map-reduce工作原理解析(转)的更多相关文章
- jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一)
jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一) 线程池介绍 在日常开发中经常会遇到需要使用其它线程将大量任务异步处理的场景(异步化以及提升系统的吞吐量),而在 ...
- Map/Reduce 工作机制分析 --- 数据的流向分析
前言 在MapReduce程序中,待处理的数据最开始是放在HDFS上的,这点无异议. 接下来,数据被会被送往一个个Map节点中去,这也无异议. 下面问题来了:数据在被Map节点处理完后,再何去何从呢? ...
- 第十篇:Map/Reduce 工作机制分析 - 数据的流向分析
前言 在MapReduce程序中,待处理的数据最开始是放在HDFS上的,这点无异议. 接下来,数据被会被送往一个个Map节点中去,这也无异议. 下面问题来了:数据在被Map节点处理完后,再何去何从呢? ...
- Map/Reduce 工作机制分析 --- 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- 第九篇:Map/Reduce 工作机制分析 - 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- Servlet 工作原理解析
转自:http://www.ibm.com/developerworks/cn/java/j-lo-servlet/ Web 技术成为当今主流的互联网 Web 应用技术之一,而 Servlet 是 J ...
- [转]Servlet 工作原理解析
Web 技术成为当今主流的互联网 Web 应用技术之一,而 Servlet 是 Java Web 技术的核心基础.因而掌握 Servlet 的工作原理是成为一名合格的 Java Web 技术开发人员的 ...
- Servlet 工作原理解析--转载
原文:http://www.ibm.com/developerworks/cn/java/j-lo-servlet/index.html?ca=drs- Web 技术成为当今主流的互联网 Web 应用 ...
- 【Java】Servlet 工作原理解析
Web 技术成为当今主流的互联网 Web 应用技术之一,而 Servlet 是 Java Web 技术的核心基础.因而掌握 Servlet 的工作原理是成为一名合格的 Java Web 技术开发人员的 ...
随机推荐
- WebService 创建、发布、调用
环境Win7+VS2017 启用IIS 查看iis是否启用 新建 ASP.NET Web 应用程序 项目,项目中添加Web 服务 在 asmx 文件中添加需要的方法 运行结果 发布 创建新的文件夹, ...
- 关于项目中js原型的使用
在一个项目中为了减少全局变量的使用及模块化的开发我们使用的构造函数加原型的开发模式 var App = function(){ //管理构造函数的属性 this.name = 'jack' } //页 ...
- python3装饰器
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数. >>> def now(): ... print('2015-3-25') ... >> ...
- 汇编指令之ADC、SBB、XCHG、MOVS指令
版权声明:本文为博主原创文章,转载请附上原文出处链接和本声明.2019-08-25,23:52:49作者By-----溺心与沉浮----博客园 介绍完这些基础指令,后面就讲到汇编JCC指令了,我觉得介 ...
- 阿里云部署SSL证书
查找中间证书 为了确保兼容到所有浏览器,我们必须在阿里云上部署中间证书,如果不部署证书,虽然安装过程可以完全也不会报错,但可能导致Android系统,Chrome 和 Firefox等浏览器无法识别. ...
- odoo10学习笔记十二:web controller
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/11189332.html 一:路由 odoo.http.route(route=None, **kw) 装饰器 ...
- SQLAlchemy 多对多
创建多对多表 from sqlalchemy.ext.declarative import declarative_base Base=declarative_base() from sqlalche ...
- JS高阶---对象
四个问题 问题拓展:对象访问方式 1.属性名包含特殊字符,例如空格.-等 2.变量名不确定 变量名不确定时需要使用['属性名'] .
- 201871010135 张玉晶《面向对象程序设计(java)》第十五周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/zyja/p/12000 ...
- JVM-卡表(Card Table)
简介 现代JVM,堆空间通常被划分为新生代和老年代.由于新生代的垃圾收集通常很频繁,如果老年代对象引用了新生代的对象,那么,需要跟踪从老年代到新生代的所有引用,从而避免每次YGC时扫描整个老年代,减少 ...