第十篇:Map/Reduce 工作机制分析 - 数据的流向分析
前言
在MapReduce程序中,待处理的数据最开始是放在HDFS上的,这点无异议。
接下来,数据被会被送往一个个Map节点中去,这也无异议。
下面问题来了:数据在被Map节点处理完后,再何去何从呢?
这就是本文探讨的话题。
Shuffle
在Map进行完计算后,将会让数据经过一个名为Shuffle的过程交给Reduce节点;
然后Reduce节点在收到了数据并完成了自己的计算后,会将结果输出到Hdfs。
那么,什么是Shuffle阶段,它具体做什么事情?
需要知道,这可是Hadoop最为核心的所在,也是号称“奇迹出现的地方“ = =#
Shuffle具体分析
首先,给出官方对于Shuffle流程的示意图:
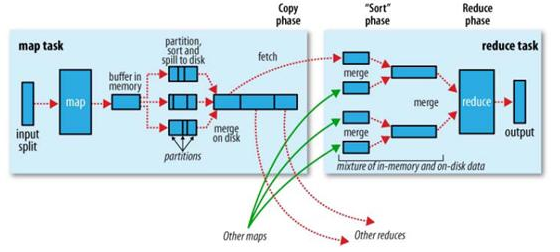
Shuffle过程植入于Map端和Reduce端两边
1. Map端工作:
a. 分区:根据键值对的Key值,选定键值对所属的Partition区间(与Reduce节点对应)。
b. 排序:对各分区内的键值对根据键进行排序。
c. 分割:Map端的结果先是存放在缓冲区内的,如果超出,自然就要执行分割的处理,将一部分数据发往硬盘。
d. 合并:对于要发送往同一个节点的键值对,我们需要对它进行合并。(这一步很可能针对硬盘,对于海量数据处理,缓冲区溢出是很正常的事情)
2. Reduce端工作:
a. Copy:以HTTP的方式从指定的Map端拉数据,注意是Map端的本地磁盘。
b. 合并:一个Reduce节点有可能从多个Map节点获取数据,获取到之后
c. 排序:对各分区内的键值对根据键进行排序。和Map端操作一样。
小结
对于这部分的内容,以后有机会做Hadoop性能方面的工作时,会继续学习研究。
第十篇:Map/Reduce 工作机制分析 - 数据的流向分析的更多相关文章
- 第九篇:Map/Reduce 工作机制分析 - 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- Map/Reduce 工作机制分析 --- 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- Map/Reduce 工作机制分析 --- 数据的流向分析
前言 在MapReduce程序中,待处理的数据最开始是放在HDFS上的,这点无异议. 接下来,数据被会被送往一个个Map节点中去,这也无异议. 下面问题来了:数据在被Map节点处理完后,再何去何从呢? ...
- 第十一篇:Map/Reduce 工作机制分析 - 错误处理机制
前言 对于Hadoop集群来说,节点损坏是非常常见的现象. 而Hadoop一个很大的特点就是某个节点的损坏,不会影响到整个分布式任务的运行. 下面就来分析Hadoop平台是如何做到的. 硬件故障 硬件 ...
- Map/Reduce 工作机制分析 --- 错误处理机制
前言 对于Hadoop集群来说,节点损坏是非常常见的现象. 而Hadoop一个很大的特点就是某个节点的损坏,不会影响到整个分布式任务的运行. 下面就来分析Hadoop平台是如何做到的. 硬件故障 硬件 ...
- 机器学习等知识--- map/reduce, python 读json数据。。。
map/ reduce 了解: 简单介绍map/reduce 模式: http://www.csdn.net/article/2013-01-07/2813477-confused-about-map ...
- 第十篇 scrapy item loader机制
在我们执行scrapy爬取字段中,会有大量的和下面的代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制 def parse_detail(sel ...
- 2014年2月5日 Oracle ORACLE的工作机制[转]
网上看到一篇描写ORACLE工作机制的文章,觉得很不错!特摘录了下来. ORACLE的工作机制-1 (by xyf_tck) 我们从一个用户请求开始讲,ORACLE的简要的工作机制是怎样的,首 ...
- DataNode的工作机制
DataNode的工作机制 一个数据块在DataNode以文件的形式在磁盘上保存,分为两个文件,一个是数据本身, 一个是元数据信息(包括数据的长度,校验和,时间戳) 1.DataNode启动后,向Na ...
随机推荐
- 链表回文判断(C++)
题目描述: 对于一个链表,请设计一个时间复杂度为O(n),额外空间复杂度为O(1)的算法,判断其是否为回文结构. 给定一个链表的头指针A,请返回一个bool值,代表其是否为回文结构.保证链表长度小于等 ...
- PHP实现session对象封装
<?php class Session { private $db; // 设置数据库变量 private $expiry = 3600; // 设置Session失效时间 public fun ...
- 关于ruby -gem无法切换淘宝源
ruby官网提供的 淘宝的gem源 不起作用 https://ruby.taobao.org/ taobao Gems 源已停止维护,现由 ruby-china 提供镜像服务 http://gems. ...
- Linux一些常用操作
1.linux swap分区 可采用文件的方式 dd if=/dev/zero of=/var/swap bs=1024 count=2048000 mkswap /var/swap swapon / ...
- ADO.NET通用类库
using System.Data; using System.Data.SqlClient; namespace DataService { public class SQLHelper { pub ...
- Java注释用处
1.Java注释: import cn.lonecloud.Doc; /** * Created by lonecloud on 2017/8/17. * 测试注释类型 {@link Doc#test ...
- C. Vasya and String
原题链接 C. Vasya and String High school student Vasya got a string of length n as a birthday present. T ...
- ClientURL库-curl_setopt()
这是一个出现得比较突兀的问题: 好好学习使用一下这个库:http://php.net/manual/zh/book.curl.php curl_setopt函数:curl_setopt - 设置一个c ...
- mysql常用脚本及命令记录
mysql导出用户权限 mysql中直接通过授权即可使用对应用户,不必使用创建用户命令(如CREATE USER 'xxx'@'%' IDENTIFIED BY 'XXX';)先建用户再授权. 方法一 ...
- Hadoop压缩
为什幺要压缩? 压缩会提高计算速度?这是因为mapreduce计算会将数据文件分散拷贝到所有datanode上,压缩可以减少数据浪费在带宽上的时间,当这些时间大于压缩/解压缩本身的时间时,计算速度就会 ...