基于webmagic的种子网站爬取
1. 概述
因为无聊,闲来没事做,故突发奇想,爬个种子,顺便学习爬虫。本文将介绍使用Spring/Mybatis/webmagic等框架构建项目并爬取种子磁链。
2. 项目搭建
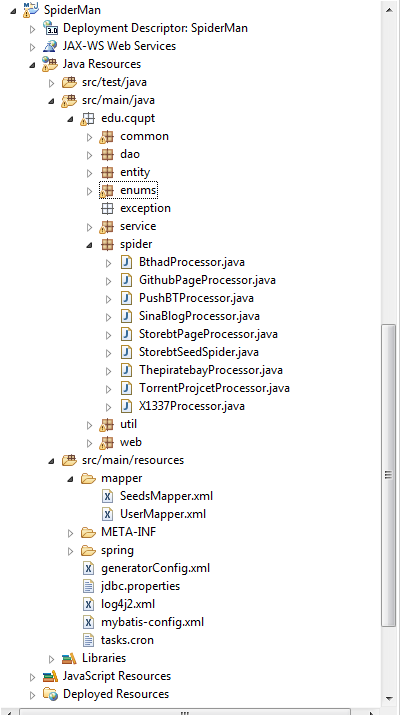
如下图为本项目的工程结构,主要代码实现在Spider包中。
3. 数据库设计
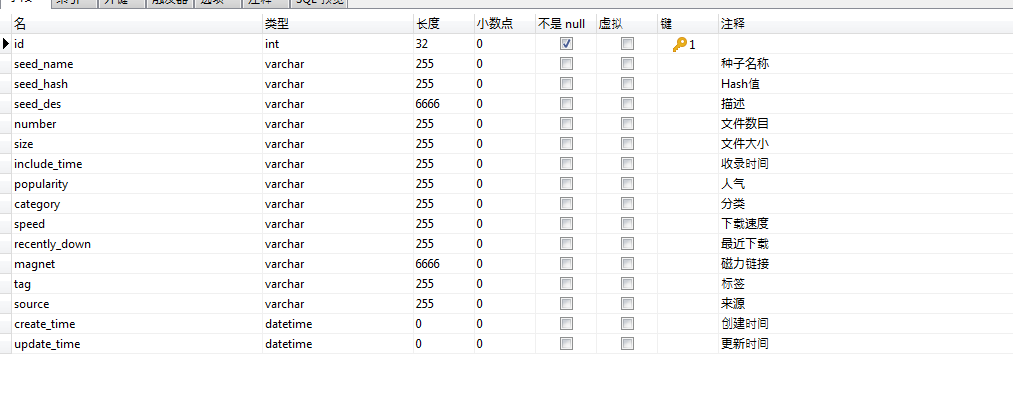
参考众多的种子网站,找到描述种子的常用属性,如下:
4. 程序实现
1. 爬虫配置
在抓取种子之前,首先要确定所要抓取的网站地址、编码、抓取时间间隔、重试次数等信息,如下:
//设置网站源
private static String netSite="PushBT";
private Site site = Site.me().setDomain("http://www.pushbt.com")
.setCharset("UTF-8").setSleepTime(1000)//编码
.setRetryTimes(3);//重试次数
private static String BASE_URL="http://www.pushbt.com";
2. 逻辑编写
process方法是爬虫的核心接口,所有的属性抽取都在此方法中实现
@Override
public void process(Page page) {
//定义如何抽取页面信息,并保存下来
List<String> links = page.getHtml().xpath("//table[@class='items']//tr[@class='odd']/td[2]/a/@href").all();
//将需要待爬的网页地址都存下来,以待后续从中取出
targetUrlList=StringUtil.linkURL(BASE_URL, links);
page.addTargetRequests(targetUrlList);
Seeds seed = new Seeds();
// 获取名称
String name = page.getHtml().xpath("//ul[@id='filelist']//li/span/@title").toString();
if (name==null||"".equals(name)||service.isExistByName(name)) {//名称为空,则跳过;已存在(true),则跳过
page.setSkip(true);
count++;
LOG.info("skip the "+count+" ,title : "+name);
return;
}
page.putField("name", name);
seed.setSeedName(name);
// 获取hash值(无hash值,默认为null)
// String hash = page.getHtml().xpath("//p[@class='dd desc']//b[2]/text()").toString();
page.putField("hash", null);
seed.setSeedHash(null);
// 描述(没有描述信息,则默认为名称)
// String desc = page.getHtml().xpath("//div[@class='dd filelist']/p/text()").toString();
page.putField("desc", name);
seed.setSeedDes(name);
// 文件个数
String number = page.getHtml().xpath("//ul[@class='params-cover']/li[4]/div[@class='value']/text()").toString();
page.putField("number", number);
seed.setNumber(number);
// 文件大小
String size = page.getHtml().xpath("//ul[@class='params-cover']/li[5]/div[@class='value']/text()").toString();
page.putField("size", size);
seed.setSize(size);
// 获取收录时间
String includeDate = page.getHtml().xpath("//ul[@class='params-cover']/li[2]/div[@class='value']/text()").toString();
page.putField("includeDate", includeDate);
seed.setIncludeTime(includeDate);
//最近下载时间
String recentlyDown = page.getHtml().xpath("//ul[@class='params-cover']/li[3]/div[@class='value']/text()").toString();
page.putField("recentlyDown", recentlyDown);
seed.setRecentlyDown(recentlyDown);
// 人气
String popularity = page.getHtml().xpath("//ul[@class='params-cover']/li[6]/div[@class='value']/text()").toString();
page.putField("popularity", popularity);
seed.setPopularity(popularity);
// 下载速度
// String speed = page.getHtml().xpath("//p[@class='dd desc']//b[7]/text()").toString();
page.putField("speed", SpiderUtil.getSpeed(popularity));
seed.setSpeed(SpiderUtil.getSpeed(popularity));
// 获取磁力链接
String magnet = page.getHtml().xpath("//ul[@class='params-cover']/li[9]/div[@class='value']/a/@href").toString();
page.putField("magnet", magnet);
seed.setMagnet(magnet);
// 标签(在详情页面没有tag,暂时以热门搜索为tag)
List<String> tags = page.getHtml().xpath("//div[@class='block oh']/a/span/text()").all();
page.putField("tags", tags);
seed.setTag(tags.toString());
seed.setCreateTime(new Date());
seed.setUpdateTime(new Date());
seed.setSource(netSite);
seed.setCategory("movies");
//保存到数据库
service.insert(seed);
}
3. 其它部分编写
例子用到的其他部分代码,如MVC,数据库操作等,不是本章节的重点,所以不一一介绍了
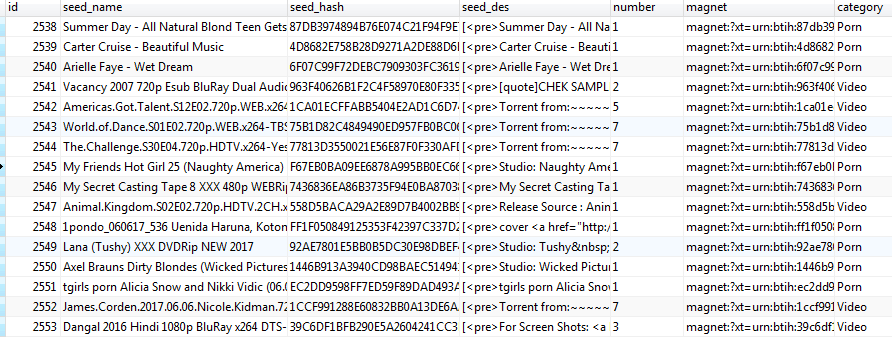
5. 成果展示
基于webmagic的种子网站爬取
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权
基于webmagic的种子网站爬取的更多相关文章
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- 5分钟掌握智联招聘网站爬取并保存到MongoDB数据库
前言 本次主题分两篇文章来介绍: 一.数据采集 二.数据分析 第一篇先来介绍数据采集,即用python爬取网站数据. 1 运行环境和python库 先说下运行环境: python3.5 windows ...
- 基于scrapy框架输入关键字爬取有关贴吧帖子
基于scrapy框架输入关键字爬取有关贴吧帖子 站点分析 首先进入一个贴吧,要想达到输入关键词爬取爬取指定贴吧,必然需要利用搜索引擎 点进看到有四种搜索方式,分别试一次,观察url变化 我们得知: 搜 ...
- 基于CrawlSpider全栈数据爬取
CrawlSpider就是爬虫类Spider的一个子类 使用流程 创建一个基于CrawlSpider的一个爬虫文件 :scrapy genspider -t crawl spider_name www ...
- Java爬虫_资源网站爬取实战
对 http://bestcbooks.com/ 这个网站的书籍进行爬取 (爬取资源分享在结尾) 下面是通过一个URL获得其对应网页源码的方法 传入一个 url 返回其源码 (获得源码后,对源码进 ...
- requests模块session处理cookie 与基于线程池的数据爬取
引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如: #!/usr/bin/ ...
- scrapy框架基于CrawlSpider的全站数据爬取
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- 【Python3 爬虫】06_robots.txt查看网站爬取限制情况
大多数网站都会定义robots.txt文件来限制爬虫爬去信息,我们在爬去网站之前可以使用robots.txt来查看的相关限制信息 例如: 我们以[CSDN博客]的限制信息为例子 在浏览器输入:http ...
- 网站爬取-案例一:猫眼电影TOP100
今天有小朋友说想看一下猫眼TOP100的爬取数据,要TOP100的名单,让我给发过去,其实很简单,先来看下目标网站: 建议大家都用谷歌浏览器: 这是我们要抓取的内容,100个数据,很少 我们看一下页面 ...
随机推荐
- xen save/restore 过程
以下分析基于 xen4.2.3, 虚拟机都是hvm模式 使用libxl库有两种方式启动一个虚拟机,一种是 xl create xx.conf , 这种方式从一个配置文件开始启动一个虚拟机,速度相对较慢 ...
- UBI 文件系统移植 sys 设备信息【转】
转自:http://blog.chinaunix.net/uid-25304914-id-3058647.html cat /sys/class/misc/ubi_ctrl/dev --------- ...
- yii上传图片、yii上传文件、yii控件activeFileField使用
yii框架提供了activeFileField控件来完成上传文件(当然也包括了上传图片)的操作,下面介绍yii的activeFileField使用方法.1.函数原型:public static str ...
- UVALive 6451:Tables(模拟 Grade D)
VJ题目链接 题意:模拟输出表格 思路:模拟……很暴力 代码: #include <cstdio> #include <cstring> #include <cstdli ...
- C#读取JSON字符串
下面这个是一段JSON字符串宏观图 下面我们通过C#读取JSON字符串里的任何一个数值 string jsonString="上面JSON字符串"; //需要引用Newtonsof ...
- [BZOJ1193][HNOI2006]马步距离 大范围贪心小范围爆搜
1193: [HNOI2006]马步距离 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1988 Solved: 905[Submit][Statu ...
- UVA 1347 Tour 【双调旅行商/DP】
John Doe, a skilled pilot, enjoys traveling. While on vacation, he rents a small plane and starts vi ...
- schema get_ddl
select dbms_metadata.get_ddl('INDEX','INDEX_CC_TAXID','CACS9DBSIT1') from dual; select dbms_metadata ...
- objective-c 强弱引用、properties的学习
一.强弱引用 强引用:strong reference 弱引用:weak reference 引用可以理解为指针A指向的对象B.换句话说,拥有指针A的对象是对象B的所有者(ownership). 区别 ...
- Windows路由表配置:双网卡路由分流
一.windows 路由表解释 route print - ====================================================================== ...